When you move workloads to Kubernetes, you quickly realize traditional monitoring tools are inadequate. The environment is dynamic, distributed, and ephemeral. You need a monitoring solution architected for this paradigm, and Prometheus has become the de facto open-source standard for cloud-native observability. This guide provides a technical walkthrough for deploying and configuring a production-ready Prometheus stack.
Why Prometheus Is the Right Choice for Kubernetes
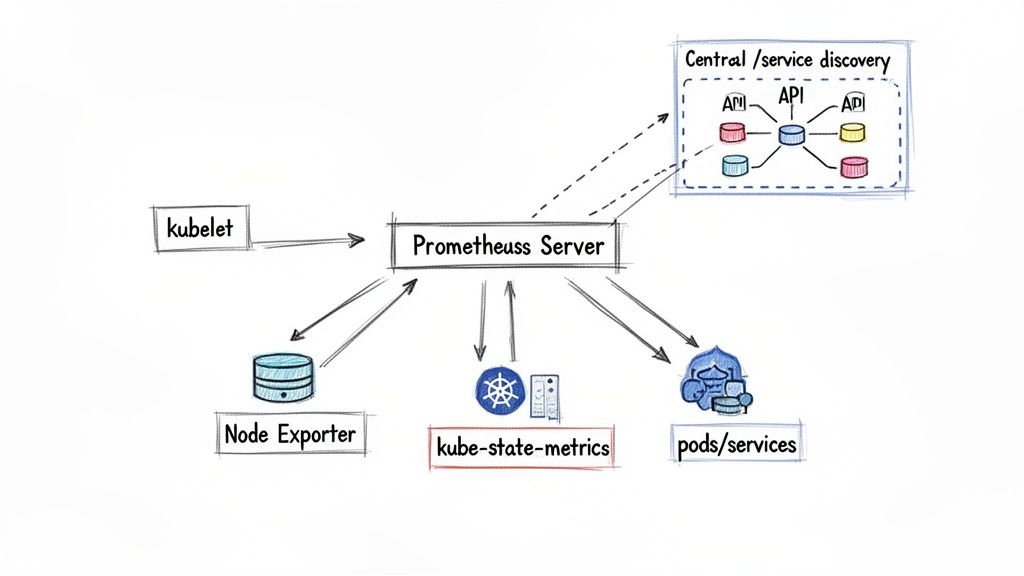
Prometheus's core strength lies in its pull-based metric collection model. Instead of applications pushing metrics to a central collector, Prometheus actively scrapes HTTP endpoints where metrics are exposed in a simple text-based format. This design decouples your services from the monitoring system. A microservice only needs to expose a /metrics endpoint; Prometheus handles discovery and collection. In a Kubernetes environment where pod IP addresses are ephemeral, this pull model is essential for reliability.
Built for Dynamic Environments
Prometheus integrates directly with the Kubernetes API for service discovery, enabling it to automatically detect new pods, services, and nodes as they are created or destroyed. Manually configuring scrape targets in a production cluster is not feasible at scale. Prometheus leverages Kubernetes labels and annotations to dynamically determine what to monitor, which port to scrape, and how to enrich the collected data with contextual labels like pod name, namespace, and container.
This functionality is powered by a dimensional data model and its corresponding query language, PromQL. Every metric is stored as a time series, identified by a name and a set of key-value pairs (labels). This model allows for powerful, flexible aggregation and analysis, enabling you to ask precise questions about your system's performance and health.
The Ecosystem That Powers Production Reliability
Prometheus itself is the core, but a production-grade monitoring solution relies on an entire ecosystem of components working in concert. Before deploying, it is critical to understand the role of each tool in the stack.
Core Prometheus Components for Kubernetes Monitoring
| Component | Primary Role | Technical Functionality |
|---|---|---|
| Prometheus Server | Scrapes, stores, and queries time-series data | Executes scrape jobs, ingests metrics into its TSDB, and serves PromQL queries. |
| Exporters | Expose metrics from third-party systems | Acts as a proxy, translating metrics from non-Prometheus formats (e.g., JMX, StatsD) to the Prometheus exposition format. |
| Alertmanager | Manages and routes alerts | Deduplicates, groups, and routes alerts from Prometheus to configured receivers like PagerDuty or Slack based on defined rules. |
| Grafana | Visualizes metrics in dashboards | Queries the Prometheus API to render time-series data into graphs, charts, and dashboards for operational visibility. |
These components form a complete observability platform. Exporters provide the data, Alertmanager handles incident response, and Grafana provides the human interface for analysis.
Kubernetes adoption has surged, with 93% of organizations using or planning to use it in 2024. Correspondingly, Prometheus has become the dominant monitoring tool, used by 65% of Kubernetes users. To effectively leverage this stack, a strong foundation in general application monitoring best practices is indispensable.
Getting a Production-Ready Prometheus Stack Deployed
Moving from theory to a functional Prometheus deployment requires careful configuration. While a simple helm install can launch the components, a production stack demands high availability, persistent storage, and declarative management.
The standard for this task is the kube-prometheus-stack Helm chart. This chart bundles Prometheus, Alertmanager, Grafana, and essential exporters, all managed by the Prometheus Operator. The Operator extends the Kubernetes API with Custom Resource Definitions (CRDs) like Prometheus, ServiceMonitor, and PrometheusRule. This allows you to manage monitoring configurations declaratively as native Kubernetes objects, which is ideal for GitOps workflows.
Laying the Groundwork: Chart Repo and Namespace
First, add the Helm repository and create a dedicated namespace for the monitoring stack. Isolating monitoring components simplifies resource management, access control (RBAC), and lifecycle operations.
# Add the Prometheus community Helm repository
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# Update your local Helm chart repository cache
helm repo update
# Create a dedicated namespace for monitoring components
kubectl create namespace monitoring
Deploying a complex chart like this without a custom values.yaml file is a common anti-pattern. Defaults are for demonstration; production requires deliberate configuration.
Don't Lose Your Data: Configuring Persistent Storage
The default Helm chart configuration may use an emptyDir volume for Prometheus, which is ephemeral. If the Prometheus pod is rescheduled, all historical metric data is lost. For any production environment, you must configure persistent storage using a PersistentVolumeClaim (PVC). This requires a provisioned StorageClass in your cluster.
Here is the required values.yaml configuration snippet:
# values.yaml
prometheus:
prometheusSpec:
storageSpec:
volumeClaimTemplate:
spec:
# Replace 'standard' with your provisioner's StorageClass if needed
storageClassName: standard
accessModes: ["ReadWriteOnce"]
resources:
requests:
# Size based on metric cardinality, scrape interval, and retention
storage: 50Gi
# Define how long metrics are kept in this local TSDB
retention: 24h
Pro Tip: The local retention period (
retention) should be carefully considered. If you are usingremote_writeto offload metrics to a long-term storage solution, a shorter local retention (e.g., 12-24 hours) is sufficient and reduces disk costs. If this Prometheus instance is your primary data store, you'll need a larger PVC and a longer retention period.
Give It Room to Breathe: Setting Resource Requests and Limits
Resource starvation is a leading cause of monitoring stack instability. Prometheus can be memory-intensive, especially in clusters with high metric cardinality. Without explicit resource requests and limits, the Kubernetes scheduler might place the pod on an under-resourced node, or the OOMKiller might terminate it under memory pressure.
Define these values in your values.yaml to ensure stable operation.
# values.yaml
prometheus:
prometheusSpec:
resources:
requests:
cpu: "1" # Start with 1 vCPU
memory: 2Gi
limits:
cpu: "2" # Allow bursting to 2 vCPUs
memory: 4Gi
alertmanager:
alertmanagerSpec:
resources:
requests:
cpu: 100m
memory: 200Mi
limits:
cpu: 200m
memory: 300Mi
These settings guarantee that Kubernetes allocates sufficient resources for your monitoring components. For further optimization, review different strategies for Prometheus service monitoring.
Firing Up the Visuals: Enabling Grafana
The kube-prometheus-stack chart includes Grafana, but it must be explicitly enabled. Activating it provides an immediate visualization layer, and the chart includes a valuable set of pre-built dashboards for cluster monitoring. As with Prometheus, enable persistence for Grafana to retain custom dashboards and settings across pod restarts.
# values.yaml
grafana:
enabled: true
persistence:
type: pvc
enabled: true
storageClassName: standard
accessModes:
- ReadWriteOnce
size: 10Gi
# WARNING: For production, use a secret management tool like Vault or ExternalSecrets
# to manage the admin password instead of plain text.
adminPassword: "your-secure-password-here"
With these configurations, you are ready to deploy a production-ready stack using helm install. This declarative approach is the foundation of a scalable and manageable monitoring strategy in any Kubernetes environment.
Configuring Dynamic Service Discovery and Scraping
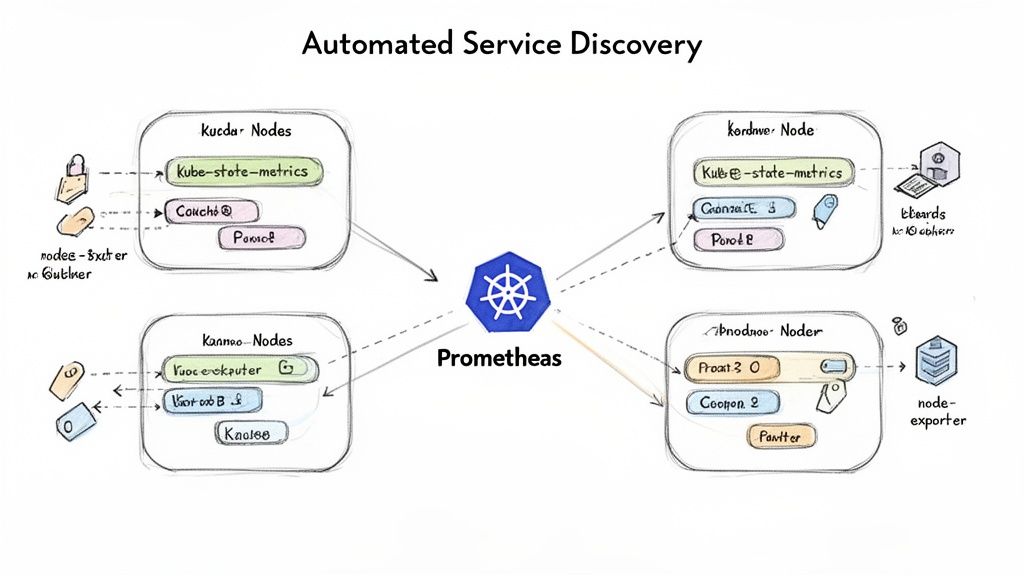
Static scrape configurations are obsolete in Kubernetes. Pod and service IPs are ephemeral, changing with deployments, scaling events, and node failures. Manually tracking scrape targets is untenable. The solution is Prometheus's dynamic service discovery mechanism, specifically kubernetes_sd_config.
This directive instructs Prometheus to query the Kubernetes API to discover scrape targets based on their role (e.g., role: pod, role: service). This real-time awareness is the foundation of an automated monitoring configuration.
The operational workflow becomes a continuous cycle of configuration, deployment, and management.
As the diagram illustrates, monitoring configuration is not a one-time setup but an iterative process that evolves with your cluster and applications.
Leveraging Labels for Automatic Discovery
The power of kubernetes_sd_config is fully realized when combined with Kubernetes labels and annotations. Instead of specifying individual pods, you create a rule that targets any pod matching a specific label selector.
For example, a standard practice is to adopt a convention like prometheus.io/scrape: 'true'. Your Prometheus configuration then targets any pod with this label. When a developer deploys a new service with this label, Prometheus automatically begins scraping it without any manual intervention. This decouples monitoring configuration from application deployment, empowering developers to make their services observable by adding metadata to their Kubernetes manifests.
A Practical Example with a Spring Boot App
Consider a Java Spring Boot microservice that exposes metrics on port 8080 at the /actuator/prometheus path. To enable automatic discovery, add the following annotations to the pod template in your Deployment manifest:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-spring-boot-app
spec:
template:
metadata:
annotations:
prometheus.io/scrape: "true"
prometheus.io/path: "/actuator/prometheus"
prometheus.io/port: "8080"
...
The scrape annotation marks the pod as a target. The path and port annotations override Prometheus's default scrape behavior, instructing it to use the specified endpoint. This declarative approach integrates seamlessly into a GitOps workflow.
Mastering Relabeling to Refine Targets
After discovering a target, Prometheus attaches numerous metadata labels prefixed with __meta_kubernetes_, such as pod name, namespace, and container name. While useful, this raw metadata can be noisy and inconsistent.
The relabel_configs section in your scrape job configuration is a powerful mechanism for transforming, filtering, and standardizing these labels before metrics are ingested. Mastering relabeling is critical for maintaining a clean, efficient, and cost-effective monitoring system.
Key Takeaway: Relabeling is a crucial tool for performance optimization and cost control. You can use it to drop high-cardinality metrics or unwanted targets at the source, preventing them from consuming storage and memory resources.
Common relabeling actions include:
- Filtering Targets: Using the
keepordropaction to scrape only targets that match specific criteria (e.g., pods in aproductionnamespace). - Creating New Labels: Constructing meaningful labels by combining existing metadata, such as creating a
joblabel from a Kubernetesapplabel. - Cleaning Up: Dropping all temporary
__meta_*labels after processing to keep the final time-series data clean.
Prometheus is the dominant Kubernetes observability tool, with 65% of organizations relying on it. Originally developed at SoundCloud in 2012 for large-scale containerized environments, its tight integration with Kubernetes makes it the default choice. For more on these container adoption statistics, you can review recent industry reports. By combining dynamic service discovery with strategic relabeling, you can build a monitoring configuration that scales effortlessly with your cluster.
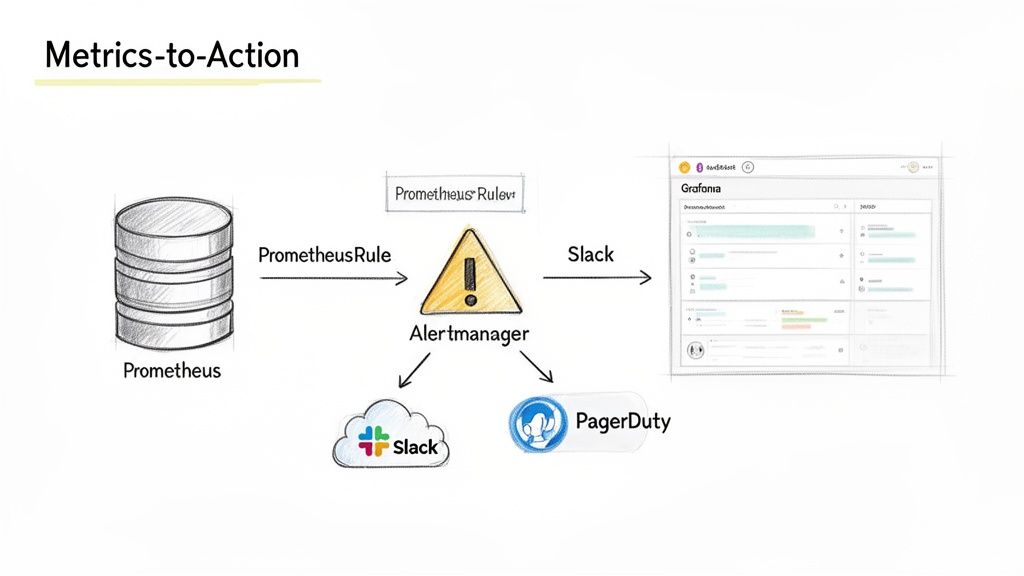
Building Actionable Alerts with Alertmanager
Metric collection provides data; alerting turns that data into actionable signals that can prevent or mitigate outages. Alertmanager is the component responsible for this transformation.
The primary challenge in a microservices architecture is alert fatigue. If on-call engineers receive a high volume of low-value notifications, they will begin to ignore them. An effective alerting strategy focuses on user-impacting symptoms, such as elevated error rates or increased latency, rather than raw resource utilization.
Defining Alerting Rules with PrometheusRule
The Prometheus Operator provides the PrometheusRule CRD, allowing you to define alerting rules as native Kubernetes objects. This approach integrates perfectly with GitOps workflows.
An effective alert definition requires:
expr: The PromQL query that triggers the alert.for: The duration a condition must be true before the alert fires. This is the most effective tool for preventing alerts from transient, self-correcting issues.- Labels: Metadata attached to the alert, used by Alertmanager for routing, grouping, and silencing. The
severitylabel is a standard convention. - Annotations: Human-readable context, including a summary and description. These can use template variables from the query to provide dynamic information.
Production-Tested Alerting Templates
This example demonstrates an alert that detects a pod in a CrashLoopBackOff state using metrics from kube-state-metrics.
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
name: critical-pod-alerts
labels:
# These labels are used by the Prometheus Operator to select this rule
prometheus: k8s
role: alert-rules
spec:
groups:
- name: kubernetes-pod-alerts
rules:
- alert: KubePodCrashLooping
expr: rate(kube_pod_container_status_restarts_total{job="kube-state-metrics"}[15m]) * 60 * 5 > 0
for: 10m
labels:
severity: critical
annotations:
summary: "Pod {{ $labels.namespace }}/{{ $labels.pod }} is crash-looping"
description: "Container {{ $labels.container }} in Pod {{ $labels.pod }} has been restarting frequently over the last 15 minutes."
The for: 10m clause is critical. It ensures that the alert only fires if the pod has been consistently restarting for 10 minutes, filtering out noise from temporary issues.
Key Takeaway: The goal of alerting is to identify persistent, meaningful failures. The
forduration is the simplest and most effective mechanism for reducing alert noise and preserving the focus of your on-call team.
Intelligent Routing with Alertmanager
Effective alerting requires routing the right information to the right team at the right time. Alertmanager acts as a central dispatcher, receiving alerts from Prometheus and then grouping, silencing, and routing them to notification channels like Slack, PagerDuty, or email.
This routing logic is defined in the AlertmanagerConfig CRD. A common and effective strategy is to route alerts based on their severity label:
severity: critical: Route directly to a high-urgency channel like PagerDuty.severity: warning: Post to a team's Slack channel for investigation during business hours.severity: info: Log for awareness without sending a notification.
This tiered approach ensures critical issues receive immediate attention. Furthermore, you can configure inhibition rules to suppress redundant alerts. For example, if a KubeNodeNotReady alert is firing for a specific node, you can automatically inhibit all pod-level alerts originating from that same node. This prevents an alert storm and allows the on-call engineer to focus on the root cause.
Visualizing Kubernetes Health with Grafana
Alerts notify you of failures. Dashboards provide the context to understand why a failure is occurring or is about to occur. Grafana is the visualization layer that transforms raw Prometheus time-series data into actionable insights about your cluster's health.
The kube-prometheus-stack Helm chart automatically configures Grafana with Prometheus as its data source, allowing you to begin visualizing metrics immediately. It also provisions a suite of battle-tested community dashboards for monitoring core Kubernetes components.
Jumpstart with Community Dashboards
Before building custom dashboards, leverage the pre-built ones included with the stack. They provide immediate visibility into critical cluster metrics.
Essential included dashboards:
- Kubernetes / Compute Resources / Cluster: Provides a high-level overview of cluster-wide resource utilization (CPU, memory, disk).
- Kubernetes / Compute Resources / Namespace (Workloads): Drills down into resource consumption by namespace, useful for capacity planning and identifying resource-heavy applications.
- Kubernetes / Compute Resources / Pod: Offers granular insights into the performance of individual pods, essential for debugging specific application issues.
These dashboards are the first step in diagnosing systemic problems, such as cluster-wide memory pressure or CPU saturation in a specific namespace.
Building a Custom Microservice Dashboard
While community dashboards are excellent for infrastructure health, operational excellence requires dashboards tailored to your specific applications. A standard microservice dashboard should track the "Golden Signals" or RED metrics (Rate, Errors, Duration).
Key Performance Indicators (KPIs) to track:
- Request Throughput (Rate): Requests per second (RPS).
- Error Rate: The percentage of requests resulting in an error (typically HTTP 5xx).
- 99th Percentile Latency (Duration): The request duration for the slowest 1% of users.
To produce meaningful visualizations, you must focus on efficient metrics collection and instrument your applications properly.
Writing the Right PromQL Queries
Each panel in a Grafana dashboard is powered by a PromQL query. To build our microservice dashboard, we need queries that calculate our KPIs from the raw counter and histogram metrics exposed by the application. For a deep dive, consult our guide on the Prometheus Query Language in our detailed article.
Sample PromQL queries for a service named my-microservice:
Request Rate (RPS):
sum(rate(http_requests_total{job="my-microservice"}[5m]))This calculates the per-second average request rate over a 5-minute window.
Error Rate (%):
(sum(rate(http_requests_total{job="my-microservice", status=~"5.."}[5m])) / sum(rate(http_requests_total{job="my-microservice"}[5m]))) * 100This calculates the percentage of requests with a 5xx status code relative to the total request rate.
P99 Latency (ms):
histogram_quantile(0.99, sum(rate(http_request_duration_seconds_bucket{job="my-microservice"}[5m])) by (le))This calculates the 99th percentile latency from a
histogrammetric, providing insight into the worst-case user experience.
Pro Tip: Use Grafana's "Explore" view to develop and test your PromQL queries. It provides instant feedback, graphing capabilities, and autocompletion, significantly accelerating the dashboard development process.
Enhance your dashboards with variables for dynamic filtering (e.g., a dropdown to select a namespace or pod) and annotations. Annotations can overlay events from Prometheus alerts or your CI/CD pipeline directly onto graphs, which is invaluable for correlating performance changes with deployments or other system events.
Burning Questions About Prometheus and Kubernetes
Deploying Prometheus in Kubernetes introduces several architectural and operational questions. Here are solutions to some of the most common challenges.
How Do I Keep Prometheus Metrics Around for More Than a Few Weeks?
Prometheus's local time-series database (TSDB) is not designed for long-term retention in an ephemeral Kubernetes environment. A pod failure can result in total data loss. The standard solution is to configure remote_write, which streams metrics from Prometheus to a durable, long-term storage backend.
Several open-source projects provide this capability, including Thanos and Cortex. They leverage object storage (e.g., Amazon S3, Google Cloud Storage) for cost-effective long-term storage and offer features like a global query view across multiple Prometheus instances and high availability.
For those seeking to offload operational complexity, managed services are an excellent alternative:
- Grafana Mimir offers a massively scalable, multi-tenant time-series database.
- Amazon Managed Service for Prometheus provides a serverless Prometheus-compatible backend on AWS.
- Google Cloud Managed Service for Prometheus is the equivalent service on GCP.
What's the Real Difference Between Node Exporter and Kube-State-Metrics?
These two exporters provide distinct but equally critical views of cluster health. They are not interchangeable.
Node Exporter monitors the health of the underlying host machine. It runs as a DaemonSet (one instance per node) and exposes OS-level and hardware metrics: CPU utilization, memory usage, disk I/O, and network statistics. It answers the question: "Are my servers healthy?"
kube-state-metrics monitors the state of Kubernetes objects. It runs as a single deployment and queries the Kubernetes API server to convert the state of objects (Deployments, Pods, PersistentVolumes) into metrics. It answers questions like: "How many pods are in a Pending state?" or "What are the resource requests for this deployment?" It tells you if your workloads are healthy from a Kubernetes perspective.
In short: Node Exporter monitors the health of your nodes. Kube-state-metrics monitors the health of your Kubernetes resources. A production cluster requires both for complete visibility.
How Can I Monitor Apps That Don't Natively Support Prometheus?
The Prometheus ecosystem solves this with exporters. An exporter is a specialized proxy that queries a third-party system (e.g., a PostgreSQL database, a Redis cache), translates the data into the Prometheus exposition format, and exposes it on an HTTP endpoint for scraping. This pattern allows you to integrate hundreds of different technologies into a unified monitoring system.
For legacy or custom applications, several general-purpose exporters are invaluable:
- The Blackbox Exporter performs "black-box" monitoring by probing endpoints over HTTP, TCP, or ICMP. It can verify that a service is responsive, check for valid SSL certificates, and measure response times.
- The JMX Exporter is essential for Java applications. It connects to a JVM's JMX interface to extract a wide range of metrics from the JVM itself and the application running within it.
With the vast library of available exporters, there is virtually no system that cannot be monitored with Prometheus.
Navigating the complexities of a production-grade Kubernetes monitoring setup requires deep expertise. OpsMoon connects you with the top 0.7% of remote DevOps engineers who specialize in building and scaling observability platforms with Prometheus, Grafana, and Alertmanager. Start with a free work planning session to map out your monitoring strategy and get matched with the exact talent you need. Build a resilient, scalable system with confidence by visiting https://opsmoon.com.