In today's competitive landscape, the speed and reliability of software delivery are no longer just technical goals; they are core business imperatives. A highly optimized CI/CD pipeline is the engine that drives this delivery, transforming raw code into customer value with velocity and precision. However, building a pipeline that is fast, secure, and resilient is a complex challenge. It requires moving beyond basic automation to adopt a holistic set of practices that govern everything from testing and infrastructure to security and feedback loops.
This article dives deep into the 10 most critical CI/CD pipeline best practices that elite engineering teams use to gain a competitive edge. We will move past surface-level advice to provide technical, actionable guidance, complete with configuration examples, tool recommendations, and real-world scenarios to help you build a deployment machine that truly performs. Whether you are a startup CTO defining your initial DevOps strategy or an enterprise SRE looking to refine a complex, multi-stage delivery system, these principles will provide a clear roadmap.
While optimizing the technical aspects of CI/CD is critical for efficient delivery, ensuring that the right products are built in the first place relies on solid product management. For a comprehensive look at the strategic side of development, you can explore actionable product management best practices for 2025. This guide focuses on the engineering execution, covering essential topics from Infrastructure as Code (IaC) and container orchestration to integrated security scanning and comprehensive observability. You will learn not just what to do, but how and why, empowering your team to ship better software, faster.
1. Automated Testing at Every Stage
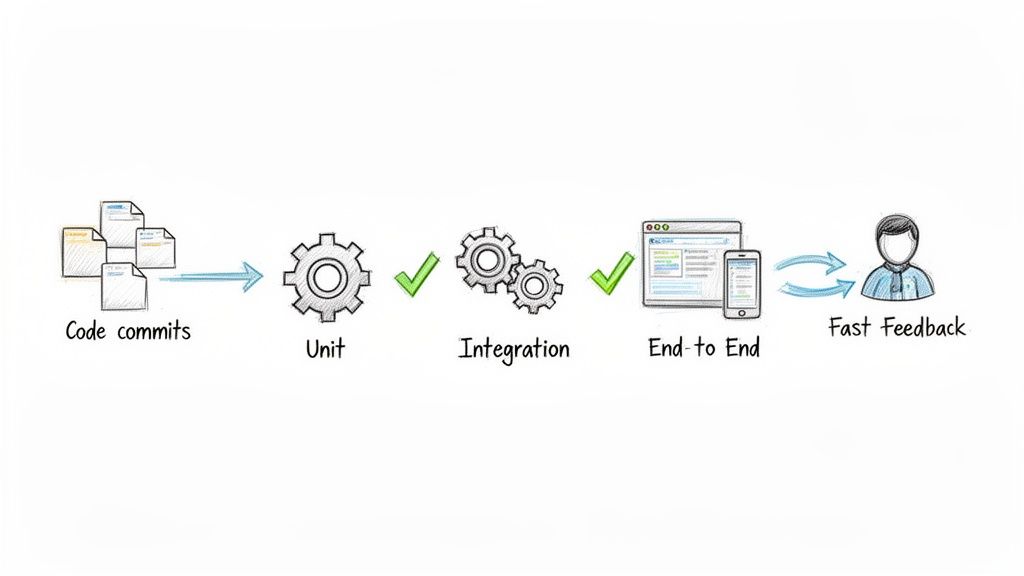
Automated testing is the cornerstone of modern CI/CD pipeline best practices, serving as a critical quality gate that prevents defects from reaching production. This approach involves embedding a comprehensive suite of tests directly into the pipeline, which are automatically triggered by events like code commits or pull requests. By systematically validating code at each stage, from unit tests on individual components to full-scale end-to-end tests on a staging environment, teams can catch bugs early, reduce manual effort, and significantly accelerate the feedback loop for developers.
This practice is essential because it builds confidence in every deployment. For example, Google’s internal tooling runs millions of automated tests daily, ensuring that any single change doesn't break the vast ecosystem of interdependent services. This allows them to maintain development velocity without compromising stability.
Practical Implementation Steps
To effectively integrate this practice, follow a layered approach:
- Start with Unit Tests: Begin by creating unit tests that cover critical business logic and complex functions. Use frameworks like Jest for JavaScript, JUnit for Java, or PyTest for Python. Aim for a code coverage target of 70-80%; while 100% is often impractical, this range ensures most critical paths are validated.
- Expand to Integration and E2E Tests: Once a solid unit test foundation exists, add integration tests to verify interactions between services and end-to-end (E2E) tests to simulate user journeys. Tools like Cypress or Selenium are excellent for E2E testing.
- Optimize for Speed: Keep pipeline execution times under 15 minutes to maintain a fast feedback loop. Achieve this by running tests in parallel across multiple agents or containers.
- Integrate and Visualize: Configure your CI server (e.g., Jenkins, GitLab CI) to display test results directly in pull requests. This provides immediate visibility and helps developers pinpoint failures quickly.
Staying current is also crucial; for instance, understanding the latest advances in regression testing APIs for CI/CD integration can help you further automate and strengthen the validation of your application's core functionalities after changes.
2. Infrastructure as Code (IaC)
Infrastructure as Code (IaC) is a pivotal practice for modern CI/CD pipelines, treating infrastructure management with the same rigor as application development. It involves defining and provisioning infrastructure through machine-readable definition files (e.g., Terraform, AWS CloudFormation) rather than manual configuration. This code-based approach ensures environments are consistent, reproducible, and easily versioned, making infrastructure changes transparent and auditable. By integrating IaC into the pipeline, infrastructure updates follow the same automated testing and deployment flow as application code.
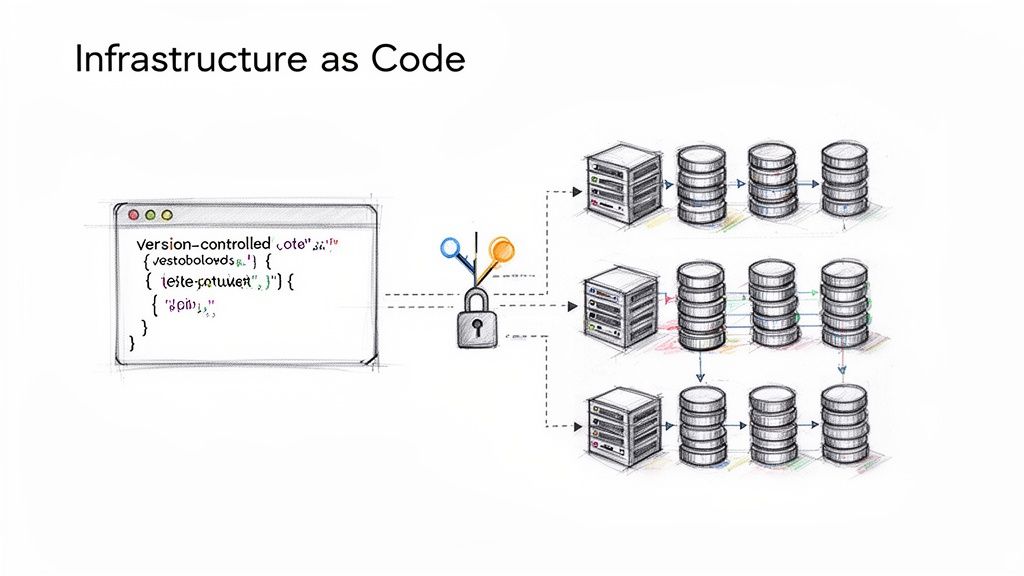
This methodology is fundamental for achieving scalable and reliable operations. For instance, Airbnb leverages Terraform to manage its complex AWS infrastructure, allowing engineering teams to rapidly provision and modify resources in a standardized, automated fashion. This prevents configuration drift and empowers developers to manage their service dependencies safely, a critical advantage for dynamic, large-scale systems.
Practical Implementation Steps
To successfully adopt IaC as one of your core CI/CD pipeline best practices, focus on building a robust, automated workflow:
- Choose the Right Tool: Start with a tool that fits your ecosystem. Use Terraform for multi-cloud flexibility or Pulumi for using general-purpose programming languages. If you're deeply integrated with AWS, CloudFormation is a powerful native choice.
- Establish Version Control and State Management: Store your IaC files in a Git repository alongside your application code. Implement remote state locking using a backend like an S3 bucket with DynamoDB to prevent concurrent modifications and ensure a single source of truth for your infrastructure's state.
- Create Reusable Modules: Structure your code into reusable modules (e.g., a standard VPC setup or a database cluster configuration). This promotes consistency, reduces code duplication, and simplifies infrastructure management across multiple projects or environments.
- Integrate IaC into Your Pipeline: Add dedicated stages in your CI/CD pipeline to validate (
terraform validate), plan (terraform plan), and apply (terraform apply) infrastructure changes. Enforce mandatory code reviews for all pull requests modifying infrastructure code.
It is also crucial to incorporate security and compliance checks directly into your workflow; for more detail, you can explore best practices for how to check your IaC for potential vulnerabilities before deployment.
3. Continuous Integration with Automated Builds
Continuous Integration (CI) is a foundational practice where developers frequently merge their code changes into a central repository, after which automated builds and tests are run. This process acts as the first line of defense in modern CI/CD pipeline best practices, ensuring that new code integrates seamlessly with the existing codebase. By automating the build and initial validation steps for every single commit, teams can detect integration errors almost immediately, preventing them from escalating into more complex problems later in the development cycle.
This practice is essential for maintaining a high-velocity, high-quality development process. For instance, LinkedIn’s engineering teams rely heavily on CI to manage thousands of daily commits across their complex microservices architecture. Each commit triggers a dedicated CI pipeline that builds the service, runs a battery of tests, and provides immediate feedback, allowing developers to address issues while the context is still fresh in their minds.
Practical Implementation Steps
To implement this practice effectively, focus on speed, consistency, and clear communication:
- Establish a Fast Feedback Loop: Target a CI build duration of under 10 minutes. If builds take longer, developers may start batching commits or lose focus, defeating the purpose of rapid feedback. Run quick, lightweight checks like linting and unit tests first to fail fast.
- Ensure Consistent Build Environments: Use containers (e.g., Docker) to define and manage your build environment. This guarantees that code is built in a consistent, reproducible environment, eliminating "it works on my machine" issues and ensuring builds behave identically in CI and local development.
- Optimize Build Speed with Caching and Parallelization: Implement artifact caching for dependencies to avoid re-downloading them on every run. Furthermore, parallelize independent build stages (like running different test suites simultaneously) to significantly reduce the total pipeline execution time.
- Implement Immediate Failure Notifications: Configure your CI server (like GitHub Actions or Jenkins) to instantly notify the relevant team or developer of a build failure via Slack, email, or other communication channels. This enables swift troubleshooting and prevents a broken build from blocking other developers.
4. Containerization and Container Orchestration
Containerization and its orchestration are foundational to modern CI/CD pipeline best practices, creating a consistent, portable, and scalable environment for applications. This approach involves packaging an application and its dependencies into a standardized unit, a container, using tools like Docker. These containers run identically anywhere, from a developer's laptop to production servers, eliminating the "it works on my machine" problem. Orchestration platforms like Kubernetes then automate the deployment, scaling, and management of these containers.
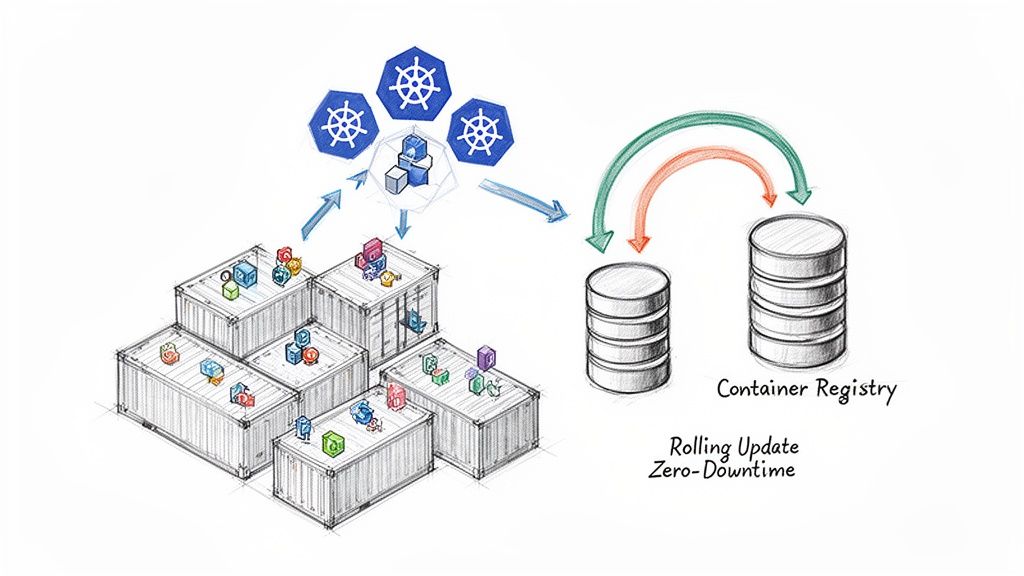
This practice is essential because it decouples the application from the underlying infrastructure, enabling unprecedented speed and reliability. For instance, Netflix leverages its own container orchestrator, Titus, to manage its massive streaming infrastructure, while Airbnb runs thousands of microservices on Kubernetes. This ensures their services are resilient, scalable, and can be updated with zero downtime, a key requirement for high-availability systems.
Practical Implementation Steps
To effectively integrate containerization into your CI/CD pipeline, focus on automation and security:
- Build Minimal, Secure Images: Start with official, lean base images (e.g.,
alpineordistroless) to reduce the attack surface and deployment time. Integrate container image scanning tools like Trivy or Snyk directly into your CI pipeline to detect vulnerabilities before they reach a registry. - Tag Images for Traceability: Automate image tagging using the Git commit SHA. For example,
my-app:1.2.0-a1b2c3dimmediately links a running container back to the exact code version that built it, simplifying debugging and rollbacks. - Automate Kubernetes Manifests: Use tools like Helm or Kustomize to manage and template your Kubernetes deployment configurations. This allows you to define application deployments as code, making them repeatable and version-controlled across different environments (dev, staging, prod).
- Enforce Resource Management: Always define CPU and memory
requestsandlimitsfor every container in your Kubernetes manifests. This prevents resource contention, ensures predictable performance, and improves cluster stability by allowing the scheduler to make informed decisions.
5. Deployment Automation and GitOps
Deployment automation eliminates error-prone manual steps, ensuring consistent and repeatable releases through scripted workflows. GitOps evolves this concept by establishing a Git repository as the single source of truth for both infrastructure and application configurations. In this model, changes to the production environment are made exclusively through Git commits, with automated agents continuously reconciling the live state to match the declarations in the repository. This approach is a cornerstone of modern CI/CD pipeline best practices, providing a clear audit trail, simplified rollbacks, and enhanced security.
This practice is essential for managing complex, modern infrastructure with confidence and scalability. For instance, Intuit adopted ArgoCD to manage deployments across hundreds of Kubernetes clusters, empowering developers with a self-service, Git-based workflow that significantly reduced deployment failures and operational overhead. This model shifts the focus from imperative commands to a declarative state, where the desired system state is version-controlled and auditable.
Practical Implementation Steps
To effectively implement GitOps and deployment automation, follow these steps:
- Establish Git as the Source of Truth: Begin by creating dedicated Git repositories for your application manifests and infrastructure-as-code (e.g., Kubernetes YAML, Helm charts, Terraform). Use separate repositories to decouple application and infrastructure lifecycles.
- Implement a Pull Request Workflow: Enforce a PR-based process for all changes. Use branch protection rules in Git to require peer reviews and automated checks (like linting and validation) before any change can be merged into the main branch. This ensures every change is vetted.
- Deploy a GitOps Agent: Install a GitOps tool like ArgoCD or Flux CD in your cluster. Configure it to monitor your Git repository and automatically apply changes to synchronize the cluster state with the repository's declared state.
- Automate Secret Management: Avoid committing secrets directly to Git. Integrate a secure solution like Sealed Secrets or HashiCorp Vault to manage sensitive information declaratively and safely within the GitOps workflow.
- Enable Drift Detection and Alerting: Configure your GitOps tool to continuously monitor for "drift" – discrepancies between the live cluster state and the Git repository. Set up alerts to notify the team immediately if manual changes or configuration drift is detected.
6. Comprehensive Monitoring and Observability
Comprehensive observability is a critical evolution from traditional monitoring, providing deep, real-time insights into your system's internal state. It's a cornerstone of CI/CD pipeline best practices because it enables teams to validate deployment health and rapidly diagnose issues in complex, distributed environments. By collecting and correlating logs, metrics, and traces, you can move from asking "Is the system down?" to "Why is the system slowing down for users in this specific region after the last deployment?"
This practice is essential for building resilient and reliable systems. For example, Netflix has built a sophisticated, custom observability platform that allows its engineers to instantly visualize the impact of a code change across thousands of microservices. This capability is key to their model of high-velocity development, enabling rapid, confident deployments while maintaining service stability for millions of users worldwide.
Practical Implementation Steps
To build a robust observability framework into your pipeline, focus on the three pillars:
- Implement the Three Pillars: Instrument your applications to emit logs, metrics, and traces. Use structured logging (e.g., JSON format) for easy parsing, Prometheus for metrics collection, and OpenTelemetry for standardized, vendor-agnostic distributed tracing. This trifecta provides a complete picture of system behavior.
- Integrate Health Checks into Deployments: Use metric-based validation as a quality gate in your pipeline. Before promoting a new version from staging to production, your pipeline should automatically query key Service Level Objectives (SLOs) like error rate and latency. If these metrics degrade beyond a set threshold, the deployment is automatically rolled back.
- Establish Actionable Dashboards: Create tailored dashboards in tools like Grafana for different audiences. Engineering teams need granular dashboards showing application performance and resource usage, while business stakeholders need high-level views of user experience and system availability.
- Centralize and Analyze Logs: Employ log aggregation tools like Loki or the ELK Stack (Elasticsearch, Logstash, Kibana) to centralize application and system logs. This allows for powerful querying and historical analysis, which is invaluable for debugging complex, intermittent issues that are not immediately apparent through metrics alone.
7. Security Scanning and Policy Enforcement
Integrating security into the pipeline, often called DevSecOps, is a non-negotiable CI/CD pipeline best practice that transforms security from a final-stage bottleneck into a continuous, automated process. This "shift-left" approach involves embedding security checks directly into the workflow, automatically scanning for vulnerabilities in code, dependencies, containers, and infrastructure configurations. By enforcing security policies as automated gates, teams can proactively identify and remediate threats long before they reach production, drastically reducing risk and the cost of fixes.
This practice is essential for building resilient and trustworthy systems in a high-velocity development environment. For example, GitHub's Dependabot automatically scans repositories for vulnerable dependencies and creates pull requests to update them, while Google's internal systems perform mandatory security scanning on all container images before they can be deployed. This level of automation ensures that security standards are consistently met without slowing down developers.
Practical Implementation Steps
To effectively integrate security scanning and policy enforcement, adopt a multi-layered strategy:
- Implement Pre-Commit and Pre-Push Hooks: Start by catching issues at the earliest possible moment. Use tools like
pre-commitwith hooks for secrets detection (e.g.,gitleaksortrufflehog) to prevent sensitive data from ever entering the repository's history. - Automate Dependency and Container Scanning: Integrate Static Application Security Testing (SAST) and Software Composition Analysis (SCA) tools like Snyk or Trivy into your pipeline. Configure them to run on every build to scan application code and third-party dependencies for known vulnerabilities. Similarly, scan container images for OS-level vulnerabilities upon creation and before pushing to a registry.
- Audit Infrastructure as Code (IaC): Use tools like Checkov or Terrascan to scan your Terraform, CloudFormation, or Kubernetes manifests for security misconfigurations. This prevents insecure infrastructure from being provisioned in the first place.
- Establish and Enforce Policy Gates: Define clear, severity-based policies for your security gates. For instance, automatically fail any build that introduces a "critical" or "high" severity vulnerability. This ensures that only code meeting your security baseline can proceed to deployment.
Adopting these measures is a foundational step in building a robust DevSecOps culture. To explore this topic further, you can learn more about implementing DevSecOps in CI/CD pipelines and how it enhances overall software security.
8. Pipeline Orchestration and Visibility
Effective pipeline orchestration involves designing a workflow with clearly defined, single-responsibility stages that manage build, test, and deployment activities in a logical sequence. This practice transforms the pipeline from a monolithic script into a modular, manageable process. Coupled with comprehensive visibility, which provides real-time dashboards and notifications, orchestration ensures all stakeholders, from developers to project managers, have a clear understanding of the release process, its status, and any bottlenecks that arise.
This practice is critical for maintaining control and clarity in complex software delivery cycles. For example, GitLab CI/CD excels by providing a built-in "Pipeline Graph" that visually maps out every stage, job, and dependency. This graphical representation allows teams to instantly pinpoint failures or performance lags in specific stages, such as an integration test suite that takes too long to run, enabling targeted optimizations.
Practical Implementation Steps
To implement robust orchestration and visibility in your CI/CD pipeline best practices, focus on modularity and communication:
- Define Granular Stages: Break down your pipeline into distinct, single-purpose stages like
build,unit-test,security-scan,deploy-staging, ande2e-test. Using a tool like GitHub Actions, you can define these as separate jobs that depend on one another, ensuring a logical and fault-tolerant flow. - Establish Naming Conventions: Use clear and consistent naming for jobs, stages, and artifacts (e.g.,
app-v1.2.0-build-42.zip). This discipline makes it easier to track builds and debug failures when looking through logs or artifact repositories. - Implement Real-Time Notifications: Configure your CI tool to send automated alerts to communication platforms like Slack or Microsoft Teams. Set up notifications for key events such as pipeline success, failure, or manual approval requests to keep the team informed and responsive.
- Visualize Key Metrics: Use dashboards to track and display critical CI/CD metrics, including Deployment Frequency (DF), Lead Time for Changes (LT), and Mean Time to Recovery (MTTR). Tools like GitKraken's Insights can provide visibility into CI/CD health, helping you measure and improve your pipeline's efficiency over time.
9. Environment Parity and Configuration Management
Maintaining environment parity is a critical CI/CD pipeline best practice that involves keeping development, staging, and production environments as identical as possible. This practice drastically reduces the "it worked on my machine" problem, where code behaves differently across stages due to subtle variations in operating systems, dependencies, or configurations. By ensuring consistency, teams can prevent unexpected deployment failures and ensure that an application validated in staging will perform predictably in production.
This principle is essential for building reliable deployment processes. For example, Docker revolutionized this by allowing developers to package an application and its dependencies into a container that runs identically everywhere, from a local laptop to a production Kubernetes cluster. This eliminates an entire class of environment-specific bugs and streamlines the path to production.
Practical Implementation Steps
To achieve and maintain environment parity, focus on automation and versioning:
- Standardize with Containerization: Use Docker or a similar container technology as the foundation for all environments. Define your application's runtime environment in a
Dockerfileto ensure every instance is built from the same blueprint. - Implement Infrastructure as Code (IaC): Provision all environments (dev, staging, prod) using IaC tools like Terraform or AWS CloudFormation. Store these definitions in version control to track changes and automate environment creation and updates, preventing configuration drift.
- Centralize Configuration Management: Avoid hardcoding configuration values like API keys or database URLs. Instead, manage them externally using tools like HashiCorp Vault, AWS Secrets Manager, or Kubernetes Secrets. This separation allows the same application artifact to be deployed to any environment with the appropriate configuration.
- Automate Environment Provisioning: Integrate your IaC scripts into your CI/CD pipeline. This allows for dynamic creation of ephemeral testing environments for pull requests, providing the highest degree of confidence before merging code.
Effectively managing these configurations is key to success. You can explore a variety of best-in-class configuration management tools to find the right fit for your technology stack and operational needs.
10. Feedback Loops and Continuous Improvement
An effective CI/CD pipeline is not a static artifact; it is a dynamic system that must evolve. The practice of building feedback loops and fostering a culture of continuous improvement is fundamental to this evolution. This involves more than just pipeline notifications; it means systematically collecting, analyzing, and acting on data to enhance development velocity, stability, and overall efficiency. By treating the pipeline itself as a product, teams can identify bottlenecks, refine processes, and ensure their delivery mechanism continually adapts to new challenges.
This data-driven approach is essential for turning a functional pipeline into a high-performing one. For instance, companies across the industry rely on Google's DORA (DevOps Research and Assessment) metrics to benchmark their performance. By tracking these key indicators, organizations gain objective insights into their DevOps maturity, enabling them to make informed decisions that drive measurable improvements in their CI/CD pipeline best practices.
Practical Implementation Steps
To build a robust culture of continuous improvement, focus on a metrics-driven feedback system:
- Establish Key DORA Metrics: Begin by tracking the four core DORA metrics. Use your CI/CD tool (e.g., GitLab, CircleCI, Jenkins with plugins) to measure Deployment Frequency and Lead Time for Changes. For production, use monitoring tools like Datadog or Prometheus to track Change Failure Rate and Mean Time to Recovery (MTTR).
- Conduct Blameless Post-Mortems: After any significant production incident, hold a blameless post-mortem. The goal is not to assign fault but to identify systemic weaknesses in your pipeline, testing strategy, or deployment process. Document action items and assign owners to ensure follow-through.
- Implement Meaningful Alerts: Configure alerts that focus on user impact and service-level objectives (SLOs), not just system noise like high CPU usage. This ensures that when an alert fires, it signifies a genuine issue that requires immediate attention, making the feedback loop more effective.
- Visualize and Share Metrics: Create dashboards that display metric trends over time. Share these transparently across all engineering teams. This visibility helps align everyone on common goals and highlights areas where collective effort is needed for improvement.
CI/CD Pipeline Best Practices — 10-Point Comparison
| Practice | Implementation complexity | Resource requirements | Expected outcomes | Ideal use cases | Key advantages |
|---|---|---|---|---|---|
| Automated Testing at Every Stage | Medium–High: design/maintain unit, integration, E2E suites | Test infra, CI capacity, test frameworks, maintenance effort | Fewer defects, faster feedback, higher deployment confidence | Frequent deployments, microservices, regression-prone codebases | Early bug detection, reduced manual testing, scalable dev velocity |
| Infrastructure as Code (IaC) | Medium: module design, state management, governance | IaC tools (Terraform/CF), remote state, reviewers, security controls | Reproducible infra, reduced drift, auditability | Multi-cloud, repeatable environments, compliance and DR needs | Eliminates drift, automates provisioning, improves collaboration |
| Continuous Integration with Automated Builds | Low–Medium: CI pipelines, build/test orchestration | Build servers/CI service, artifact storage, test suites | Immediate integration issue detection, consistent artifacts | Teams with frequent commits, rapid feedback requirements | Prevents broken merges, consistent builds, faster dev cycles |
| Containerization & Orchestration | High: container lifecycle + Kubernetes operations | Container registry, orchestration clusters, SRE expertise | Consistent deployments, scalable workloads, easy rollbacks | Microservices, large-scale apps, multi-cloud deployments | Environment consistency, efficient scaling, portable deployments |
| Deployment Automation & GitOps | Medium–High: Git workflows, reconciliation, policy control | GitOps tools (Argo/Flux), policy engines, secret management | Auditable, repeatable, safer deployments with automated sync | Teams wanting declarative deployments, regulated environments | Git single source of truth, automated rollbacks, deployment audit trail |
| Comprehensive Monitoring & Observability | High: instrumentation, traces, correlation across services | Monitoring stack, storage, dashboards, alerting, instrumentation effort | Faster detection & RCA, performance insights, SLO validation | Distributed systems, production-critical services, high-availability apps | Improved MTTR, data-driven ops, deployment validation |
| Security Scanning & Policy Enforcement | Medium: integrate SAST/DAST/SCA, tune policies | Security tools, SBOMs, secrets scanners, security expertise | Fewer vulnerabilities, compliance evidence, safer releases | Security-sensitive apps, regulated industries, supply-chain risk | Shift-left security, automated gates, developer self-service checks |
| Pipeline Orchestration & Visibility | Medium: define stages, parallelism, dashboards | CI/CD platform, dashboards, ownership/process definitions | Clear progress visibility, bottleneck identification, audit trails | Organizations with complex pipelines or many teams | Stage-level visibility, artifact promotion, clearer responsibilities |
| Environment Parity & Configuration Mgmt | Medium: maintain IaC, configs, secret stores | Containers/IaC, secret manager, staging environments | Fewer environment surprises, realistic testing, smoother rollouts | Teams needing reliable staging and reproducible infra | Reduces "works on my machine", simplifies debugging, reliable repro |
| Feedback Loops & Continuous Improvement | Low–Medium: metrics, retrospectives, SLIs/SLOs | Metrics tooling, dashboards, process discipline, incident tracking | Continuous optimization, improved lead times and reliability | Organizations tracking DORA metrics, maturing DevOps practices | Data-driven improvements, faster issue resolution, learning culture |
Turn Best Practices into Your Competitive Advantage
You've explored the ten pillars of modern software delivery, from atomic, automated tests to comprehensive observability. It’s clear that mastering these ci cd pipeline best practices is no longer a luxury reserved for tech giants; it is the foundational requirement for any organization aiming to compete on innovation, speed, and reliability. The journey from a manual, error-prone release process to a fully automated, secure, and resilient delivery engine is transformative. It's about more than just shipping code faster. It’s about building a culture of quality, empowering developers with rapid feedback, and creating a system that can adapt and scale with your business ambitions.
Each practice we've detailed, whether it's managing your infrastructure with Terraform or integrating SAST and DAST scans directly into your pipeline, is a crucial component of a larger, interconnected system. Think of it not as a checklist to be completed, but as a framework for continuous evolution. Your pipeline is a living product that serves your development teams, and like any product, it requires consistent iteration and improvement.
From Theory to Tangible Business Value
Adopting these principles moves your organization beyond simple automation and into the realm of strategic engineering. When your pipeline is robust, the benefits cascade across the entire business:
- Reduced Time-to-Market: By automating everything from builds and tests to security scans and deployments, you drastically shorten the cycle time from an idea to a feature in the hands of a customer. This agility is your primary weapon in a fast-moving market.
- Enhanced Code Quality and Stability: A pipeline that enforces rigorous testing, environment parity, and automated security checks acts as your ultimate quality gate. The result is fewer bugs in production, reduced downtime, and a more stable, reliable product for your users.
- Improved Developer Productivity and Morale: Developers are most effective when they can focus on writing code, not wrestling with broken builds or convoluted deployment scripts. A well-oiled CI/CD pipeline provides them with the fast feedback and autonomy they need to innovate confidently.
- Stronger Security and Compliance Posture: Embedding security directly into the development lifecycle, a concept known as DevSecOps, turns security from a bottleneck into a shared responsibility. This "shift-left" approach helps you identify and remediate vulnerabilities early, reducing risk and simplifying compliance.
Your Actionable Roadmap to CI/CD Excellence
The path to maturity is an incremental one. Don't aim to implement all ten best practices overnight. Instead, focus on a phased approach that delivers immediate value and builds momentum. Start by assessing your current state. Where are the biggest bottlenecks? Where do the most frequent errors occur?
- Establish a Baseline: Implement robust monitoring and define key DORA metrics (Deployment Frequency, Lead Time for Changes, Change Failure Rate, and Time to Restore Service). You cannot improve what you cannot measure.
- Target High-Impact Areas First: If your deployment process is manual and slow, start by automating it for a single, low-risk service. If testing is a bottleneck, focus on implementing a solid unit and integration test suite.
- Iterate and Expand: Once you've solidified one practice, move to the next. Use the success of your initial efforts to gain buy-in and resources for broader implementation across more teams and services.
Ultimately, a world-class CI/CD pipeline is a powerful engine for growth. It codifies your engineering standards, accelerates your feedback loops, and provides the stable foundation upon which you can build, scale, and innovate without fear. By committing to these ci cd pipeline best practices, you are not just optimizing a process; you are investing in a core competitive advantage that will pay dividends for years to come.
Ready to transform your CI/CD pipeline from a functional tool into a strategic asset? The elite DevOps and Platform Engineers at OpsMoon specialize in designing and implementing the robust, scalable, and secure pipelines that drive business velocity. Start your journey to engineering excellence with a free, no-obligation work planning session and see how our top 0.7% talent can help you implement these best practices today.
Leave a Reply