DevOps Quality Assurance isn't just a new set of tools; it's a fundamental, technical shift in how we build and validate software. It integrates automated testing and quality checks directly into every stage of the software development lifecycle, managed and versioned as code.
Forget the legacy model where quality was a separate, manual phase at the end. In a DevOps paradigm, quality becomes a shared, continuous, and automated responsibility. Everyone, from developers writing the first line of code to the SREs managing production infrastructure, is accountable for quality. This collective, code-driven ownership is the key to releasing better, more reliable software, faster.
The Cultural Shift from QA Gatekeeper to Quality Enabler
In traditional waterfall or agile-ish environments, QA teams often acted as the final gatekeeper. Developers would code features, then ceremoniously "throw them over the wall" to a QA team for a multi-day or week-long manual testing cycle.
This created a high-friction, low-velocity workflow. QA was perceived as a bottleneck, and developers were insulated from the immediate consequences of bugs until late in the cycle. This siloed approach is technically inefficient and means critical issues are often found at the last minute, making them exponentially more expensive and complex to fix due to the increased context switching and debugging effort.
DevOps Quality Assurance completely tears down those walls.
Picture a high-performance pit crew during a race. Every single member has a critical, well-defined job, and they all share one goal: get the car back on the track safely and quickly. The person changing the tires is just as responsible for the outcome as the person refueling the car. A mistake by anyone jeopardizes the entire team. That's the DevOps approach to quality—it's not one person's job, it's everyone's.
From Silos to Shared Ownership
This cultural overhaul completely redefines the role of the modern QA professional. They are no longer manual testers ticking off checklists in a test management tool. Instead, they become quality enablers, coaches, and automation architects.
Their primary technical function shifts to building the test automation frameworks, CI/CD pipeline configurations, and observability dashboards that empower developers to test their own code continuously and effectively. This is the heart of the "shift-left" philosophy—integrating quality activities as early as possible into the development process, often directly within the developer's IDE and the CI pipeline.
The business impact of this is huge. The data doesn't lie: a staggering 99% of organizations that adopt DevOps report positive operational improvements. Digging deeper, 61% specifically point to higher quality deliverables, drawing a straight line from this cultural change to a better product.
DevOps QA isn't about testing more; it's about building a system where quality is an intrinsic, automated part of the delivery pipeline, enabling faster, more confident releases.
This approach transforms the entire software development lifecycle. You can learn more about the principles that drive this change by understanding the core DevOps methodology. The ultimate goal is to create a tight, rapid feedback loop where defects are found and fixed moments after they're introduced—not weeks or months down the line. This proactive stance is what truly sets modern DevOps quality assurance apart from the old way of doing things.
To see just how different these two worlds are, let's put them side-by-side.
Traditional QA vs DevOps Quality Assurance At a Glance
The table below breaks down the core differences between the old, siloed model and the modern, integrated approach. It highlights the profound changes in timing, responsibility, and overall mindset.
| Aspect | Traditional QA | DevOps QA |
|---|---|---|
| Timing | A separate phase at the end of the cycle | Continuous, integrated throughout the lifecycle |
| Responsibility | A dedicated QA team owns quality | The entire team (devs, ops, QA) shares ownership |
| Goal | Find defects before release (Gatekeeping) | Prevent defects and enable speed (Enabling) |
| Process | Mostly manual testing, some automation | Heavily automated, focused on "shift-left" |
| Feedback Loop | Long and slow (weeks or months) | Short and fast (minutes or hours) |
| Role of QA | Acts as a gatekeeper or validator | Acts as a coach, enabler, and automation expert |
As you can see, the move to DevOps QA isn't just an incremental improvement; it’s a complete re-imagining of how quality is achieved. It’s about building quality in, not inspecting it on at the very end.
The Four Pillars of a DevOps QA Strategy
To effectively embed quality into your DevOps lifecycle, your strategy must be built on four core, technical pillars. These aren't just concepts; they represent a fundamental shift in how we write, validate, and deploy software. By implementing these four pillars, you can transition from a reactive, gate-based quality model to a proactive and continuous one.
This diagram nails the difference between the old way and the new way. It's all about moving from a siloed, traditional QA model to a DevOps approach grounded in shared responsibility.
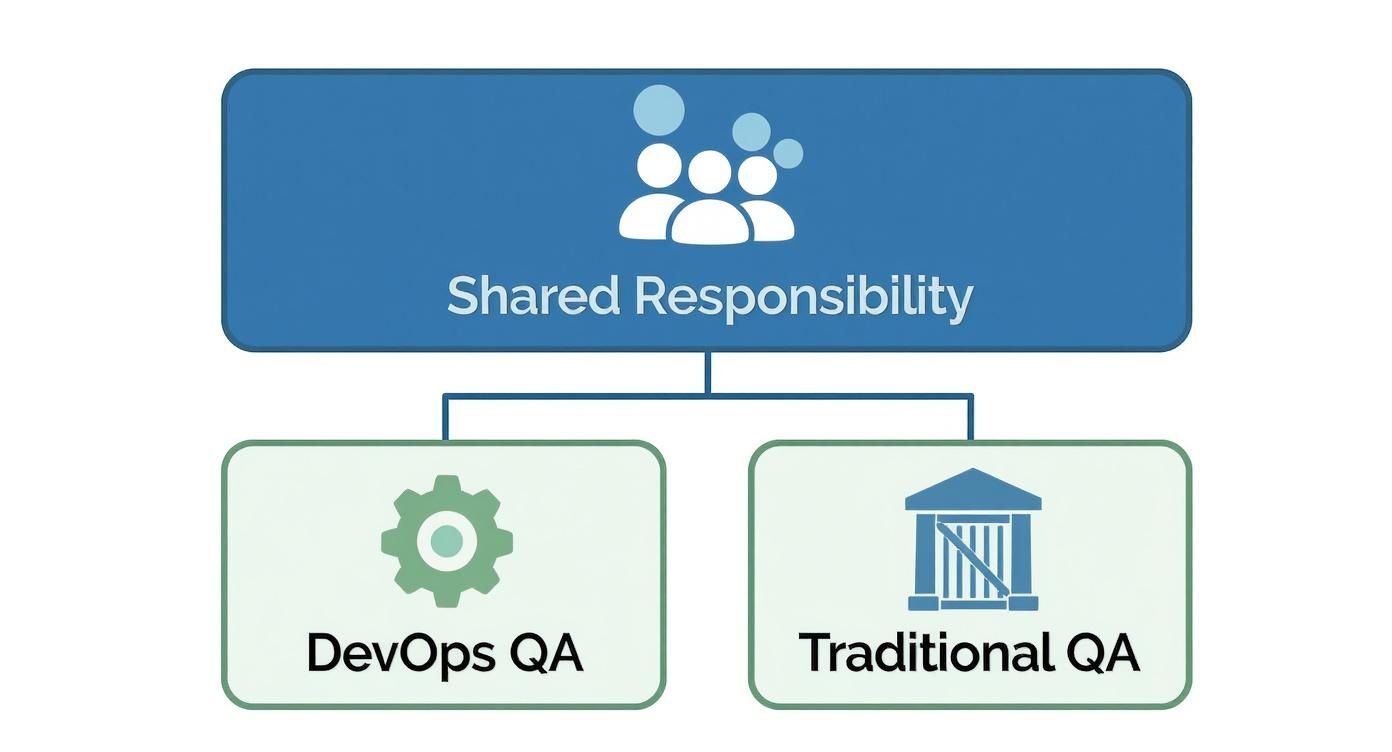
You can see that traditional QA acts as a separate gatekeeper. DevOps QA, on the other hand, is an integrated part of the team’s shared ownership, which makes for a much smoother workflow.
Shifting Left
The first and most powerful pillar is Shifting Left. This is the practice of moving quality assurance activities as early as possible into the development process. Instead of waiting for a feature to be "code complete" before QA sees it, quality becomes part of the development workflow itself.
This means QA professionals get involved during requirements and design, helping define BDD (Behavior-Driven Development) feature files and acceptance criteria. Testers collaborate with developers to design for testability, for example, by ensuring API endpoints are easily mockable or UI components have stable selectors (data-testid attributes).
A concrete technical example is a developer using a static analysis tool like SonarQube integrated directly into their IDE via a plugin. This provides real-time feedback on code quality, security vulnerabilities (e.g., SQL injection risks), and code smells as they type. That immediate feedback is exponentially cheaper and faster than discovering the same issue in a staging environment weeks later. To really get a handle on this concept, check out our deep dive on what is shift left testing.
Continuous Testing
The second pillar, Continuous Testing, is the automated engine that drives a modern DevOps QA strategy. It involves executing automated tests as a mandatory part of the CI/CD pipeline. Every git push triggers an automated sequence of builds and tests, providing immediate feedback on the health of the codebase.
This doesn't mean running a 4-hour E2E test suite on every commit. The key is to layer tests strategically throughout the pipeline to balance feedback speed with test coverage. A typical pipeline might look like this:
- On Commit: The pipeline runs lightning-fast unit tests (
go test ./...), linters (eslint .), and static analysis scans. Feedback in < 2 minutes. - On Pull Request: Broader integration tests are executed, often using Docker Compose to spin up the application and its database dependency. This ensures new code integrates correctly. Feedback in < 10 minutes.
- Post-Merge/Nightly: Slower, more comprehensive end-to-end and performance tests run against a persistent, fully-deployed staging environment.
This constant validation loop catches regressions moments after they’re introduced, preventing them from propagating downstream where they become significantly harder to debug and resolve.
Continuous Testing transforms quality from a distinct, scheduled event into an ongoing, automated process that runs in parallel with development. No build moves forward with known regressions.
Smart Test Automation
Building on continuous testing, our third pillar is Smart Test Automation. This is about more than just writing test scripts; it's about architecting a resilient, maintainable, and valuable test suite. The guiding principle here is the Test Automation Pyramid.
The pyramid advocates for a large base of fast, isolated unit tests, a smaller middle layer of integration tests that validate interactions between components (e.g., service-to-database), and a very small top layer of slow, often brittle end-to-end (E2E) UI tests. Adhering to this model results in a test suite that is fast, reliable, and cost-effective to maintain.
For example, instead of writing dozens of E2E tests that simulate a user logging in through the UI, you'd have one or two critical-path UI tests. The vast majority of authentication logic would be covered by much faster and more stable API-level and unit tests that can be run in parallel.
Infrastructure as Code Validation
The final pillar addresses a common source of production failures: environmental discrepancies. Infrastructure as Code (IaC) Validation is the practice of applying software testing principles to the code that defines your infrastructure—whether it's written in Terraform, Ansible, or CloudFormation.
Just like application code, your IaC must be linted, validated, and tested. Without this, "environment drift" occurs, where dev, staging, and production environments diverge, causing deployments to fail unpredictably.
Tools like Terratest (for Terraform) or InSpec allow you to write automated tests for your infrastructure. A simple Terratest script written in Go might:
- Execute
terraform applyto provision a temporary AWS S3 bucket. - Use the AWS SDK to verify the bucket was created with the correct encryption and tagging policies.
- Check that the associated security group was created with the correct ingress/egress rules.
- Execute
terraform destroyto tear down all resources, ensuring a clean state.
By validating your IaC, you guarantee that every environment is provisioned identically and correctly, providing a stable, reliable foundation for your application deployments.
Building an Integrated DevOps QA Toolchain
An effective DevOps quality assurance strategy is powered by a well-integrated collection of tools working in concert. This toolchain is the technical backbone of your CI/CD pipeline, automating the entire workflow from a git commit to a validated feature running in production. A disjointed set of tools creates friction, slows down feedback, and undermines the velocity you're striving for.
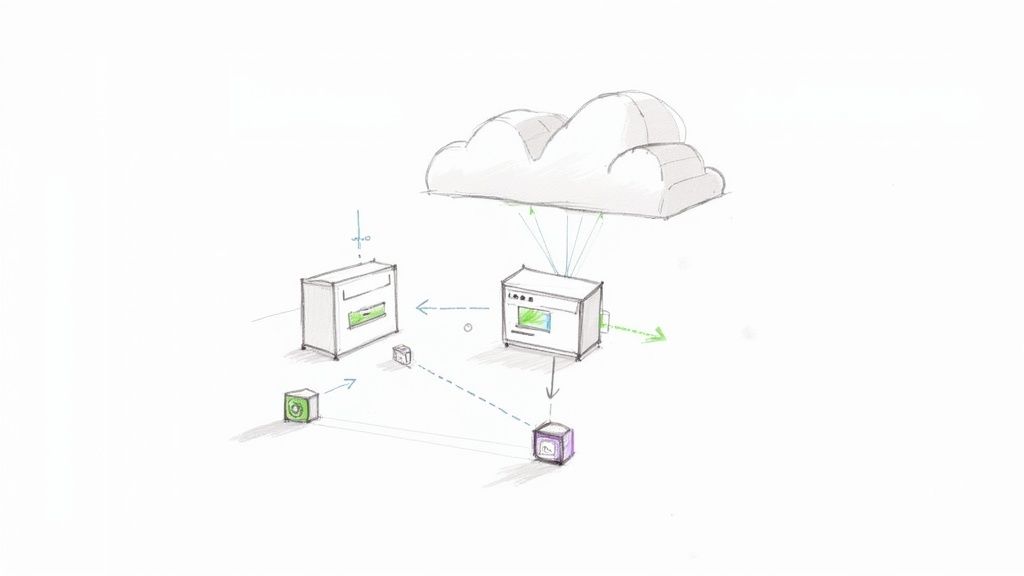
Conversely, a seamless toolchain acts as a "quality nervous system." An event in one part of the system—like a GitHub pull request—instantly triggers a reaction in another, like a Jenkins pipeline run. The goal is to create an automated, observable, and reliable path to production where quality checks are embedded, not bolted on.
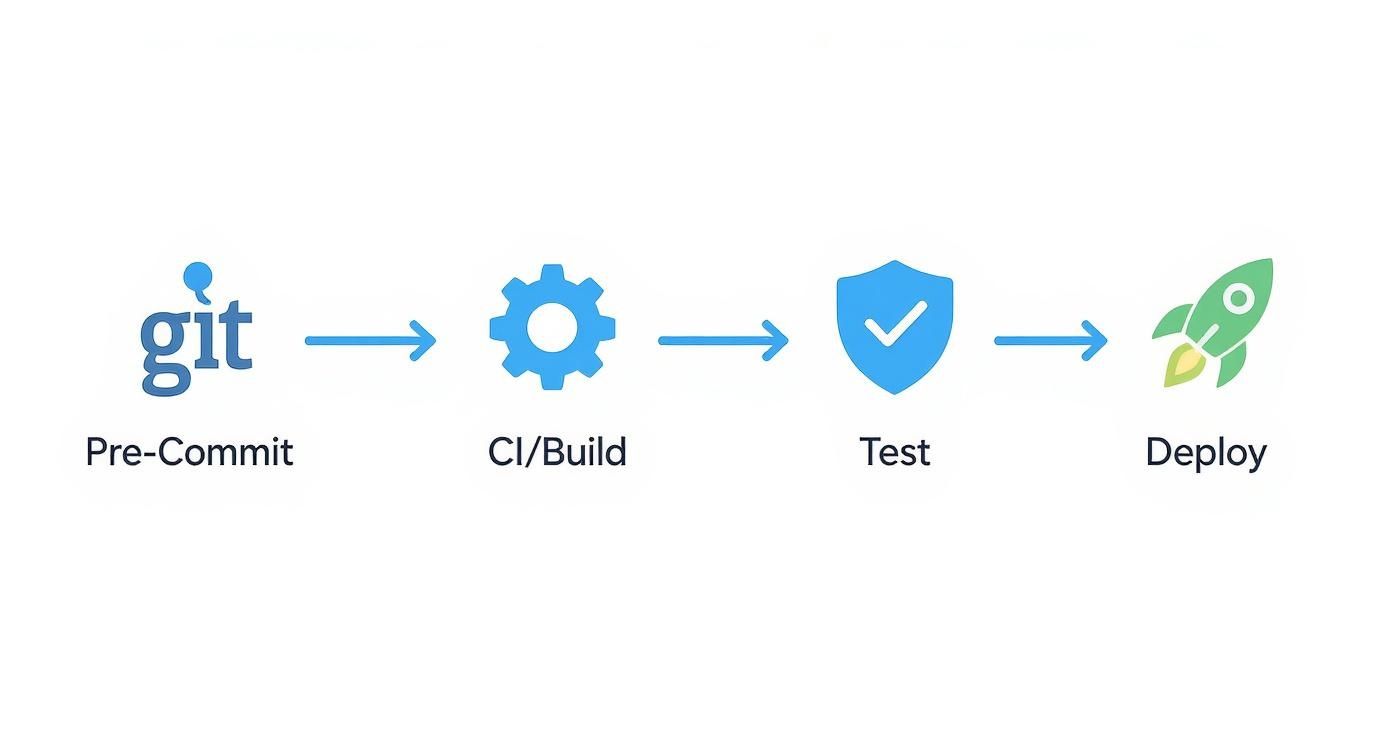
This diagram gives a great high-level view of how a CI/CD pipeline brings different tools together to automate both testing and monitoring.
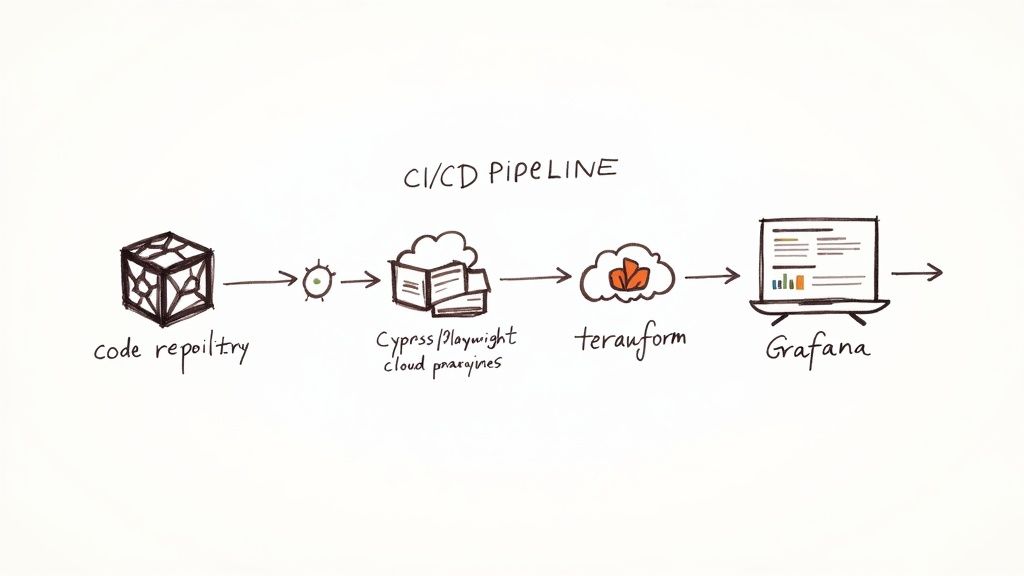
You can see how code moves from the repository through various automated stages, with observability tools providing a constant feedback loop.
Key Components of a Modern QA Toolchain
To build this kind of integrated system, you need specific tools for each stage of the lifecycle. A solid DevOps QA toolchain depends heavily on automation, and understanding the overarching benefits of workflow automation can make it much easier to justify investing in the right tools.
-
CI/CD Orchestrators: These are the pipeline engines. Tools like Jenkins, GitLab CI, or GitHub Actions execute declarative pipeline definitions (e.g.,
Jenkinsfile,.gitlab-ci.yml,.github/workflows/main.yml) to build, test, and deploy applications. -
Testing Frameworks: This is where validation logic lives. You have frameworks like Cypress or Playwright for robust end-to-end browser automation. For unit and integration tests, you’ll use language-specific tools like JUnit for Java or Pytest for Python.
-
Containerization and IaC: Tools like Docker are non-negotiable for creating consistent, portable application environments. Infrastructure is defined as code using tools like Terraform, which guarantees that dev, staging, and prod environments are identical and reproducible.
-
Observability Platforms: Post-deployment, you need visibility into application behavior. This is where tools like Prometheus scrape metrics, logs are aggregated (e.g., with the ELK stack), and Grafana provides visualization dashboards, giving real-time insight into performance and health.
Weaving the Tools Together in Practice
The real power is unleashed when these tools are integrated into a cohesive workflow. Automated testing has become a cornerstone of modern DevOps QA, with nearly 85% of organizations globally using it to improve software quality. This isn't just a trend; it's a fundamental shift in how teams manage quality.
Let's walk through a technical example using GitHub Actions. When a developer opens a pull request, the .github/workflows/ci.yml file triggers the pipeline:
- Build Stage: A workflow job checks out the code, sets up the required language environment (e.g., Node.js), and runs
npm run buildto compile the application. The resulting artifacts are uploaded for later stages. - Test Stage: A separate job, often running in parallel, uses
docker-compose upto launch the application and a test database. It then executes a suite of Playwright E2E tests against the ephemeral environment. Test results (e.g., JUnit XML reports) are published. To get this step right, it’s critical to properly automate your software testing. - Deploy Stage: If tests pass and the PR is merged to
main, a separate workflow triggers. This job uses Terraform Cloud credentials to runterraform apply, deploying the new application version to a staging environment on AWS. - Monitoring Feedback: The application, running in its Terraform-managed environment, is already configured with a Prometheus client library to expose metrics on a
/metricsendpoint. A Prometheus server scrapes this endpoint, and any anomalies (e.g., increased HTTP 500 errors) trigger an alert in Alertmanager, closing the feedback loop.
This flow is what a true DevOps quality assurance process looks like in action. Quality isn't just checked at a single gate; it's validated continuously through an automated, interconnected toolchain that gives you fast, reliable feedback every step of the way.
Measuring the Success of Your DevOps QA
If you’re not measuring, you’re just guessing. In DevOps quality assurance, metrics are not vanity numbers for a report; they are critical signals indicating the health of your delivery pipeline. Tracking the right key performance indicators (KPIs) allows you to make data-driven decisions to optimize your processes.
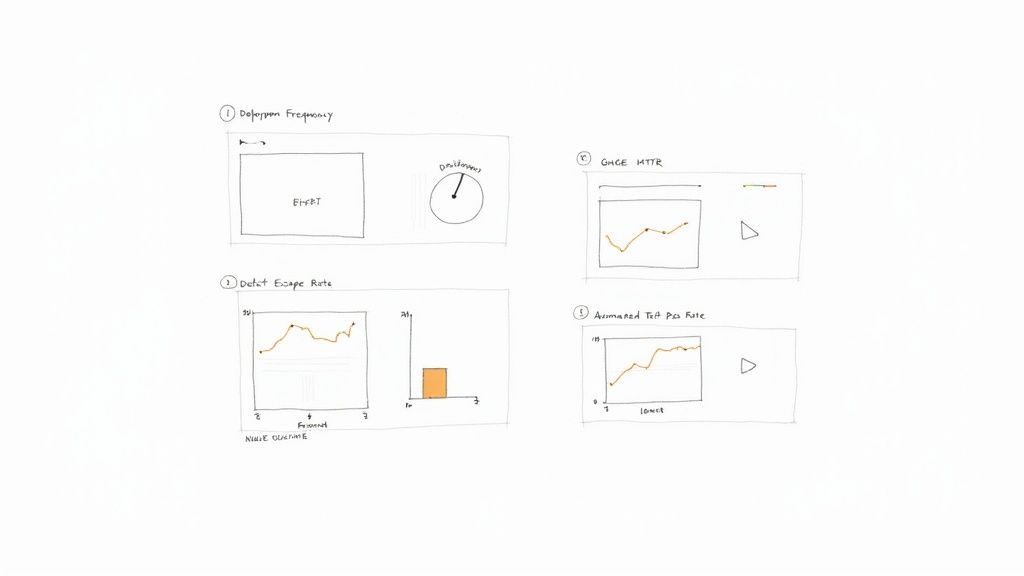
This is about moving beyond vanity metrics—like lines of code written or the raw number of tests run—and focusing on KPIs that directly measure your pipeline's velocity, stability, and production quality.
Gauging Pipeline Velocity and Resilience
A successful DevOps practice is built on two pillars: how fast you can deliver value and how quickly you can recover from failure. The DORA metrics are the industry standard for measuring this.
Mean Time to Recovery (MTTR) is arguably the most critical metric for operational stability. It measures the average time from a production failure detection to full restoration of service. A low MTTR is the hallmark of a resilient system with mature observability and incident response practices.
To improve MTTR, implement these technical solutions:
- Structured Logging & Alerting: Ensure your applications output structured logs (e.g., JSON) and have robust alerting rules in Prometheus/Alertmanager to detect issues proactively.
- Automated Rollbacks: Design your deployment pipeline with a one-click or automated rollback capability. For example, a canary deployment that fails health checks should automatically roll back to the previous stable version.
- Chaos Engineering: Use tools like Gremlin to intentionally inject failures (e.g., network latency, pod termination) into your staging environment to practice and harden your incident response.
Another key DORA metric is Deployment Frequency. This measures how often your organization successfully releases to production. High-performing teams deploy on-demand, often multiple times per day, signaling a highly automated, low-risk delivery process.
Tracking Production Quality and User Impact
Ultimately, DevOps QA aims to deliver a reliable product to customers. These metrics directly reflect the impact of your quality efforts on the end-user experience.
The Defect Escape Rate measures the percentage of bugs discovered in production rather than during the pre-release testing phases. A high rate indicates that your automated test coverage has significant gaps or that your shift-left strategy is ineffective.
A rising Defect Escape Rate is a serious warning sign. It tells you that your automated test suites have blind spots or your manual exploratory testing isn’t focused on the right areas. This directly erodes user trust and damages your brand's reputation.
The Change Failure Rate is the percentage of deployments to production that result in a degraded service and require remediation (e.g., a rollback, hotfix). Elite DevOps teams maintain a change failure rate below 15%. A high rate points to inadequate testing, unstable infrastructure, or a flawed release process.
To truly understand your quality posture, you need to track a combination of these metrics. Here’s a quick breakdown of the essentials:
Essential DevOps QA Metrics
| Metric | Definition | What It Measures |
|---|---|---|
| Mean Time to Recovery (MTTR) | The average time it takes to restore service after a production failure. | The resilience and stability of your system and the effectiveness of your incident response. |
| Deployment Frequency | How often code is deployed to production. | The speed and efficiency of your delivery pipeline. A higher frequency suggests a more mature process. |
| Defect Escape Rate | The percentage of defects discovered in production instead of pre-release testing. | The effectiveness of your "shift-left" testing and overall quality gates. |
| Change Failure Rate | The percentage of deployments that result in a production failure. | The quality of your release process and the stability of your code and infrastructure. |
| Automated Test Pass Rate | The percentage of automated tests that pass on a given run. | The health and reliability of your test suite itself. A low rate can indicate "flaky" tests. |
Tracking these KPIs provides a holistic view, moving you from simply measuring activity to understanding the real-world impact of your quality initiatives.
Evaluating Test Efficacy and Process Health
It's easy to get caught up in the numbers, but not all tests are created equal. You need to measure the effectiveness of your testing strategy and the health of your automation to ensure your pipeline remains trustworthy.
A common pitfall is chasing 100% Code Coverage. While a useful indicator, it's often a vanity metric. A test suite can achieve high coverage by touching every line of code without asserting any meaningful business logic. A better approach is focusing on Critical Path Coverage, ensuring that your most important user journeys and business-critical API endpoints are thoroughly tested.
Finally, rigorously monitor your Automated Test Pass Rate. A consistently low rate often indicates "flaky tests"—tests that fail intermittently due to factors like network latency or race conditions, not actual code defects. Flaky tests are toxic because they erode developer trust in the CI pipeline, leading them to ignore legitimate failures. Actively identify, quarantine, and fix flaky tests to maintain a reliable and fast feedback loop.
Your Roadmap to Implementing DevOps QA
Transitioning to a mature DevOps QA practice is a strategic, iterative process. You need a clear, phased roadmap that builds momentum without disrupting current delivery cycles. This roadmap provides a technical blueprint, guiding you from assessment to continuous optimization.
Phase 1: Baseline and Assess
Before you can engineer a better process, you must quantify your current state. This phase is about discovery and data collection. The goal is to create a data-driven, objective assessment of your existing workflows, toolchains, and team capabilities.
Start by mapping your entire software delivery value stream, from idea to production. Identify manual handoffs, long feedback loops, and testing bottlenecks. This is a technical audit, not just a process review.
Your Practical Checklist:
- Audit Your Toolchain: Document every tool for version control (Git provider), CI/CD (Jenkins, GitLab CI), testing (frameworks, runners), and observability (monitoring, logging). Identify integration gaps.
- Analyze Key Metrics: Instrument your pipelines to collect baseline DORA metrics: Deployment Frequency, Change Failure Rate, and Mean Time to Recovery (MTTR). This is your "before" state.
- Interview Your Teams: Conduct structured interviews with developers, QA engineers, and SREs. Identify specific technical friction points (e.g., "Our E2E test suite takes 2 hours to run locally").
Phase 2: Pilot and Prove
With a clear baseline, select a single pilot project to demonstrate the value of DevOps QA. A "big bang" approach is doomed to fail due to organizational inertia. Instead, choose one high-impact, low-risk project to build early momentum and create internal champions.
This pilot serves as your proof-of-concept. A good candidate is a new microservice or a well-contained component of a monolith where you can implement a full CI/CD pipeline with integrated testing.
The success of your pilot project is your internal marketing campaign. It provides the concrete evidence needed to secure buy-in from leadership and inspire other teams to adopt new practices.
The focus here is on a measurable "quick win." For example, demonstrate that integrating automated tests into the CI pipeline reduced the regression testing cycle for the pilot component from 3 days to 15 minutes.
Phase 3: Standardize and Scale
With a successful pilot, it's time to scale what you've learned. This phase is about standardizing the tools, frameworks, and pipeline patterns that proved effective. You are creating a "paved road"—a set of repeatable, well-supported blueprints that enable other teams to adopt best practices easily.
This involves building reusable infrastructure and sharing knowledge, not just writing documents.
Your Practical Checklist:
- Establish a Toolchain Standard: Officially adopt and support a primary toolchain based on the pilot's success (e.g., GitLab CI, Cypress, Terraform).
- Create Reusable Pipeline Templates: Build CI/CD pipeline templates (e.g., GitLab CI includes, GitHub Actions reusable workflows) that other teams can import and extend. This ensures consistent quality gates across the organization.
- Develop a Center of Excellence: Form a small, dedicated team of experts to act as internal consultants. Their role is to help other teams adopt the standard toolchain and overcome technical hurdles.
Phase 4: Optimize and Innovate
You've built a scalable foundation. Now the goal is continuous improvement. This phase involves moving beyond defect detection to defect prevention and system resilience. The focus shifts from simply catching bugs to building systems that are inherently more robust.
This is where you introduce advanced techniques like chaos engineering (e.g., using LitmusChaos) to proactively test system resilience or performance testing as a continuous, automated stage in the pipeline (e.g., using k6). AI is also becoming a critical enabler; an incredible 60% of organizations now use AI in their QA processes, a figure that doubled in just one year. This includes AI-powered test generation, visual regression testing, and anomaly detection in observability data. You can dig into more insights like this over on DevOps Digest.
By embracing these advanced practices, you transform quality from a cost center into a true competitive advantage, enabling you to innovate with both speed and confidence.
Frequently Asked Questions About DevOps QA
As organizations implement DevOps quality assurance, common and highly technical questions arise. The shift from traditional, siloed QA to an integrated model fundamentally alters roles, workflows, and team structures. Here are the answers to the most frequent technical questions.
What Is the Role of a QA Engineer in a DevOps Culture
In a mature DevOps culture, the QA Engineer role evolves from a manual tester to a Software Development Engineer in Test (SDET) or Quality Engineer. They are no longer a separate gatekeeper but a "quality coach" and automation architect embedded within the development team.
Their primary technical responsibilities shift to:
- Building Test Automation Frameworks: They design, build, and maintain the core test automation frameworks (e.g., a Cypress or Playwright framework with custom commands and page objects) that developers use.
- CI/CD Pipeline Integration: They are experts in configuring CI/CD pipelines (e.g., writing YAML for GitHub Actions or Jenkinsfiles) to integrate various testing stages (unit, integration, E2E) effectively.
- Observability and Monitoring: They work with SREs to define quality-centric monitoring and alerting. They help create dashboards in Grafana to track metrics like error rates, latency, and defect escape rates.
Their goal is to make quality a shared, automated, and observable attribute of the software delivery process, owned by the entire team.
How Do You Handle Manual and Exploratory Testing in DevOps
Automation is the core of DevOps QA, but it does not eliminate the need for manual and exploratory testing. Automation is excellent for verifying known requirements and preventing regressions. It is poor at discovering novel bugs or evaluating subjective user experience.
That's where human expertise remains critical. Exploratory testing is essential for investigating complex user workflows, assessing usability, and identifying edge cases that automated scripts would miss.
The technical approach is to integrate it strategically:
- Automate all deterministic, repetitive regression checks and execute them in the CI pipeline.
- Use feature flags to deploy new functionality to a limited audience or internal users for "dogfooding" and exploratory testing in a production-like environment.
- Conduct time-boxed exploratory testing sessions on new, complex features before a full production rollout.
This hybrid approach provides the speed of automation with the depth of human-driven exploration.
Manual testing isn't the enemy of DevOps; it's a strategic partner. You automate the predictable so that your human experts can focus their creativity on exploring the unpredictable. That's how you achieve real coverage.
Can You Fully Eliminate a Separate QA Team
While the goal is to eliminate the silo between development and QA, most high-performing organizations do not eliminate quality specialists entirely. Instead, the centralized QA team's function evolves.
They transform from a hands-on testing service into a Center of Excellence (CoE) or Platform Team. This centralized group is not responsible for the day-to-day testing of product features. Instead, their technical mandate is to:
- Define and maintain the standard testing toolchains, frameworks, and libraries for the entire organization.
- Build and support reusable CI/CD pipeline components (e.g., shared Docker images, pipeline templates) that enforce quality gates.
- Provide expert consultation, training, and support to the embedded Quality Engineers and developers within product teams.
This model provides organizational consistency and economies of scale while embedding the day-to-day ownership of quality directly within the teams that build the software.
Ready to accelerate your software delivery and improve reliability? The experts at OpsMoon can help you build a world-class DevOps QA strategy. We connect you with the top 0.7% of global engineering talent to assess your maturity, design a clear roadmap, and implement the toolchains and processes you need to succeed. Start with a free work planning session today.