DevSecOps consulting provides expert engineers to integrate security controls directly into the Software Development Lifecycle (SDLC). The primary goal is to address the cybersecurity skills gap by embedding security expertise within development and operations teams, enabling them to ship secure software faster.
From a technical standpoint, this means shifting from a traditional "gatekeeper" security model—where security reviews happen post-development—to a continuous, automated approach. The objective is to build security in, not bolt it on. This is achieved by integrating security tools and practices directly into CI/CD pipelines, Infrastructure as Code (IaC) workflows, and the developer's local environment.
Why Expert Guidance Is a Technical Necessity
In modern software delivery, CI/CD pipelines automate the path from code commit to production deployment. This velocity creates a significant challenge: traditional, manual security audits become bottlenecks, forcing a choice between deployment speed and security assurance. This is an unacceptable trade-off in an environment where vulnerabilities can be exploited within hours of discovery.
DevSecOps consulting services resolve this conflict by implementing "shift-left" security principles. This means security moves from being a final, blocking stage to an automated, continuous process embedded from the initial commit through to production monitoring.
Bridging the Critical Skills Gap
A common organizational challenge is the knowledge gap between development, operations, and security teams. Developers are experts in application logic, not necessarily in exploit mitigation. Security professionals understand threat vectors but may lack deep knowledge of declarative IaC or container orchestration.
DevSecOps consultants act as specialized engineers who bridge this divide by implementing tangible solutions and fostering a security-conscious engineering culture.
- For Developers: They integrate automated security tools—Static Application Security Testing (SAST), Dynamic Application Security Testing (DAST), and Software Composition Analysis (SCA)—directly into Git hooks and CI pipelines. This provides immediate, context-aware feedback on vulnerabilities within the developer's existing workflow (e.g., as comments on a pull request).
- For Operations: They codify security best practices for cloud infrastructure using IaC security scanners, harden container images with multi-stage builds and vulnerability scanning, and implement robust observability for production environments using tools like Falco for runtime threat detection.
- For Leadership: They translate technical risk into quantifiable business impact, demonstrating how security investments align with strategic objectives and compliance mandates.
This proactive, engineering-led model is driving market growth. The global DevSecOps market, valued at USD 5.89 billion, is projected to reach USD 52.67 billion by 2032, reflecting a fundamental shift in software engineering.
Automating Compliance and Governance
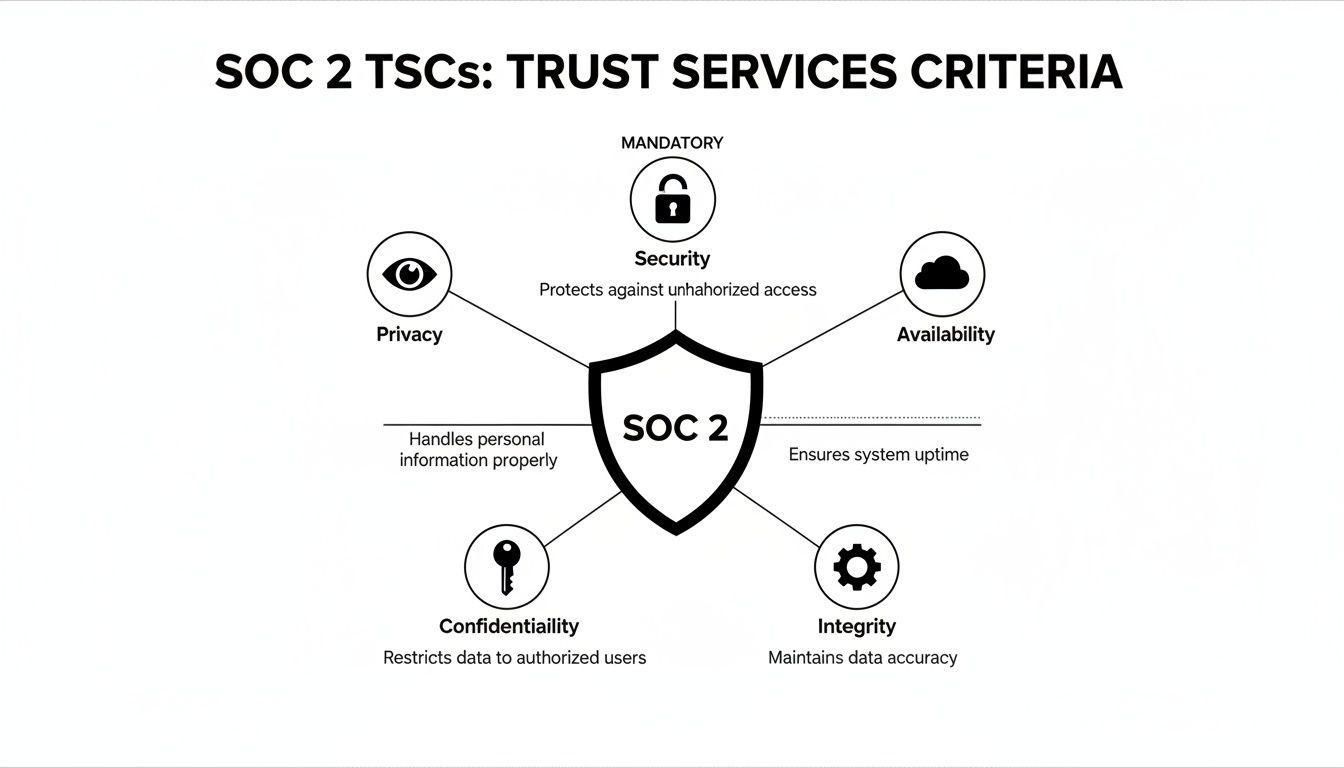
Regulatory frameworks like PCI DSS, HIPAA, and GDPR impose stringent requirements on data protection and system integrity. Manually auditing against these standards is slow and error-prone. See our guide on SOC 2 requirements for an example of the complexity involved.
DevSecOps consultants address this by implementing automated governance through Policy-as-Code (PaC). This transforms compliance from a periodic manual audit into a continuous, automated validation, ensuring systems meet regulatory standards without impeding development velocity.
A Technical Breakdown of Core Consulting Offerings
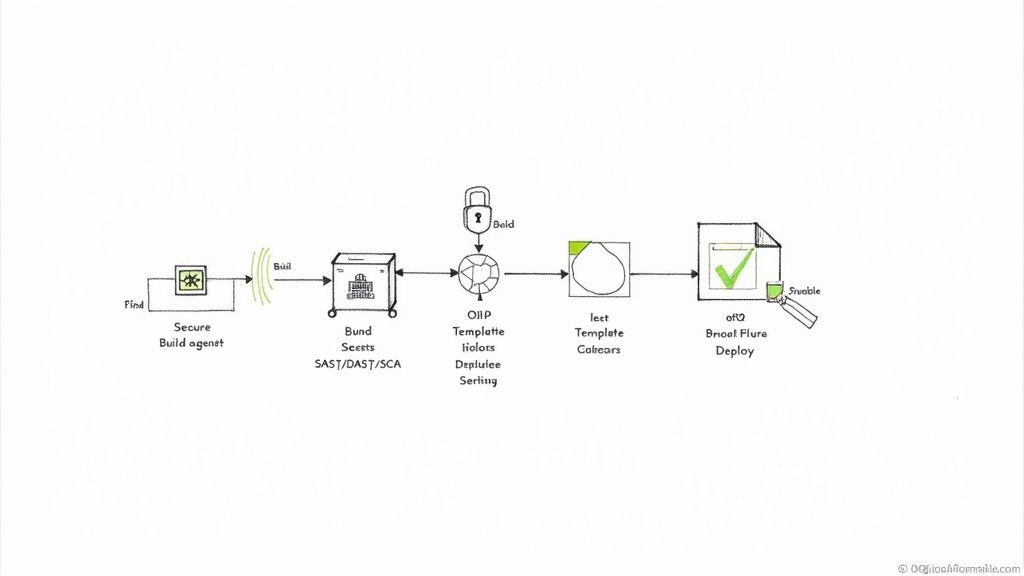
A DevSecOps consulting engagement is not about delivering high-level strategy documents. It's about deploying senior engineers to work alongside your teams, implementing and automating security controls directly within your existing toolchains and workflows.
The value is delivered through tangible, automated security measures embedded in code and infrastructure, not just documented in a final report. Consultants target high-risk areas where development velocity and security requirements conflict, acting as specialized engineers who not only identify vulnerabilities but also build the automated systems to prevent and remediate them. This hands-on approach is a key reason North America holds a 36-42.89% market share, with projections reaching USD 4.036 billion by 2030 due to cloud-native adoption and regulatory pressures.
Let's examine the specific technical deliverables.
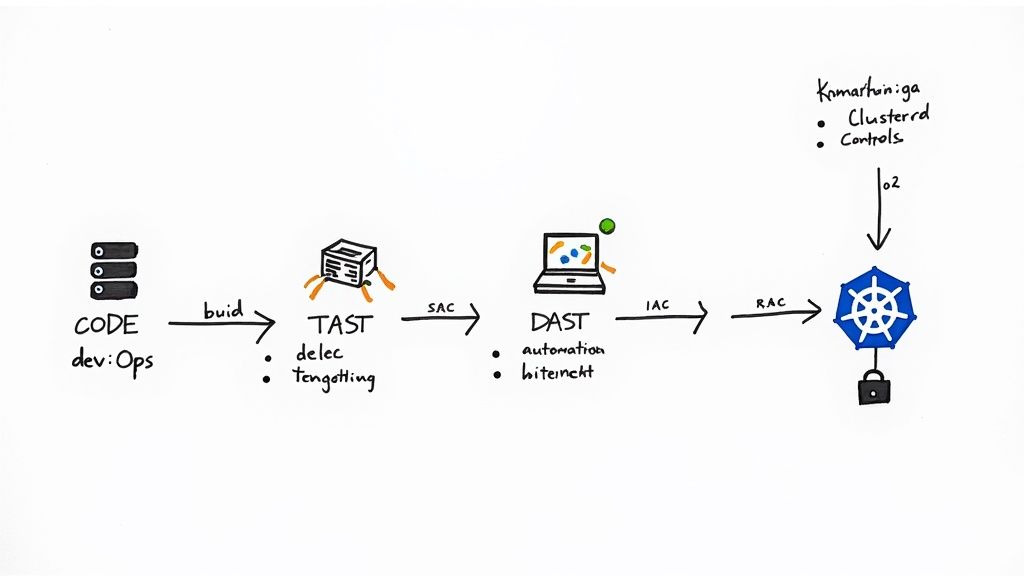
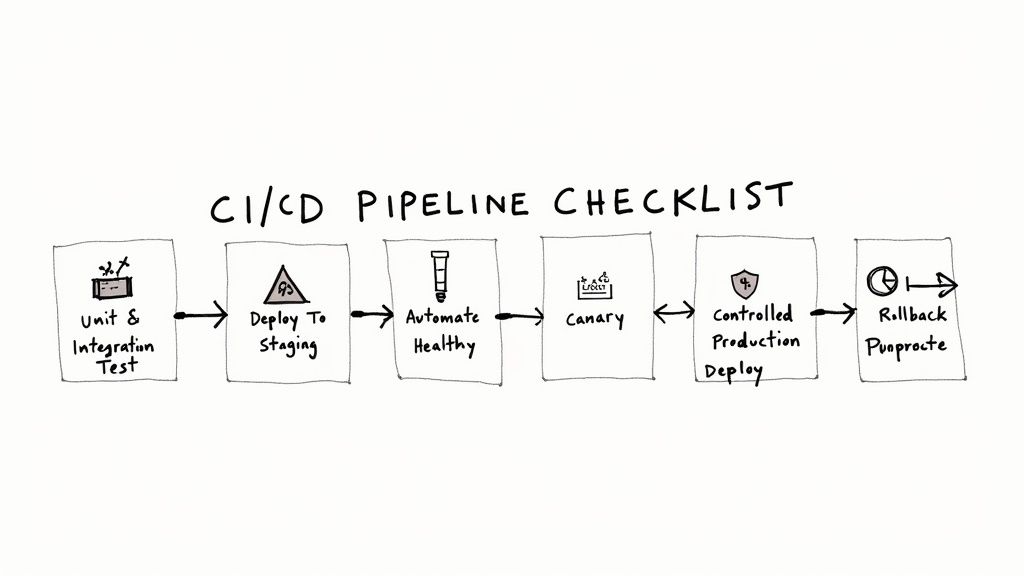
Hardening the CI/CD Pipeline
The CI/CD pipeline is the automation backbone of software delivery. A compromised pipeline can inject vulnerabilities or malicious code into every application it builds. Consultants focus on transforming the pipeline into a secure software factory.
This involves several critical technical implementations:
- Securing Build Agents: Implementing ephemeral, single-use build agents with minimal privileges, network isolation, and continuous vulnerability scanning. This prevents a compromised agent from persisting or accessing other systems. For example, using AWS Fargate or Kubernetes Jobs for build execution ensures a clean environment for every run.
- Implementing Secrets Management: Eradicating hardcoded credentials (API keys, database passwords) from source code and configuration files. This is achieved by integrating the pipeline with a centralized secrets manager like HashiCorp Vault or AWS Secrets Manager. Applications and pipelines fetch credentials at runtime via authenticated API calls, a non-negotiable practice for preventing credential leakage.
- Integrating Security Scanners: Automating security analysis at specific pipeline stages. Static Application Security Testing (SAST) tools (e.g., SonarQube, Snyk Code) are integrated to scan source code on every commit. Software Composition Analysis (SCA) tools (e.g., OWASP Dependency-Check, Trivy) scan dependencies for known CVEs before an artifact is built. For a deep dive, see our guide to secure CI/CD pipelines.
Conducting Infrastructure as Code Security Reviews
Infrastructure as Code (IaC) enables rapid provisioning but also allows a single misconfiguration in a Terraform file to expose entire systems. Consultants implement automated security analysis for IaC templates, treating infrastructure definitions with the same rigor as application code.
Specialized static analysis tools are integrated into the CI pipeline to detect security flaws before deployment:
- Checkov or Terrascan can be configured to scan Terraform, CloudFormation, and Kubernetes manifests for misconfigurations like public S3 buckets, unencrypted databases, or overly permissive IAM roles.
- tfsec provides Terraform-specific analysis, offering actionable feedback directly within a developer's pull request, making it easier to remediate issues pre-merge.
This proactive approach catches infrastructure vulnerabilities at the code review stage, preventing them from ever reaching a live environment.
Technical Example: A consultant configures a CI job that runs
tfsecon every pull request targeting themainbranch. Iftfsecdetects a security group rule allowing unrestricted ingress (0.0.0.0/0) to a sensitive port like 22 or 3389, the pipeline fails, blocking the merge and posting a comment on the PR detailing the exact line of code and remediation steps.
Implementing Automated Compliance and Governance
To automate compliance with standards like SOC 2 or HIPAA, consultants implement Policy-as-Code (PaC). This practice codifies organizational and regulatory policies into machine-enforceable rules.
The primary tool for this is often Open Policy Agent (OPA). Consultants write policies in OPA's declarative language, Rego, to enforce rules across the technology stack. For instance, a Rego policy can be integrated with a Kubernetes admission controller to automatically reject any deployment that attempts to run a container as the root user or mount a sensitive host path.
This transforms compliance from a periodic, manual audit into a continuous, automated enforcement mechanism.
Delivering Threat Modeling as a Service
Threat modeling is a structured process for identifying and mitigating potential security threats during the design phase of an application or feature. Consultants facilitate these sessions, guiding engineering teams to analyze their system architecture from an attacker's perspective.
Using frameworks like STRIDE (Spoofing, Tampering, Repudiation, Information Disclosure, Denial of Service, Elevation of Privilege), they help teams identify potential attack vectors and vulnerabilities. The output is a living document that maps threats to specific components, prioritizes them based on risk, and defines concrete technical mitigations. These mitigations are then translated into user stories and added to the development backlog, ensuring security is addressed from the earliest stage of development.
How to Evaluate and Choose a DevSecOps Partner
Selecting the right partner for DevSecOps consulting services requires a rigorous evaluation of their technical capabilities. You are not hiring a vendor to install software; you are bringing in a strategic engineering partner who will fundamentally alter your development and security practices.
The evaluation must go beyond marketing materials to verify deep, hands-on technical expertise. A qualified partner must demonstrate proficiency with your technology stack, understand your compliance landscape, and deliver measurable security outcomes. The focus should be on validating their technical depth, implementation methodology, and cultural fit. A superior consultant empowers your team by transferring knowledge and implementing sustainable, automated processes, not just installing tools.
Assessing Technical Depth and Real-World Experience
True expertise is demonstrated through a tool-agnostic, problem-solving mindset, not a list of vendor certifications. Consultants must have production experience implementing and managing security in complex, regulated environments.
Key areas to probe:
- Compliance Framework Mastery: Move beyond "we handle compliance." Ask for specific examples. "Describe the architecture you designed for a client to achieve PCI DSS compliance for their Kubernetes environment. What specific controls did you implement at the network, container, and application layers?"
- Hands-On IaC and Pipeline Security: Ask for a technical walkthrough. "Walk us through how you would secure a multi-stage GitLab CI pipeline that builds a container, pushes it to a registry, and deploys to EKS. What specific security tools would you integrate at each stage and why?"
- Case Studies with Measurable Results: Vague claims are a red flag. Demand concrete metrics. Instead of "we improved their security," look for "reduced Mean Time to Remediate (MTTR) for critical vulnerabilities from 28 days to 2 days" or "automated 90% of security evidence collection for a SOC 2 audit."
Choosing the Right Engagement Model
DevSecOps consulting is not one-size-fits-all. The optimal engagement model depends on your team's current maturity, specific technical challenges, and long-term goals.
A critical part of this evaluation involves assessing their communication and responsiveness. It’s important to understand what constitutes effective client follow-up strategies, as this often reflects their overall professionalism and commitment to partnership.
Common engagement structures include:
- Project-Based Statement of Work (SOW): Best for specific, time-bound objectives, such as conducting a security maturity assessment or implementing a secure CI/CD pipeline for a key application. This model provides a fixed scope, timeline, and set of deliverables.
- Long-Term Advisory Retainer: Ideal for ongoing strategic guidance. The consultant functions as a fractional CISO or Principal Security Engineer, providing continuous oversight, mentoring teams on secure coding practices, and evolving the security roadmap.
- Team Augmentation: An embedded model where one or more consultant engineers join your team to fill a specific skill gap (e.g., cloud security, pipeline automation). This model is highly effective for hands-on knowledge transfer and accelerating project timelines. To understand this better, compare the roles of a top-tier DevOps consulting company.
DevSecOps Vendor Evaluation Checklist
This checklist provides a structured framework for evaluating and comparing potential DevSecOps consultants to ensure a technically sound decision.
| Evaluation Criterion | What to Look For | Red Flags to Avoid |
|---|---|---|
| Technical Expertise | Deep, hands-on experience with your specific stack (e.g., AWS, GCP, Kubernetes, GitHub Actions). | Vague answers, reliance on buzzwords, inability to discuss technical trade-offs. |
| Proven Methodology | A clear, repeatable process for assessment, implementation, and knowledge transfer. | An ad-hoc "we'll figure it out as we go" approach. |
| Real-World Case Studies | Concrete examples with measurable KPIs (e.g., "reduced vulnerability escape rate by X%"). | Anecdotal success stories without specific data or metrics. |
| Tool-Agnostic Approach | Recommends tools based on technical merit and your needs, not vendor partnerships. | Pushing a specific commercial tool before a thorough analysis of your environment. |
| Compliance Knowledge | Verifiable experience implementing controls for specific frameworks (HIPAA, PCI DSS, SOC 2). | A surface-level understanding of compliance requirements without implementation details. |
| Cultural Fit & Communication | Ability to communicate complex technical concepts clearly to engineers and leadership. | Arrogance, condescending attitude, or an unwillingness to collaborate with your team. |
| Client References | Eager to provide references from projects with similar technical challenges and scope. | Hesitation, or providing references from unrelated projects. |
By systematically applying this checklist, you can objectively assess each vendor's capabilities and select a partner equipped to deliver tangible security improvements.
Probing Questions to Validate Expertise
To differentiate true experts from sales engineers, ask pointed technical questions that require practical, experience-based answers.
- "Describe your process for tuning a SAST tool to reduce its false-positive rate. How do you balance signal vs. noise to maintain developer trust and adoption?"
- "How would you design a secrets management strategy for a microservices architecture running on Kubernetes in a multi-cloud environment? What are the trade-offs between solutions like HashiCorp Vault and native cloud offerings like AWS Secrets Manager?"
- "Walk us through your methodology for conducting a threat modeling workshop for a new serverless application. What specific artifacts would we receive, and how would they be integrated into our development backlog?"
How DevSecOps Consulting Engagements Actually Work
Engaging a DevSecOps consulting service is a technical partnership. Understanding the structure of this partnership—the engagement model—is critical for achieving measurable results. The model must align with your current technical maturity and immediate objectives. It's crucial to understand the differences between approaches like staff augmentation vs consulting, as this choice dictates the engagement's scope and outcomes.
Let’s dissect the two most common engagement models and the specific technical deliverables you should expect from each. This ensures transparency and a clear definition of success.
The typical engagement flow is sequential: it begins with a deep technical assessment, proceeds to hands-on implementation, and concludes with the delivery of concrete, operational assets.
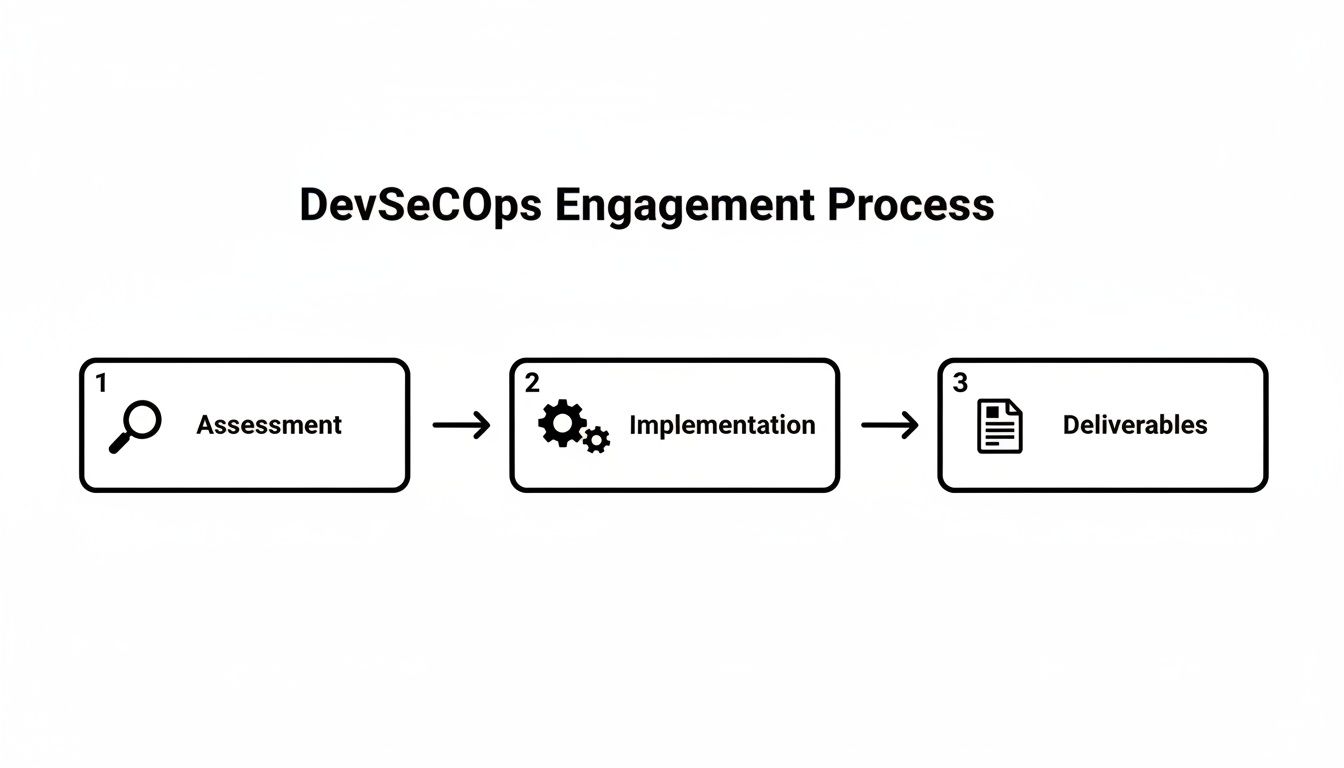
This structured approach ensures that implementation efforts are based on a thorough understanding of your specific environment, not generic best practices.
Model 1: The Maturity Assessment and Strategic Roadmap
If you lack clarity on your security posture and vulnerabilities, a maturity assessment is the logical starting point. This is a comprehensive technical audit of your entire SDLC. The consultant functions as a security architect, mapping your current processes, tools, and culture against established industry frameworks.
The goal is not merely to identify weaknesses but to produce a prioritized, actionable roadmap that answers the question: "What are the most impactful security investments we can make, and in what order?"
A maturity assessment transforms ambiguous security concerns into a concrete, phased implementation plan. Every recommendation is justified with technical reasoning and tied to a specific risk reduction.
Key Technical Deliverables:
- DevSecOps Maturity Scorecard: A quantitative assessment based on a framework like OWASP SAMM or BSIMM, providing a clear baseline of your capabilities across domains like Governance, Design, Implementation, and Verification.
- Prioritized Remediation Report: A technical document detailing identified vulnerabilities and process gaps, ranked by risk (e.g., using the DREAD model) and implementation effort. Each finding includes specific remediation guidance.
- 12-Month Technical Roadmap: A quarter-by-quarter plan with explicit technical milestones. For example: "Q1: Integrate SAST scanning with pull request feedback in all Tier-1 application repositories. Q3: Implement Policy-as-Code to enforce TLS on all Kubernetes Ingress resources."
Model 2: The Hands-On Pipeline Implementation
This model is designed for organizations with a clear objective: build a secure CI/CD pipeline or harden an existing one. The consultant transitions from an architect to a hands-on implementation engineer, embedding with your team to build and configure security controls directly within your toolchain.
This is a code-centric engagement where success is measured by the deployment of live, automated security gates and guardrails within your production pipelines.
Key Technical Deliverables:
- Secured Pipeline Configurations: Production-ready, version-controlled pipeline definitions (e.g.,
gitlab-ci.yml, GitHub Actions workflows,Jenkinsfile) with integrated security scanning stages. - Policy-as-Code (PaC) Artifacts: Functional Rego policies for Open Policy Agent (OPA) or configuration rules for tools like Checkov, designed to enforce your specific security and compliance requirements on IaC and Kubernetes manifests.
- Integrated Security Dashboards: A centralized vulnerability management dashboard (e.g., in DefectDojo or a SIEM) configured to ingest, de-duplicate, and display findings from all integrated scanning tools.
- Team Runbooks and Training: Comprehensive documentation and hands-on workshops to empower your engineers to operate, maintain, and extend the new security controls independently.
Building Your DevSecOps Implementation Roadmap
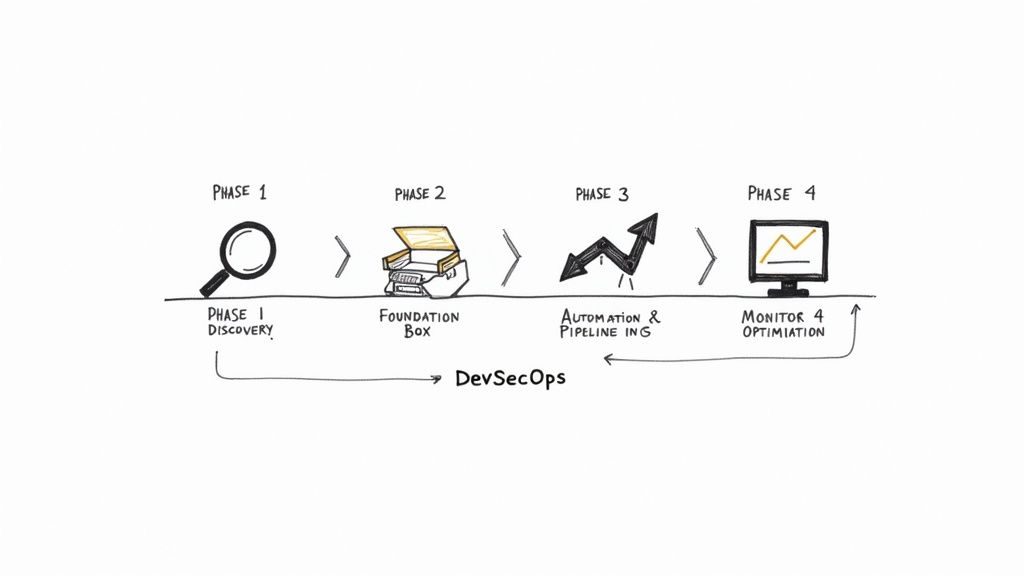
A successful DevSecOps implementation requires a structured, phased roadmap. Attempting a "big bang" overhaul is disruptive and prone to failure. A logical, phased approach builds a solid foundation, delivers incremental value, and maintains momentum without overwhelming engineering teams.
The process moves from discovery and baselining to foundational tool integration, followed by advanced automation and continuous monitoring. Each phase builds upon the last, culminating in a resilient, efficient, and secure SDLC. This methodology is particularly effective for small and medium-sized businesses, which are adopting DevSecOps at an 18.5% CAGR to counter increasing threats.
Globally, organizations with mature DevSecOps practices achieve 3x faster secure software releases. This competitive advantage is crucial in an environment where the annual cost of cybercrime is projected to hit $10.5 trillion. You can find more market data from Verified Market Research.
Phase 1 Discovery and Baseline Assessment
The initial phase involves a thorough technical discovery to map your current SDLC, toolchain, and security posture. This intelligence-gathering stage is crucial for informed decision-making in subsequent phases. It includes technical interviews with developers and operations staff, as well as audits of CI/CD pipelines and cloud environments.
Technical Milestones:
- Document the end-to-end SDLC, from code commit to production deployment, identifying all tools and manual handoffs.
- Execute initial vulnerability scans (SAST, SCA, DAST) against key applications to establish a quantitative security baseline.
- Perform a security review of existing IaC templates (Terraform, CloudFormation) to identify critical misconfigurations.
The primary deliverable is a technical report detailing your current security maturity, identifying critical gaps, and proposing a high-level implementation plan.
Phase 2 Foundation and Toolchain Integration
With a clear baseline established, this phase focuses on integrating foundational security tools into the developer's immediate workflow. The goal is to "shift left" by providing developers with fast, actionable security feedback within their existing tools (IDE, Git, CI system).
This is where cultural transformation begins, as security becomes a visible and integrated part of the daily development process.
Technical Note: The success of this phase hinges on the quality of the feedback loop. Tools must be configured to provide low-noise, high-signal alerts. If developers are inundated with false positives, they will ignore the tooling, rendering it ineffective.
Technical Milestones:
- Integrate a Static Application Security Testing (SAST) tool into CI builds for feature branches, providing feedback directly in pull requests.
- Implement Software Composition Analysis (SCA) to scan third-party dependencies for known vulnerabilities on every build.
- Introduce a secrets detection tool (e.g., Git-leaks, TruffleHog) as a pre-commit hook and a CI pipeline step to prevent credentials from being committed to repositories.
Phase 3 Pipeline Automation and Policy Enforcement
This phase builds on the foundational tools by automating security enforcement within the CI/CD pipeline. The focus shifts from simply notifying developers of issues to actively blocking insecure code from progressing to production. Policy-as-Code is implemented to enforce security and compliance rules automatically.
Consider the case of "Innovate Inc." They transitioned from manual security reviews to an automated pipeline that failed any build containing a critical CVE or a hardcoded secret. A key challenge was tuning the SAST tool to eliminate false positives; this was solved by developing a custom ruleset tailored to their specific codebase and risk profile. The result was a 50% reduction in critical vulnerabilities reaching production within six months.
Technical Milestones:
- Configure the CI/CD pipeline to "break the build" if security scans exceed a predefined risk threshold (e.g., >0 critical vulnerabilities).
- Deploy Dynamic Application Security Testing (DAST) scans to run automatically against applications in a staging environment post-deployment.
- Implement policy-as-code using tools like Open Policy Agent (OPA) to enforce infrastructure security standards (e.g., ensuring all S3 buckets block public access).
Phase 4 Continuous Optimization and Observability
This is an ongoing phase focused on continuous improvement. With a secure, automated pipeline in place, the focus shifts to advanced threat detection, security observability, and tightening the feedback loop. Production security events are monitored and the intelligence is fed back into the development lifecycle to proactively address threats.
Technical Milestones:
- Aggregate logs and events from all security tools into a centralized observability platform (e.g., a SIEM or logging solution like Splunk or ELK Stack) for unified analysis and alerting.
- Implement container security scanning in the registry (on push) and at runtime (using agents like Falco or Aqua Security).
- Establish a formal process for conducting threat modeling workshops for all new features or services.
This continuous feedback loop ensures your security posture evolves to meet new threats, maximizing the long-term value of your DevSecOps consulting services engagement.
Got Questions About DevSecOps Consulting? We've Got Answers.
Engaging with DevSecOps consulting services often brings up practical questions about scope, cost, and ROI. Here are technical answers to the most common inquiries.
How Long Does a Typical Engagement Last?
The duration is dictated by the scope. A focused Maturity Assessment and Strategic Roadmap is typically a 4 to 6-week engagement. This involves deep-dive analysis and results in a detailed, actionable plan.
A hands-on Secure CI/CD Pipeline Implementation usually requires 3 to 6 months, depending on the complexity of your environment and the number of pipelines in scope. For large-scale enterprises with complex regulatory needs, engagements can extend to 12 months or more, often transitioning into an ongoing advisory retainer for continuous improvement.
Can We Use Our Existing Tools?
Yes, this is the preferred approach. A competent consultant leverages and optimizes your existing toolchain first. Their initial objective is to maximize the value of your current investments.
Whether your ecosystem is built on Jenkins, GitLab CI, or GitHub Actions, the first step is to integrate security controls into those existing workflows. New tools are only recommended when there is a clear capability gap that cannot be filled by existing systems, or when a new tool offers a significant ROI in terms of risk reduction or operational efficiency. The goal is seamless integration, not a disruptive "rip and replace."
Technical Insight: A consultant's value is often demonstrated by their ability to make your existing tools more effective. For example, instead of replacing your logging tool, they might build custom parsers and correlation rules to better detect security events. Immediate recommendations for a full toolchain replacement without a deep technical justification should be viewed with skepticism.
What Is the Typical Cost of DevSecOps Consulting?
Costs vary based on the engagement model. For time-and-materials contracts, hourly rates for senior DevSecOps engineers typically range from $150 to over $400.
Fixed-price projects are common for well-defined scopes. A Security Maturity Assessment may cost between $20,000 and $40,000. A full CI/CD pipeline security implementation can range from $80,000 to $250,000+. Always demand a detailed Statement of Work (SOW) that explicitly defines all activities, technical deliverables, and costs to avoid scope creep and budget overruns.
How Do We Measure the ROI of an Engagement?
The ROI of a DevSecOps engagement must be measured using specific, quantifiable metrics. Track these KPIs from the beginning to demonstrate tangible improvement.
Key Technical KPIs:
- Vulnerability Escape Rate: The percentage of vulnerabilities discovered in production versus those caught pre-production. This should decrease significantly.
- Mean-Time-to-Remediate (MTTR): The average time taken to fix a detected vulnerability. A successful engagement will drastically reduce this time.
- Deployment Frequency: The rate at which you can deploy to production. With security bottlenecks removed, this metric should increase.
Key Business Metrics:
- Cost Avoidance: The estimated cost of security breaches that were prevented, calculated using industry data (e.g., average cost per record breached).
- Compliance Adherence: Reduced time and cost for audits, and avoidance of non-compliance penalties.
- Time-to-Market: The speed at which new features are delivered to customers. Removing security as a blocker directly accelerates this, providing a competitive edge.
Ready to build a security-first culture without slowing down your developers? At OpsMoon, we provide the expert DevSecOps engineers you need to harden your pipelines and protect your infrastructure. Start with a free work planning session today to map out your secure software delivery roadmap.