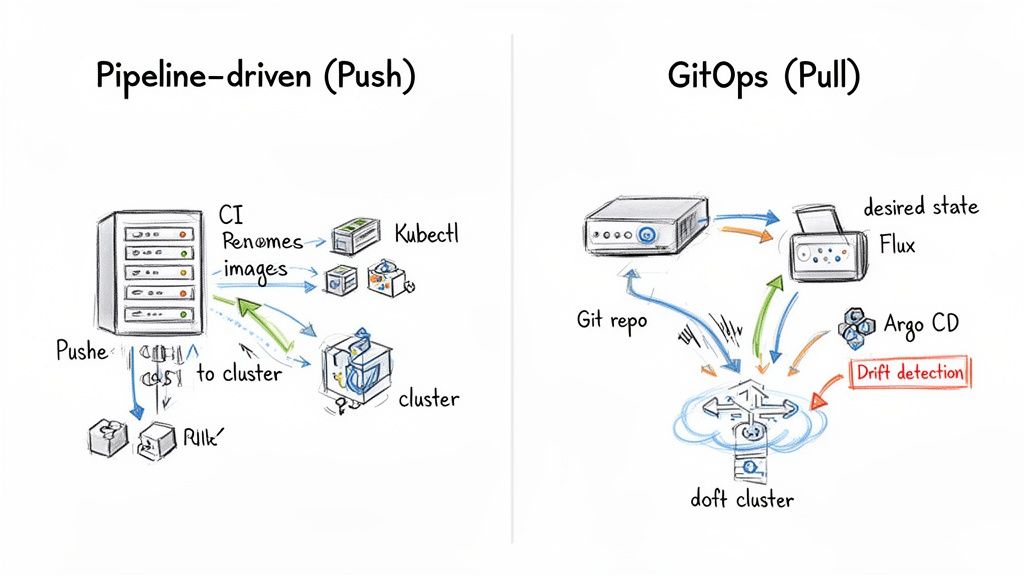
A cloud migration service provider is a third-party engineering firm specializing in the architectural design and execution of moving a company's digital assets—applications, data, and infrastructure—from on-premises data centers or another cloud to a target cloud environment. An elite provider functions as a strategic technical partner, guiding you through complex architectural trade-offs, executing the migration with precision, and ensuring your team is equipped to operate the new environment effectively.
Defining Your Technical Blueprint Before You Search
Before initiating contact with any cloud migration provider, the foundational work must be internal. A successful migration is architected on a granular self-assessment, not a vendor's sales presentation. Engaging vendors without this internal technical blueprint is akin to requesting a construction bid without architectural plans or a land survey—it leads to ambiguous proposals, scope creep, and budget overruns.
This blueprint is your primary vetting instrument. It compels potential partners to respond to your specific technical and operational reality, forcing them beyond generic, templated proposals. The objective is to produce a detailed document that specifies not just your current state but your target state architecture and operational model.
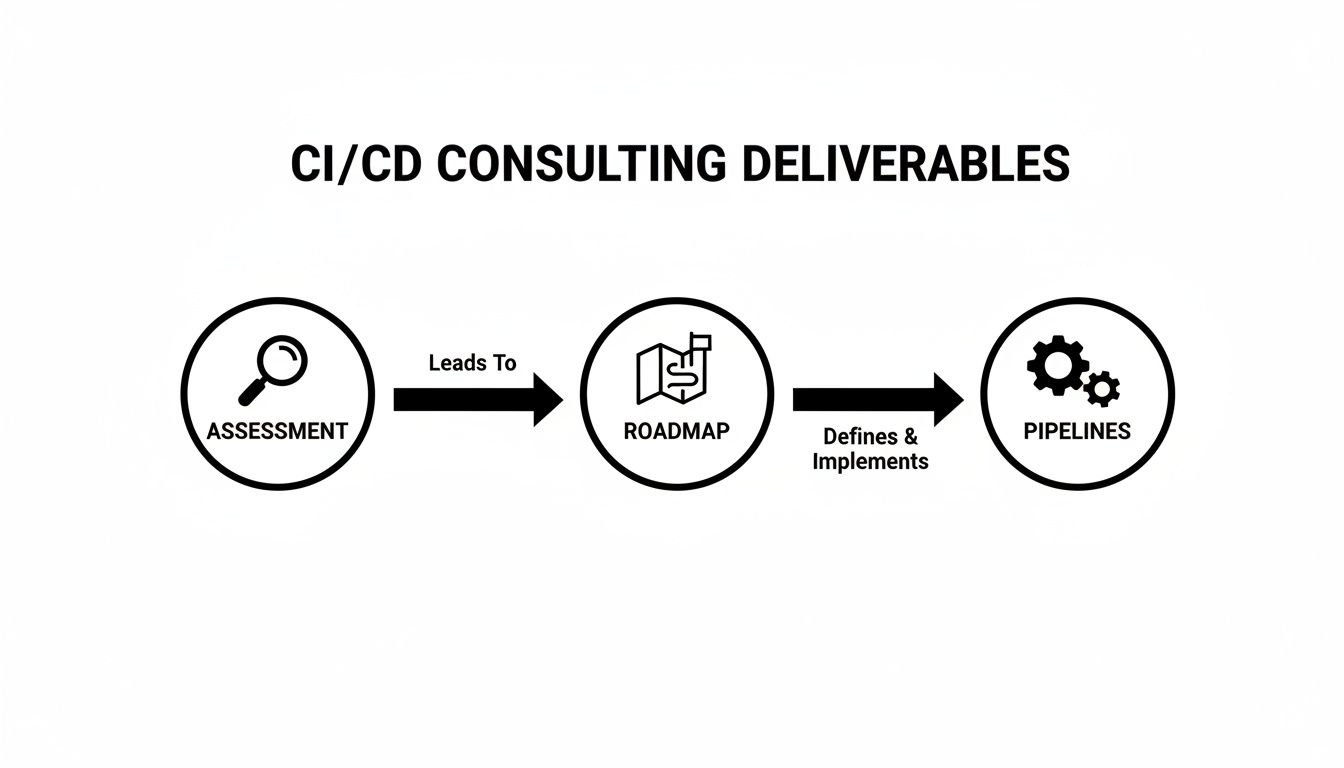
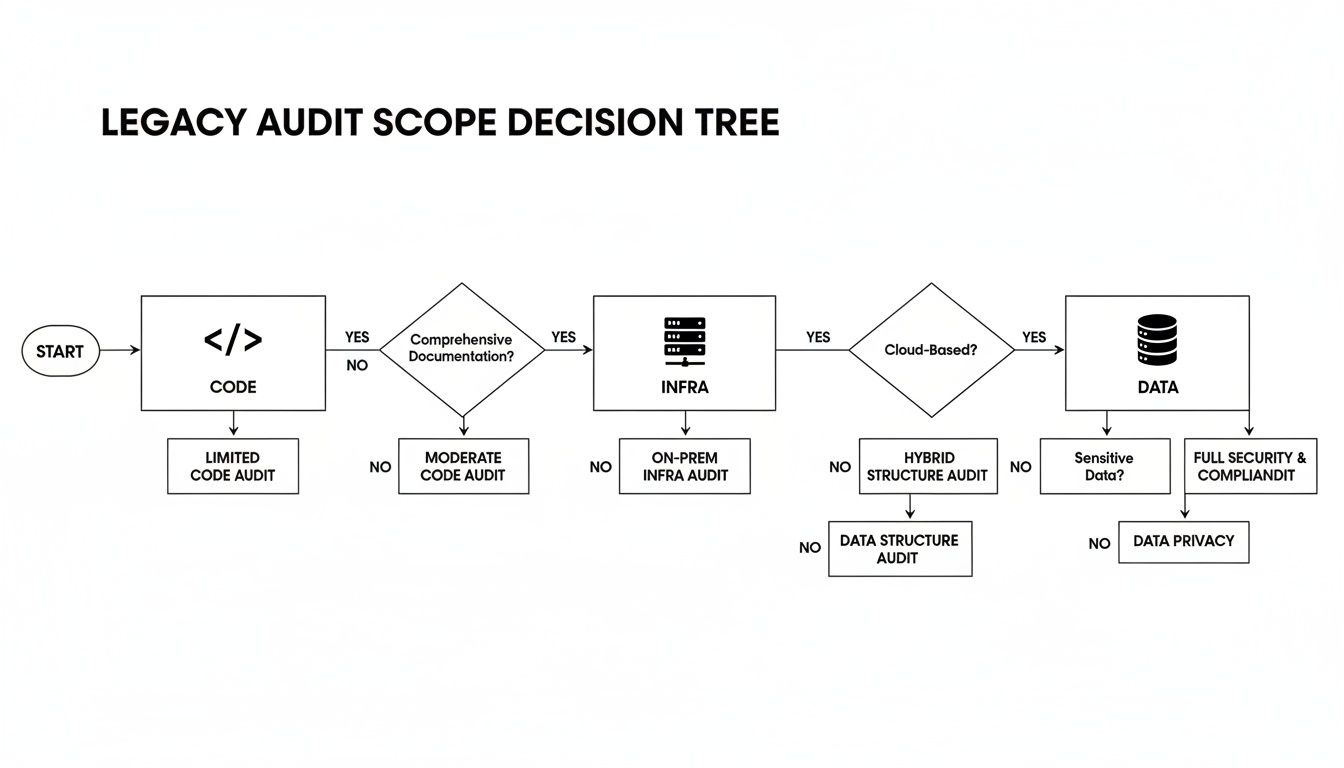
The diagram below outlines the sequential process for creating this technical blueprint.
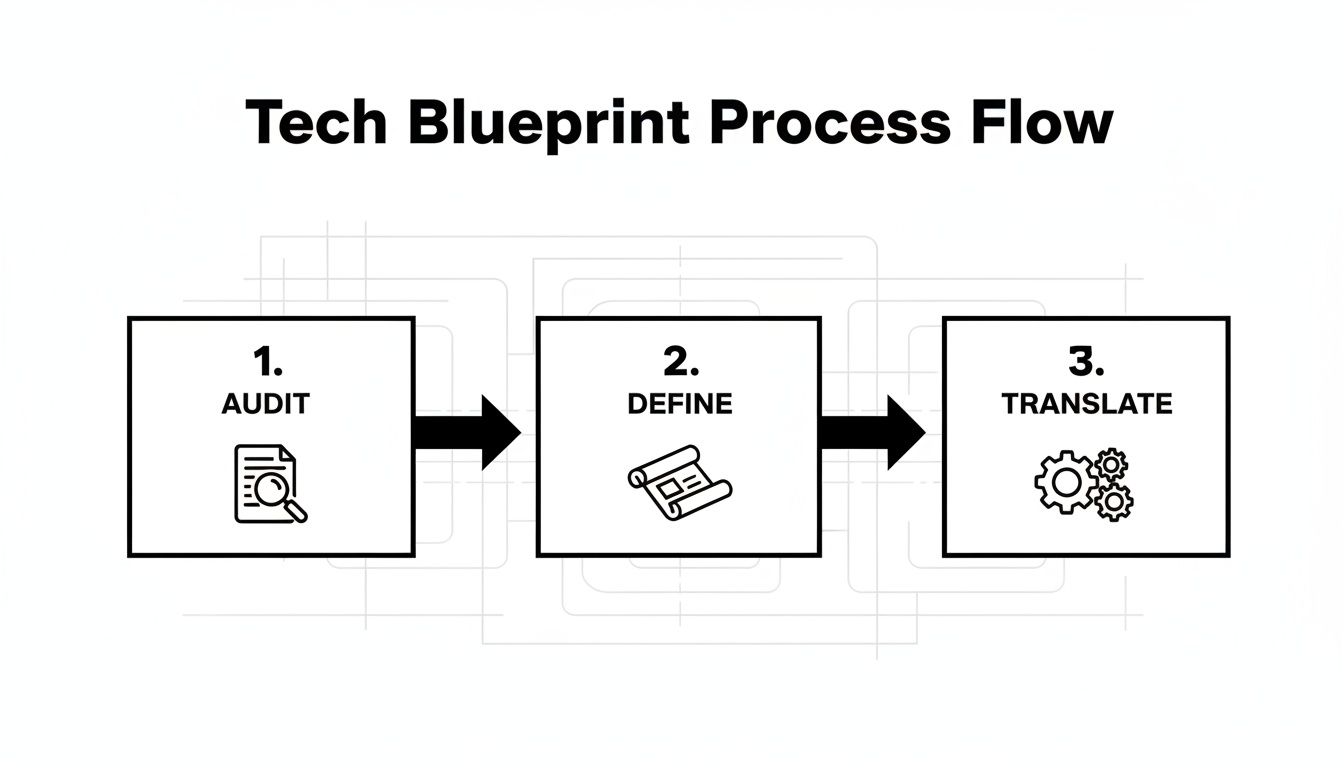
This sequence is non-negotiable: execute a comprehensive audit, define a precise target state, and then translate business objectives into quantifiable technical requirements.
Auditing Your Current Environment
Begin with a comprehensive technical audit of your existing infrastructure, applications, and network topology. This is not a simple inventory count; it's a deep-dive analysis of the interdependencies, performance characteristics, and security posture of your current systems.
Your audit must meticulously document:
- Application Portfolio Analysis: Catalog every application. Document its business criticality (Tier 1, 2, 3), architecture (monolithic, n-tier, microservices), and underlying technology stack (e.g., Java 8 with Spring Boot, Node.js 16, Python 3.9, .NET Framework 4.8). Specify database dependencies (e.g., Oracle 12c, PostgreSQL 11, MS SQL Server 2016).
- Dependency Mapping: Utilize automated discovery tools (e.g., AWS Application Discovery Service, Azure Migrate, or third-party tools like Device42) to map network communication paths and visualize dependencies between applications, databases, and external services. A failed migration often stems from an undiscovered dependency—a legacy authentication service or an overlooked batch job.
- Infrastructure Inventory: Document server specifications (CPU cores, RAM, OS version), storage types and performance (SAN IOPS, NAS throughput), network configurations (VLANs, firewall rules, load balancers), and current utilization metrics (CPU, memory, I/O, network bandwidth at P95 and P99). This data is critical for right-sizing cloud instances and avoiding performance bottlenecks or excessive costs.
- Security and Compliance Posture: Enumerate all current security tools (firewalls, WAFs, IDS/IPS), access control mechanisms (LDAP, Active Directory), and regulatory frameworks you are subject to (e.g., GDPR, HIPAA, PCI-DSS, SOX). These requirements must be designed into the target cloud architecture from the outset.
A thorough internal assessment is the prerequisite for understanding your current state and defining the success criteria for your migration.
Pre-Migration Internal Assessment Checklist
| Assessment Area | Key Questions to Answer | Success Metric Example |
|---|---|---|
| Application Inventory | Which apps are mission-critical? Which can be retired? What are their API and database dependencies? | 95% of Tier-1 applications successfully migrated with zero unplanned downtime during the cutover window. |
| Infrastructure & Performance | What are our current P95 CPU, memory, and storage IOPS utilization? Where are the performance bottlenecks under load? | Reduce average API endpoint response time from 450ms to sub-200ms post-migration. |
| Security & Compliance | What are our data residency requirements (e.g., GDPR)? What specific controls are needed for HIPAA or PCI-DSS? | Achieve a clean audit report against all required compliance frameworks within 90 days of migration. |
| Cost & TCO | What is our current total cost of ownership (TCO), including hardware refresh cycles, power, and personnel? | Reduce infrastructure TCO by 15% within the first 12 months, verified by cost allocation reports. |
| Skills & Team Readiness | Does our team possess hands-on expertise with IaC (Terraform), container orchestration (Kubernetes), and cloud-native monitoring? | Internal team can independently manage 80% of routine operational tasks (e.g., deployments, scaling events) within 6 months. |
This checklist serves as a starting point for constructing the detailed blueprint a potential partner must analyze to provide an intelligent proposal.
Translating Business Goals into Technical Objectives
With a complete audit, you can translate high-level business goals into specific, measurable, achievable, relevant, and time-bound (SMART) technical objectives. A goal like "reduce costs" is unactionable for an engineering team.
Here is a practical breakdown:
- Business Goal: Improve application performance and user experience.
- Technical Objective: Achieve a P95 response time of sub-200ms for key API endpoints (
/api/v1/users,/api/v1/orders). This will be accomplished by refactoring the monolithic application into discrete microservices deployed on a managed Kubernetes cluster (e.g., EKS, GKE, AKS) with auto-scaling enabled.
- Technical Objective: Achieve a P95 response time of sub-200ms for key API endpoints (
- Business Goal: Increase development agility and deployment frequency from monthly to weekly.
- Technical Objective: Implement a complete CI/CD pipeline using Jenkins or GitLab CI, leveraging Terraform for Infrastructure as Code (IaC) to enable automated, idempotent deployments to staging and production environments upon successful merge to the main branch.
- Business Goal: Cut infrastructure operational overhead by 30%.
- Technical Objective: Adopt a serverless-first architecture for all new event-driven services using AWS Lambda or Azure Functions, eliminating server provisioning and management for these workloads.
This translation process converts business strategy into an executable engineering plan. Presenting these specific objectives ensures a substantive, technical dialogue with a potential cloud migration service provider.
For assistance in defining these targets, a dedicated cloud migration consultation can refine your strategy before you engage a full-service provider. It is also crucial to fully comprehend what cloud migration entails for your specific business context to set realistic expectations.
Crafting an RFP That Exposes True Expertise
A generic Request for Proposal (RFP) elicits generic, boilerplate responses. To identify a true technical partner, your RFP must act as a rigorous technical filter—one that forces a cloud migration service provider to demonstrate its engineering depth, not its marketing prowess.
Think of it as providing a detailed schematic and asking how a contractor would execute the build, rather than just asking if they can build a house. A well-architected RFP is your most critical vetting instrument.
Articulating Your Technical Landscape
Your RFP must provide a precise, unambiguous snapshot of your current state and target architecture. Ambiguity invites assumptions, which are precursors to scope creep and budget overruns.
Be specific about your current technology stack. Do not just state "databases"; specify "a sharded MySQL 5.7 cluster on bare metal, managing approximately 2TB of transactional data with a peak load of 5,000 transactions per second." This level of detail is mandatory.
Clearly define your target architecture by connecting business goals to specific cloud services and methodologies:
- For containerization: "Our target state is a microservices architecture. Propose a detailed plan to containerize our primary monolithic Java application and deploy it on Google Kubernetes Engine (GKE). Your proposal must detail your approach to ingress (e.g., GKE Ingress, Istio Gateway), service mesh implementation (e.g., Istio, Linkerd), and secrets management (e.g., Google Secret Manager, HashiCorp Vault)."
- For serverless functions: "We are refactoring our nightly batch processing jobs into event-driven serverless functions. Describe your experience with Azure Functions using the Premium plan. Detail how you would handle triggers from Azure Blob Storage, implement idempotent logic, manage error handling via dead-letter queues, and ensure secure integration with our on-premises data warehouse."
- For compliance: "Our application processes Protected Health Information (PHI). The proposed architecture must be fully HIPAA compliant. Explain your precise configuration for logging (e.g., AWS CloudTrail, Azure Monitor), encryption at rest and in transit (e.g., KMS, TLS 1.2+), and IAM policies to meet these standards."
This specificity forces providers to engage in architectural problem-solving, not just marketing.
Demanding Specifics on Methodology and Governance
An expert partner brings a proven, battle-tested methodology. Your RFP must probe this area aggressively to distinguish strategic executors from mere order-takers. You are shifting the evaluation from what they will build to how they will build, test, and deploy it.
A provider's response to questions about methodology is often the clearest indicator of their experience. Vague answers suggest a lack of a battle-tested process, while detailed, opinionated responses show they've navigated complex projects before.
Challenge them to define their process for core migration tasks. You need evidence of a structured, repeatable methodology for secure and efficient execution. As managing these relationships is a discipline, familiarize your team with vendor management best practices.
Structuring Questions for Clarity
Frame questions to elicit concrete, comparable, and technical answers. Avoid open-ended prompts that invite marketing fluff.
IaC and Automation Proficiency:
"Describe your team's proficiency with Terraform. Provide a code sample illustrating how you would structure Terraform modules to manage a multi-environment (dev, staging, prod) setup in AWS. The sample should demonstrate how you enforce consistent VPC, subnet, and security group configurations and manage state."
Migration Strategy Justification:
"For our legacy CRM application (a .NET 4.5 monolith with a SQL Server backend), would you recommend a Rehost ('lift-and-shift') or a Refactor approach? Justify your choice with a quantitative analysis weighing initial downtime and cost against long-term TCO and operational agility. What are the primary technical risks of your chosen strategy and your mitigation plan?"
Project Governance and Communication:
"Detail your proposed project governance model. Specify the cadence for technical review meetings. How will you track progress against milestones using quantitative metrics (e.g., velocity, burndown charts)? What specific tools (e.g., Jira, Azure DevOps, Confluence) will be used for ticket management, documentation, and communication with our engineering team?"
By demanding this level of technical detail, your RFP becomes a powerful diagnostic tool, quickly separating providers with genuine, hands-on expertise from those with only proposal-writing skills.
Evaluating a Provider's Technical Chops and Strategy
With proposals in hand, the next phase is a rigorous technical evaluation to distinguish true engineering experts from proficient sales teams. A compelling presentation is irrelevant if the provider lacks the technical depth to execute your project's specific requirements.
The objective is not to select the provider with the most certifications but to find a team whose demonstrated, hands-on experience aligns with your technology stack, scale, and architectural goals.
Beyond the Case Study Glossy
Every provider will present curated case studies. Your task is to dissect them for technical evidence, not just business outcomes. If your project involves containerizing a Java monolith on Azure Kubernetes Service (AKS), a case study about a simple "lift-and-shift" of VMs to AWS is not relevant evidence of capability.
Scrutinize their past projects with technical granularity:
- Scale and Complexity: Did they migrate a 10TB multi-tenant OLTP database or a 100GB departmental database? Was it a single, stateless application or a complex system of 50+ interdependent microservices with convoluted data flows?
- Tech Stack Parallels: Demand evidence of direct experience with your core technologies. If you run a high-throughput PostgreSQL cluster, a provider whose expertise is limited to MySQL or Oracle will be learning on your project.
- Problem-Solving Details: The most valuable case studies are post-mortems, not just success stories. They should detail the technical obstacles encountered and overcome. How did they resolve an unexpected network latency issue post-migration? How did they script a complex data synchronization process for the final cutover?
These details reveal whether their experience is truly applicable or merely adjacent.
Verifying Team Expertise and Certifications
A provider is the sum of the engineers assigned to your project. Request the profiles and certifications of the specific team members who will execute the work. Certifications serve as a validated baseline of knowledge.
Key credentials to look for include:
- Cloud Platform Specific: AWS Certified Solutions Architect – Professional or Microsoft Certified: Azure Solutions Architect Expert demonstrates deep platform-specific architectural knowledge.
- Specialized Skills: For container orchestration, a Certified Kubernetes Administrator (CKA) or Certified Kubernetes Application Developer (CKAD) is essential.
- Infrastructure as Code (IaC): The HashiCorp Certified: Terraform Associate certification validates foundational automation skills.
Certifications prove foundational knowledge, but they don't replace hands-on experience. During technical interviews, ask engineers to describe a complex problem they solved using the skills validated by their certification. Their answer will reveal their true depth of expertise.
Probe their practical, in-the-weeds experience. Ask them to whiteboard a CI/CD pipeline architecture using GitLab CI for a containerized application. Ask about their preferred methods for managing secrets in Kubernetes (e.g., Sealed Secrets, External Secrets Operator, Vault). The fluency and technical depth of their answers are your best indicators of real expertise.
The market is accelerating, with companies achieving operational efficiency gains of up to 30% and reducing IT infrastructure costs by up to 50%. The hybrid cloud market is growing at an 18.7% CAGR as organizations optimize workload placement for performance, cost, and compliance. The official AWS blog details why a migration inflection point is approaching.
Analyzing the Proposed Migration Methodology
Dissect their proposed migration strategy. A premier provider will justify their approach with a clear, data-driven rationale linked directly to your stated technical and business objectives. They must present a detailed plan for data migration with minimal downtime and a comprehensive strategy for testing and validation.
Ask pointed, technical questions that test their problem-solving capabilities:
- Data Migration: "Present your specific technical plan for migrating our primary 2TB PostgreSQL database with a maximum downtime window of 15 minutes. Detail the tools (e.g., AWS DMS, native replication), the sequence of events, and the rollback procedure if validation fails post-cutover."
- Testing and Validation: "Describe your testing strategy. How will you automate integration, performance (load testing), and security (penetration testing) in the new cloud environment before the final cutover? What specific metrics and SLOs will define a successful test?"
- Contingency Planning: "Walk me through a failure scenario. Assume that mid-migration, we discover a critical, undocumented hard-coded IP address in a legacy application. What is your process for diagnosing, adapting the plan, and communicating the impact on the timeline and budget?"
Their responses to these questions will provide the clearest insight into their real-world competence. A confident, detailed response indicates experience; vague answers are a significant red flag.
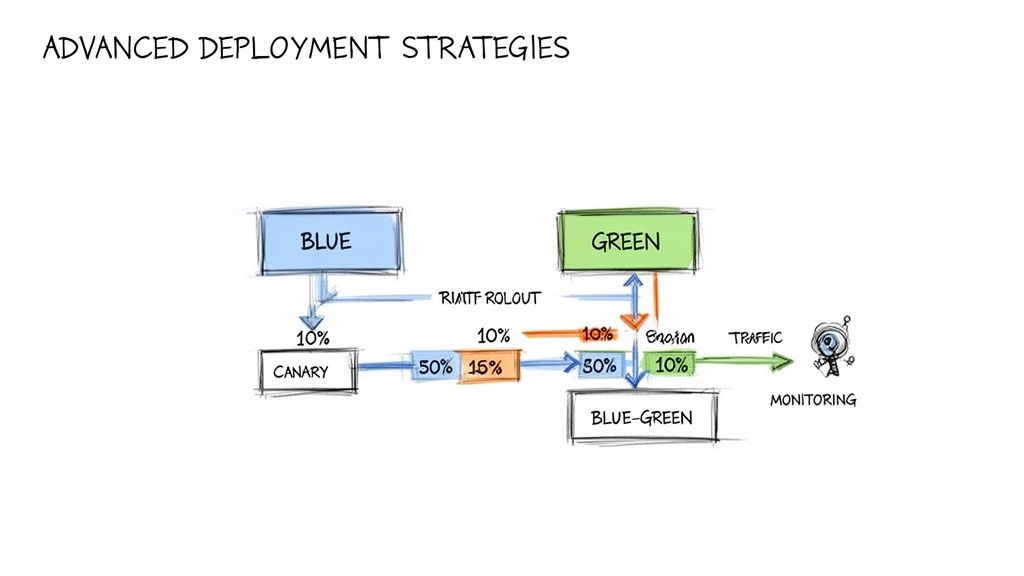
Comparing the 6 R's of Migration Strategy
A provider's plan will be based on the "6 R's" of cloud migration. Understanding these allows you to critically evaluate their proposal and challenge their choices for each application.
| Strategy | Description | Best For | Key Consideration |
|---|---|---|---|
| Rehost | "Lift-and-shift." Moving applications as-is by migrating VMs or servers. | Rapid, large-scale migrations where redesign is not immediately feasible. | Fails to leverage cloud-native features; can result in higher long-term TCO. |
| Replatform | "Lift-and-reshape." Making minor cloud optimizations without changing the core architecture. | Gaining immediate cloud benefits (e.g., moving from self-managed MySQL to Amazon RDS) without a full rewrite. | An intermediate step that can add complexity if not part of a longer-term refactoring plan. |
| Repurchase | Moving to a SaaS solution. | Replacing on-premises commodity software (e.g., CRM, HR systems) with a cloud-native alternative. | Requires data migration, user retraining, and potential business process re-engineering. |
| Refactor | Re-architecting an application to be cloud-native, often using microservices and serverless. | Maximizing cloud benefits: scalability, resilience, performance, and cost-efficiency. | Highest upfront cost and effort; requires significant software engineering resources. |
| Retire | Decommissioning applications that are no longer needed. | Reducing complexity, cost, and security surface area by eliminating obsolete systems. | Requires thorough dependency analysis to ensure no critical business functions are broken. |
| Retain | Keeping specific applications on-premises. | Hybrid cloud strategies, applications with extreme low-latency requirements, or those that cannot be moved. | Necessitates a robust strategy for hybrid connectivity and integration (e.g., VPN, Direct Connect). |
An expert partner will propose a blended strategy, applying the appropriate "R" to each application based on its business value, technical architecture, and your overall goals. They must be able to defend each decision with data.
Getting Serious About Security, Compliance, and SLAs
A migration is a failure if it introduces security vulnerabilities or violates compliance mandates, regardless of application uptime. A rigorous evaluation of a provider's security practices and service level agreements (SLAs) is non-negotiable. This involves understanding their methodology for engineering secure cloud environments from the ground up.
Kicking the Tires on Core Security Practices
A provider's security expertise is demonstrated through technical details. Drill down on their approach to Identity and Access Management (IAM). They must articulate how they implement the principle of least privilege. Ask for examples of IAM roles and policies they would construct for developers, applications (via service accounts), and CI/CD pipelines, ensuring each has the minimum required permissions.
Data encryption is paramount. They should detail their standards for encryption in transit (e.g., enforcing TLS 1.2 or higher) and at rest (e.g., using AWS KMS with customer-managed keys or Azure Key Vault). Ask about their process for key rotation and lifecycle management.
Probe their network architecture design. Discuss their methodology for designing secure Virtual Private Clouds (VPCs) or Virtual Networks (VNets), including their strategies for multi-tier subnetting (public, private, database), configuration of network access control lists (NACLs), and the principle of default-deny for security groups.
Your partner must be an expert in mastering cloud infra security—it is the foundation of a modern, resilient business.
Navigating the Maze of Regulatory Compliance
If your business operates under specific regulatory frameworks, the provider's direct experience is critical. A generic claim of "compliance experience" is insufficient. You need evidence they have successfully implemented and audited environments under your specific mandate.
- Healthcare (HIPAA): Request a detailed architectural diagram of a HIPAA-compliant environment they have built. They should be able to discuss implementing Business Associate Agreements (BAAs) with the cloud vendor and configuring services like AWS CloudTrail or Azure Monitor for immutable logging of access to Protected Health Information (PHI).
- Finance (PCI DSS): Scrutinize their experience with segmenting Cardholder Data Environments (CDE). They must explain precisely how they use network segmentation, firewall rules, and intrusion detection systems to isolate the CDE and meet stringent PCI requirements.
- Data Privacy (GDPR/CCPA): Discuss their implementation of data residency controls and their technical strategies for fulfilling "right to be forgotten" requests within a distributed cloud architecture.
The demand for cloud migration services is driven by these complex security and compliance requirements. North America leads the market because organizations are leveraging advanced cloud security features to adhere to frameworks like HIPAA, GDPR, and CCPA.
If a provider cannot fluently discuss the technical controls specific to your compliance framework, they are not qualified. This area demands proven, hands-on expertise.
Decoding the Service Level Agreement (SLA)
Look beyond the headline 99.99% uptime promise in the Service Level Agreement (SLA). The fine print defines the true nature of the commitment. A robust SLA is your primary tool for accountability.
Our cloud security checklist provides a comprehensive guide, but your SLA review must cover these technical specifics:
- Support Response Times: What are the guaranteed response and resolution times for different severity levels (e.g., Sev1, Sev2, Sev3)? A "24-hour response" for a critical production outage (Sev1) is unacceptable.
- Remediation Processes: The agreement must define Mean Time to Resolution (MTTR) targets. What are the provider's contractual obligations for resolving an issue once acknowledged?
- Financial Penalties: What are the specific service credits or financial penalties for failing to meet the SLA? The penalties must be significant enough to incentivize performance.
The signed contract is the final step in your vetting process. It must codify a partnership that protects your digital assets and contractually binds the provider to their commitments.
Planning for Life After Migration
The migration cutover is not the finish line; it is the starting point for cloud operations. Many organizations execute a successful migration only to face runaway costs and operational instability. A premier cloud migration service provider anticipates this and ensures a structured transition to your team.
The post-migration phase is where the true value of the partnership is realized. The objective is not merely to migrate you to the cloud but to empower your team to operate and optimize the new environment effectively.
Structuring a Successful Technical Handover
A proper handover is a formal knowledge transfer process, not a simple email. Your provider must deliver a comprehensive package of documentation, code, and training.
Insist on these deliverables:
- Architectural Diagrams: Detailed, up-to-date diagrams of the cloud architecture, including VPC/VNet layouts, subnets, security groups, service integrations, and data flow diagrams.
- Runbooks: Step-by-step operational procedures for common tasks and incident response. Examples include: "How to perform a database point-in-time restore," "Procedure for responding to a high CPU alert on the Kubernetes cluster," and "Disaster recovery failover process."
- IaC Repository: Full access to the well-documented Terraform or CloudFormation repository used to provision the infrastructure. The code should be modular, commented, and follow best practices.
Documentation alone is insufficient. Demand hands-on training sessions where your engineers work alongside the provider's team to learn the new operational workflows, CI/CD processes, and monitoring tools.
Defining Your Ongoing Partnership Model
Complete disengagement is often impractical. Transition to a long-term relationship model that provides strategic value without creating operational dependency.
Common models include:
- Managed Services: The provider assumes responsibility for day-to-day operations, including monitoring, patching, and incident response. Ideal for teams that need to focus on application development.
- Advisory Retainer: You retain access to their senior architects for a fixed number of hours per month for strategic guidance on cost optimization, security posture, or adopting new cloud services.
- Project-Based Engagements: You re-engage the provider for specific, well-defined projects, such as implementing a new disaster recovery strategy or building out a data analytics platform.
The optimal model depends on your in-house skill set and long-term strategic goals.
The most successful post-migration strategies I've witnessed involve a gradual transfer of ownership. The provider starts by managing everything, then moves to a co-pilot role, and finally transitions to an on-demand advisor as your team's confidence and expertise grow.
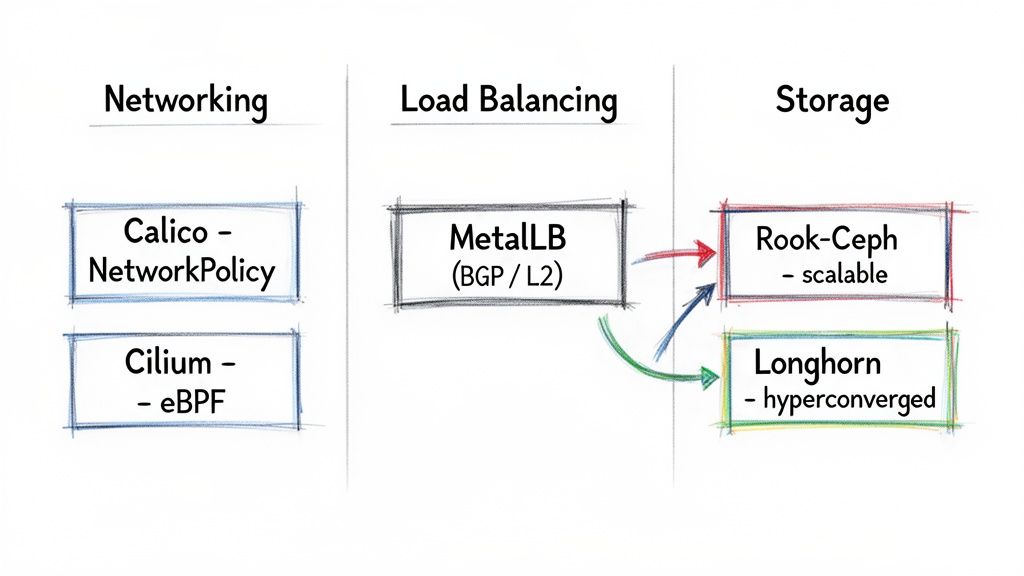
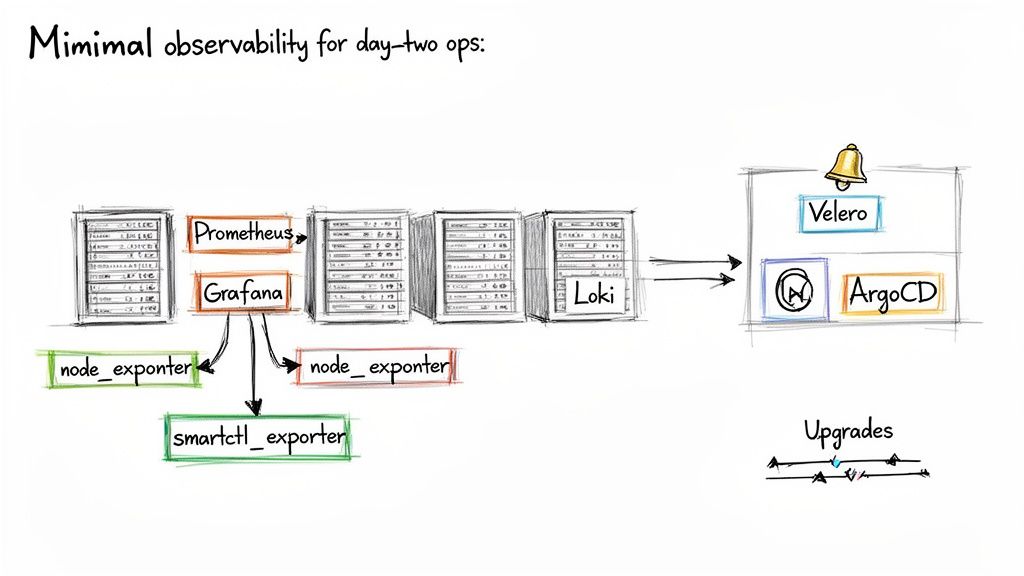
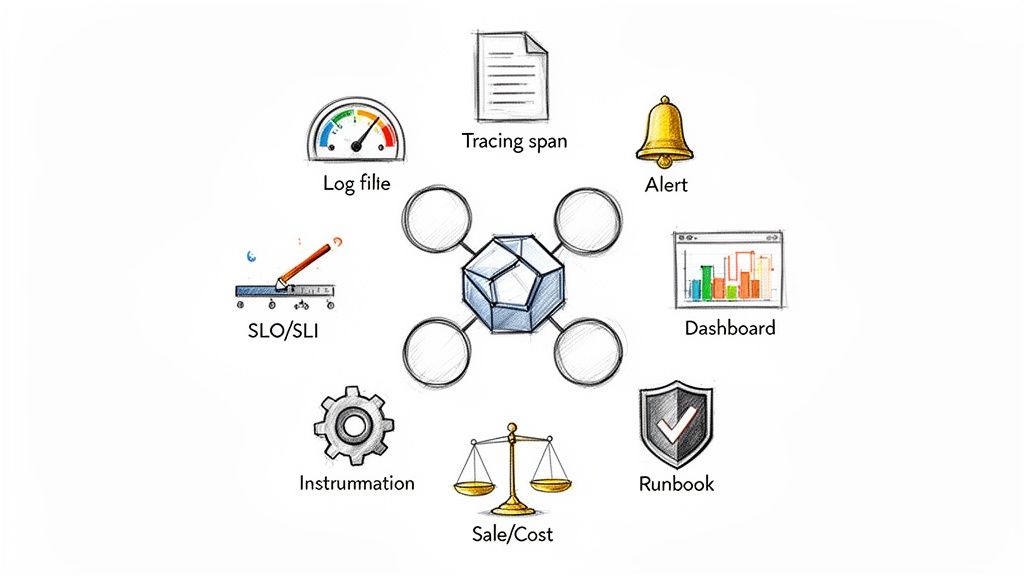
Implementing FinOps and Observability
Two disciplines are critical for long-term cloud success: FinOps (Financial Operations) and observability. Your provider should help establish a strong foundation for both before the handover.
For FinOps, this involves implementing tools and processes for cloud financial management. This includes resource tagging strategies to attribute costs to specific teams or projects, setting up automated policies to decommission idle resources (e.g., using AWS Lambda or Azure Automation), and creating dashboards to track spend against budget. They should also provide an analysis for purchasing Reserved Instances or Savings Plans.
For observability, this means moving beyond basic metrics (CPU, memory) to a comprehensive understanding of system health through metrics, logs, and traces. This often involves instrumenting applications and infrastructure with tools like Prometheus for metrics, Loki or the ELK Stack for logs, and Jaeger or OpenTelemetry for tracing. A good partner will help you configure dashboards and alerts based on Service Level Objectives (SLOs) that reflect the end-user experience.
Frequently Asked Questions
Embarking on a cloud migration project brings many technical and strategic questions. Here are answers to some of the most common inquiries.
What Common Mistakes Should I Avoid When Choosing a Provider?
The most common and costly mistake is selecting a provider based solely on the lowest price. This often leads to technical debt, security vulnerabilities, and expensive rework when the initial migration fails to meet performance or operational requirements.
Another critical error is failing to perform deep technical diligence on a provider's case studies and references. You must verify that they have successfully executed projects of similar technical complexity, scale, and compliance requirements.
Other technical red flags include:
- A "one-size-fits-all" plan: A competent provider will insist on a paid discovery phase to conduct a thorough audit before proposing a solution. A generic template is a sign of inexperience.
- A vague Statement of Work (SOW): The SOW must precisely define the scope, technical deliverables, success criteria (SLOs/SLAs), and operational handover plan. Ambiguity leads to scope creep and disputes.
- Neglecting post-migration operations: A project plan that ends at cutover is incomplete. Failing to plan for knowledge transfer, FinOps implementation, and ongoing operational support sets your internal team up for failure.
How Long Does a Typical Cloud Migration Project Take?
There is no "typical" timeline without a detailed assessment. The duration varies significantly based on complexity and the chosen migration strategy.
A simple Rehost ("lift-and-shift") of a few dozen VMs might be completed in several weeks. However, a complex Refactor of a core monolithic application into cloud-native microservices on Kubernetes can take 6 to 18 months or more.
An experienced cloud migration provider will never provide a definitive timeline upfront. They will propose a phased approach with clear milestones and deliverables for each stage: Assessment, Planning, Execution, and Optimization.
Factors that heavily influence the timeline include the volume of data to be migrated, the complexity of application dependencies, the level of test automation required, and the extent to which Infrastructure as Code is adopted.
Is a Cloud Migration Specialist Different from an MSP?
Yes, their core competencies and engagement models are distinct, though some firms offer both services.
A cloud migration service provider is a project-based specialist. Their expertise is focused on the one-time event of planning and executing the migration from a source to a target environment. The engagement is finite, concluding with the successful handover of the new cloud infrastructure to your team.
A Managed Service Provider (MSP) focuses on long-term, ongoing operations. They engage after the migration is complete to manage the day-to-day operational tasks of the cloud environment, which typically include:
- 24/7 monitoring and incident response (NOC/SOC functions)
- Security posture management and compliance auditing
- OS and application patching
- Cost monitoring and optimization
It is critical to evaluate a provider's expertise in each domain separately. The skills required for complex architectural design and migration are different from those required for efficient daily cloud operations.
How Do I Create an Accurate Budget for a Cloud Migration?
A comprehensive budget extends beyond the provider's professional services fees. It must account for several key cost categories.
First, the provider's fees, structured as either a fixed-price contract for a well-defined scope or a time-and-materials (T&M) model for more exploratory refactoring projects.
Second, the cloud consumption costs during and after migration. Your provider should help you create a detailed forecast using tools like the AWS Pricing Calculator or Azure TCO Calculator. This forecast must include compute, storage, networking, data egress fees, and any managed services (e.g., RDS, EKS).
Third, account for third-party software and tooling licenses. This may include migration tools, new security platforms (e.g., WAF, CWPP), or observability platforms (e.g., Datadog, New Relic).
Finally, budget for the internal cost of your own team's time. Your engineers and project managers will be heavily involved in the process. Investing in a paid discovery or assessment phase is the most reliable method for gathering the data needed to build an accurate, comprehensive budget.
At OpsMoon, we bridge the gap between strategy and execution. Our Experts Matcher connects you with the top 0.7% of global DevOps talent to ensure your cloud migration is not just completed, but masterfully executed with a clear plan for post-migration success. Plan your project with a free work planning session to build a clear roadmap for your cloud journey. https://opsmoon.com