So, what exactly is a workload in cloud computing?
A workload is the aggregation of resources and processes that deliver a specific business capability. It’s a holistic view of an application, its dependencies, the data it processes, and the compute, storage, and network resources it consumes from the cloud provider.
Understanding the Modern Cloud Workload
A workload is a logical unit, not a single piece of software. It represents the entire stack—from the application code and its runtime down to the virtual machines, containers, databases, and network configurations—all functioning in concert to execute a defined task.
Here's a technical analogy: consider your cloud environment a distributed operating system. The physical servers, storage arrays, and network switches are the kernel-level hardware resources. The workload, then, is a specific process running on this OS—a self-contained set of operations that consumes system resources (CPU cycles, memory, I/O) to transform input data into a defined output, like serving an API response or executing a machine learning training job.
This concept is fundamental for anyone migrating from a CAPEX-heavy model of on-premises vs cloud infrastructure to a consumption-based OPEX model.
Workloads Are Defined by Their Resource Profile
Discussing workloads abstracts the conversation away from individual VMs or database instances and toward the end-to-end business function they enable. Whether it's a customer-facing web application or a backend data pipeline, it's a distinct workload. The industry adoption reflects this paradigm shift; 60% of organizations now run more than half their workloads in the cloud, a significant increase from 39% in 2022.
A workload is the "why" behind your cloud spend. It’s the unit of value your technology delivers, whether that's processing a million transactions, training a machine learning model, or serving real-time video to users.
Classifying workloads by their technical characteristics is the first step toward effective cloud architecture and FinOps. Each workload type has a unique resource consumption "fingerprint" that dictates the optimal design, deployment, and management strategy for performance and cost-efficiency.
To operationalize this, here's a classification framework mapping common workload types to their primary functions and resource demands.
Quick Reference Cloud Workload Classification
This table provides a technical breakdown of common workload types, enabling architects and engineering leaders to rapidly categorize and plan for the services running in their cloud environment.
| Workload Type | Primary Function | Key Resource Demand | Common Use Case |
|---|---|---|---|
| Stateless | Handle independent, transient requests | High Compute, Low Storage | Web servers, API gateways, serverless functions |
| Stateful | Maintain session data across multiple interactions | High Storage I/O, High Memory | Databases, user session management systems |
| Transactional | Process a high volume of small, discrete tasks | High I/O, CPU, and Network | E-commerce checkout, payment processing |
| Batch | Process large volumes of data in scheduled jobs | High Compute (burst), Storage | End-of-day financial reporting, data ETL |
| Analytic | Run complex queries on large datasets | High Memory, High Compute | Business intelligence dashboards, data warehousing |
Understanding where your applications fall within this classification is a prerequisite for success. It directly informs your choice of cloud services and how you architect a solution for cost, performance, and reliability.
A Technical Taxonomy of Cloud Workloads
Not all workloads are created equal. Making correct architectural decisions—the kind that prevent 3 AM pages and budget overruns—requires a deep understanding of a workload's technical DNA. This is a practical classification model, breaking workloads down by their core behavioral traits and infrastructure demands.
Stateless vs. Stateful: The Great Divide
At the most fundamental level, workloads are either stateless or stateful. This distinction is not academic; it dictates your approach to build, deployment, high availability, and especially scaling strategy within a cloud environment.
A stateless workload processes each request in complete isolation, without knowledge of previous interactions. A request contains all the information needed for its own execution. This design principle, common in RESTful APIs, simplifies horizontal scaling. Need more capacity? Deploy more identical, interchangeable instances behind a load balancer. The system's scalability becomes a function of how quickly you can provision new compute nodes.
A stateful workload maintains context, or "state," across multiple requests. This state—be it user session data, shopping cart items, or the data within a relational database—must be stored persistently and remain consistent. Scaling stateful workloads is inherently more complex. You can't simply terminate an instance without considering the state it holds. This necessitates solutions like persistent block storage, distributed databases, or external caching layers (e.g., Redis, Memcached) to manage state consistency and availability.
Core Workload Archetypes
Beyond the stateful/stateless dichotomy, workloads exhibit common behavioral patterns, or archetypes. Identifying these patterns is crucial for selecting the right cloud services and avoiding architectural mismatches, such as using a service optimized for transactional latency to run a throughput-bound batch job.
Here are the primary patterns you'll encounter:
- Transactional (OLTP): Characterized by a high volume of small, atomic read/write operations that must complete with very low latency. Examples include an e-commerce order processing API or a financial transaction system. Key performance indicators (KPIs) are transactions per second (TPS) and p99 latency. These workloads demand high I/O operations per second (IOPS) and robust data consistency (ACID compliance).
- Batch: Designed for processing large datasets in discrete, scheduled jobs. A classic example is a nightly ETL (Extract, Transform, Load) pipeline that ingests raw data, processes it, and loads it into a data warehouse. These workloads are compute-intensive and often designed to run on preemptible or spot instances to dramatically reduce costs. Throughput (data processed per unit of time) is the primary metric, not latency.
- Analytical (OLAP): Optimized for complex, ad-hoc queries against massive, often columnar, datasets. These workloads power business intelligence (BI) dashboards and data science exploration. They are typically read-heavy and require significant memory and parallel processing capabilities to execute queries efficiently across terabytes or petabytes of data.
- AI/ML Training: These are compute and data-intensive workloads that often require specialized hardware accelerators like GPUs or TPUs. The process involves iterating through vast datasets to train neural networks or other complex models. This demands both immense parallel processing power and high-throughput access to storage to feed the training pipeline without bottlenecks.
Understanding these workload profiles is central to a modern cloud strategy. It informs everything from your choice of a monolithic vs. microservices architecture to your cost optimization efforts.
The Rise of Cloud-Native Platforms
The paradigm shift to the cloud has catalyzed the development of platforms engineered specifically for these diverse workloads. By 2025, a staggering 95% of new digital workloads are projected to be deployed on cloud-native platforms like containers and serverless functions. Serverless adoption, in particular, has surpassed 75%, driven by its event-driven, pay-per-use model that is perfectly suited for bursty, stateless tasks.
This trend underscores why making the right architectural calls upfront—like the ones we discuss in our microservices vs monolithic architecture guide—is more critical than ever. You must design for the workload's specific profile, not just for a generic "cloud" environment.
Matching Workloads to the Right Cloud Services
Selecting a suboptimal cloud service for your workload is one of the most direct paths to technical debt and budget overruns. A one-size-fits-all approach is antithetical to cloud principles. Effective cloud architecture is about precision engineering: mapping the unique technical requirements of each workload to the most appropriate service model.
Consider the analogy of selecting a data structure. You wouldn't use a linked list for an operation requiring constant-time random access. Similarly, forcing a stateless, event-driven function onto a service designed for stateful, long-running applications is architecturally unsound, leading to resource waste and inflated costs.
Aligning Stateless Workloads With Serverless and Containers
Stateless microservices are ideally suited for container orchestration platforms like Amazon EKS or Google Kubernetes Engine (GKE). Because these workloads are idempotent and require no persistent local state, instances (pods) are fully interchangeable. This enables seamless auto-scaling: when CPU utilization or request count exceeds a defined threshold, the orchestrator automatically provisions additional pods to distribute the load.
For ephemeral, event-driven tasks, serverless computing (Function-as-a-Service or FaaS) is the superior architectural choice. Workloads like an image thumbnail generation function triggered by an S3 object upload are prime candidates for platforms like AWS Lambda. The cloud provider abstracts away all infrastructure management, and billing is based on execution duration and memory allocation, often in 1ms increments. This eliminates the cost of idle resources, making it highly efficient for intermittent or unpredictable traffic patterns.
The core principle is to match the service model to the workload's execution lifecycle. Persistent, long-running services belong in containers, while transient, event-triggered functions are tailor-made for serverless.
This diagram shows a basic decision tree for figuring out if your workload is stateful or stateless.
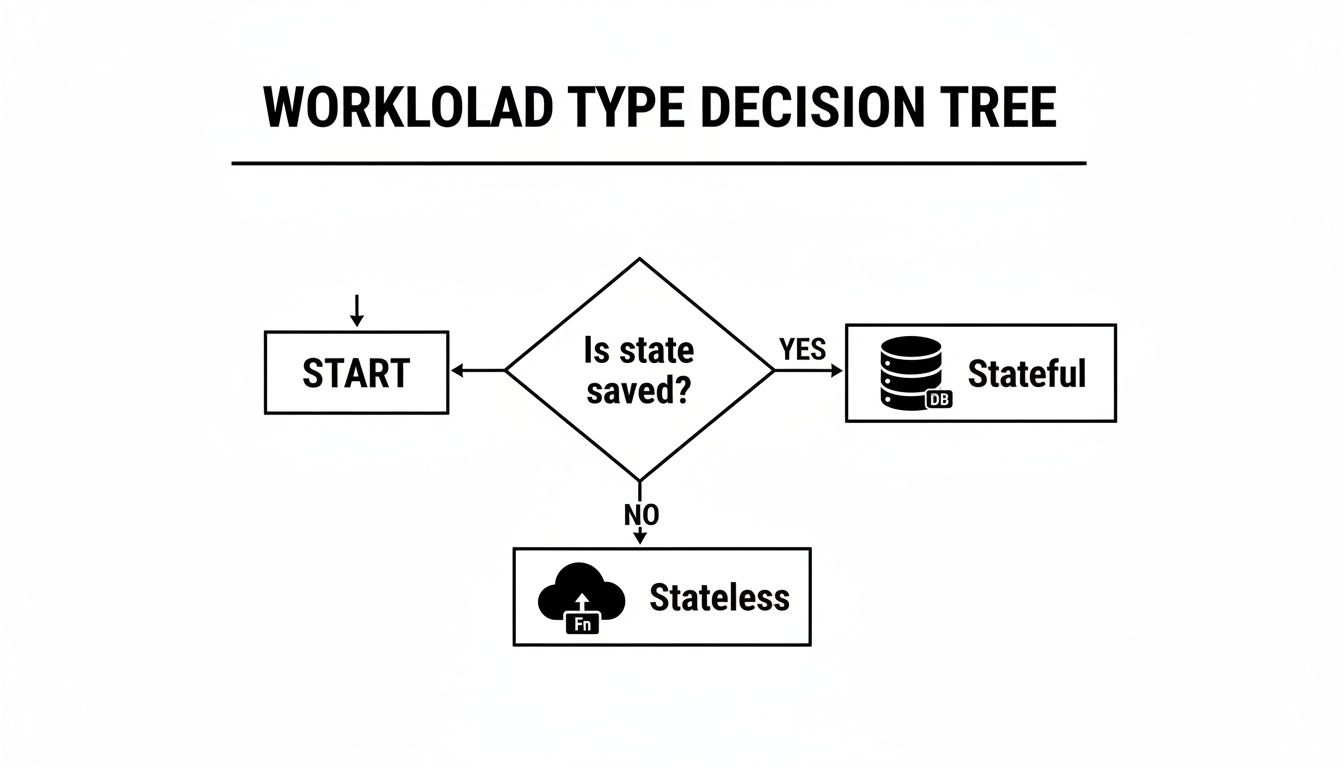
Correctly making this distinction is the first and most critical step in designing a technically sound and cost-effective cloud architecture.
Handling Stateful and Data-Intensive Workloads
Stateful applications, which must persist data across sessions, require a different architectural approach. While it is technically possible to run a database within a container using persistent volumes, this often introduces significant operational overhead related to data persistence, backups, replication, and failover management.
This is the precise problem that managed database services (DBaaS) are designed to solve. Platforms like Amazon RDS or Google Cloud SQL are purpose-built to handle the operational complexities of stateful data workloads, providing out-of-the-box solutions for:
- Automated Backups: Point-in-time recovery and automated snapshots without manual intervention.
- High Availability: Multi-AZ (Availability Zone) deployments with automatic failover to a standby instance.
- Scalability: Independent scaling of compute (vCPU/RAM) and storage resources, often with zero downtime.
For large-scale analytical workloads, specialized data warehousing platforms are mandatory. Attempting to execute complex OLAP queries on a traditional OLTP database will result in poor performance and resource contention. Solutions like Google BigQuery or Amazon Redshift utilize massively parallel processing (MPP) and columnar storage formats to deliver high-throughput query execution on petabyte-scale datasets.
To help visualize these decisions, here’s a quick-reference table that maps common workload types to their ideal cloud service models and provides some real-world examples.
Cloud Service Mapping for Common Workload Types
| Workload Type | Optimal Cloud Service Model | Example Cloud Services | Key Architectural Benefit |
|---|---|---|---|
| Stateless Web App | Containers (PaaS) / FaaS | Amazon EKS, Google GKE, AWS Fargate, AWS Lambda | Horizontal scalability and operational ease |
| Event-Driven Task | FaaS (Serverless) | AWS Lambda, Google Cloud Functions, Azure Functions | Pay-per-use cost model, no idle resources |
| Transactional DB | Managed Database (DBaaS) | Amazon RDS, Google Cloud SQL, Azure SQL Database | High availability and automated management |
| Batch Processing | IaaS / Managed Batch Service | AWS Batch, Azure Batch, VMs on any provider | Cost-effective for non-urgent, high-volume jobs |
| Data Analytics | Managed Data Warehouse | Google BigQuery, Amazon Redshift, Snowflake | Massively parallel processing for fast queries |
| ML Training | IaaS / Managed ML Platform (PaaS) | Amazon SageMaker, Google AI Platform, VMs with GPUs | Access to specialized hardware (GPUs/TPUs) |
| Real-Time Streaming | Managed Streaming Platform | Amazon Kinesis, Google Cloud Dataflow, Apache Kafka on Confluent Cloud | Low-latency data ingestion and processing |
This mapping is a strategic exercise, not just a technical one. The choice of service model is also a critical input when evaluating how to choose cloud provider, as each provider has different strengths. Correctly mapping your workload from the outset establishes a foundation for an efficient, resilient, and cost-effective system.
Designing for Performance, Scalability, and Cost
Cloud architecture is not a simple "lift-and-shift" of on-premises designs; it requires a fundamental shift in mindset. The paradigm moves away from building monolithic, over-provisioned systems toward designing elastic, fault-tolerant, and cost-aware distributed systems.
Your architecture should be viewed not as a static blueprint but as a dynamic system engineered to adapt to changing loads and recover from component failures automatically.
Performance in the cloud is a multidimensional problem. For a transactional API, latency (the time to service a single request) is the critical metric. For a data processing pipeline, throughput (the volume of data processed per unit of time) is the key performance indicator. You must architect specifically for the performance profile your workload requires.
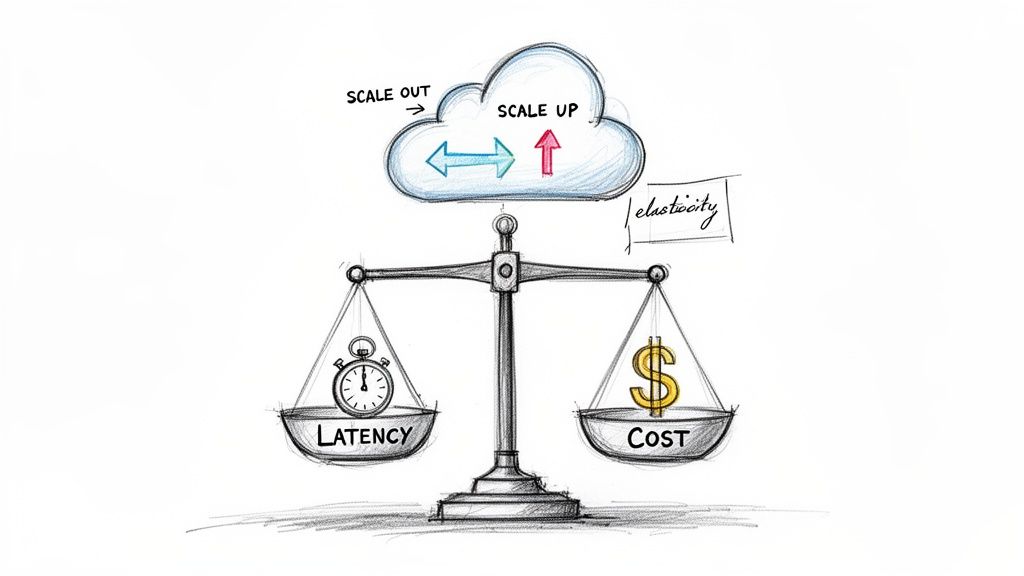
Engineering for Elasticity and Resilience
Cloud-native architecture prioritizes scaling out (horizontal scaling: adding more instances) over scaling up (vertical scaling: increasing the resources of a single instance). This horizontal approach, enabled by load balancing and stateless design, is fundamental to handling unpredictable traffic patterns efficiently and cost-effectively. It is built on the principle of "design for failure."
The objective is to build a system where the failure of a single component—a VM, a container, or an entire availability zone—does not cause a systemic outage. Resilience is achieved through redundancy across fault domains, automated health checks and recovery, and loose coupling between microservices.
When designing cloud workloads, especially in regulated or multi-tenant environments, security and availability frameworks like the SOC 2 Trust Services Criteria provide a robust set of controls. These are not merely compliance checkboxes; they are established principles for architecting secure, available, and reliable systems.
Making Cost a First-Class Design Concern
Cost optimization cannot be a reactive process; it must be an integral part of the design phase. Globally, public cloud spend is projected to reach $723.4 billion, yet an estimated 32% of cloud budgets are wasted due to idle or over-provisioned resources.
The problem is compounded by a lack of visibility: only 30% of organizations have effective cost monitoring and allocation processes. This is a significant financial and operational blind spot that platforms like OpsMoon are designed to address for CTOs and engineering leaders.
To mitigate this, adopt a proactive FinOps strategy:
- Right-Sizing Resources: Continuously analyze performance metrics (CPU/memory utilization, IOPS, network throughput) to align provisioned resources with actual workload demand. This is an ongoing process, not a one-time task.
- Leveraging Spot Instances: For fault-tolerant, interruptible workloads like batch processing, CI/CD jobs, or ML training, spot instances offer compute capacity at discounts of up to 90% compared to on-demand pricing.
- Implementing FinOps: Foster a culture where engineering teams are aware of the cost implications of their architectural decisions. Use tagging strategies and cost allocation tools to provide visibility and accountability.
By embedding these principles into your development lifecycle, you transition from simply running workloads in the cloud to engineering systems that are performant, resilient, and financially sustainable. This transforms your workloads from sources of technical debt into business accelerators.
A Playbook for Workload Migration and Management
Migrating workloads to the cloud—and managing them effectively post-migration—requires a structured, modern methodology. A "copy and paste" approach is destined for failure. A successful migration hinges on a deep technical assessment of the workload and a clear understanding of the target cloud environment.
The industry-standard "6 R's" framework provides a strategic playbook, offering a spectrum of migration options from minimal-effort rehosting to a complete cloud-native redesign. Each strategy represents a different trade-off between speed, cost, and long-term cloud benefits.
- Rehost (Lift and Shift): The workload is migrated to a cloud IaaS environment with minimal or no modifications. This is the fastest path to exiting a data center but often fails to leverage cloud-native capabilities, potentially leading to higher operational costs and lower resilience.
- Replatform (Lift and Reshape): This strategy involves making targeted cloud optimizations during migration. A common example is migrating a self-managed database to a managed DBaaS offering like Amazon RDS. It offers a pragmatic balance between migration velocity and realizing tangible cloud benefits.
- Refactor/Rearchitect: This is the most intensive approach, involving significant modifications to the application's architecture to fully leverage cloud-native services. This often means decomposing a monolith into microservices, adopting serverless functions, and utilizing managed services for messaging and data storage. It requires the most significant upfront investment but yields the greatest long-term benefits in scalability, agility, and operational efficiency.
The optimal strategy depends on the workload's business criticality, existing technical debt, and its strategic importance. For a more detailed analysis, our guide on how to migrate to cloud provides a comprehensive roadmap for planning and execution.
Modern Management with IaC and CI/CD
Post-migration, workload management must shift from manual configuration to automated, code-driven operations. This is non-negotiable for achieving consistency, reliability, and velocity at scale.
Infrastructure as Code (IaC) is the foundational practice.
Using declarative tools like Terraform or imperative tools like AWS CloudFormation, you define your entire infrastructure—VPCs, subnets, security groups, VMs, load balancers—in version-controlled configuration files. This makes your infrastructure repeatable, auditable, and immutable. Manual "click-ops" changes are eliminated, drastically reducing configuration drift and human error.
An IaC-driven environment guarantees that the infrastructure deployed in production is an exact replica of what was tested in staging, forming the bedrock of reliable, automated software delivery.
This code-centric approach integrates seamlessly into a CI/CD (Continuous Integration/Continuous Deployment) pipeline. These automated workflows orchestrate the build, testing, and deployment of both application code and infrastructure changes in a unified process. This transforms releases from high-risk, manual events into predictable, low-impact, and frequent operations.
The Critical Role of Observability
In complex distributed systems, you cannot manage what you cannot measure. Traditional monitoring (checking the health of individual components) is insufficient. Modern cloud operations require deep observability, which is achieved by unifying three key data types:
- Metrics: Time-series numerical data that quantifies system behavior (e.g., CPU utilization, request latency, error rate). Metrics tell you what is happening.
- Logs: Timestamped, immutable records of discrete events. Logs provide the context to understand why an event (like an error) occurred.
- Traces: A detailed, end-to-end representation of a single request as it propagates through multiple services in a distributed system. Traces show you where in the call stack a performance bottleneck or failure occurred.
By correlating these three pillars, you gain a holistic understanding of your workload's health. This enables proactive anomaly detection, rapid root cause analysis, and continuous performance optimization in a dynamic, microservices-based environment.
How OpsMoon Helps You Master Your Cloud Workloads
Understanding the theory of cloud workloads is necessary but not sufficient. Successfully architecting, migrating, and operating them for optimal performance and cost-efficiency requires deep, hands-on expertise. OpsMoon provides the elite engineering talent to bridge the gap between strategy and execution.
It begins with a free work planning session. We conduct a technical deep-dive into your current workload architecture to identify immediate opportunities for optimization—whether it's right-sizing compute instances, re-architecting for scalability, or implementing a robust observability stack to gain visibility into system behavior.
Connect with Elite DevOps Talent
Our Experts Matcher connects you with engineers from the top 0.7% of global DevOps talent. These are practitioners with proven experience in the technologies that power modern workloads, from Kubernetes and Terraform to Prometheus, Grafana, and advanced cloud-native security tooling.
We believe elite cloud engineering shouldn't be out of reach. Our flexible engagement models and free architect hours are designed to make top-tier expertise accessible, helping you build systems that accelerate releases and enhance reliability.
When you partner with OpsMoon, you gain more than just engineering capacity. You gain a strategic advisor committed to helping you achieve mastery over your cloud environment. Our goal is to empower your team to transform your infrastructure from a cost center into a true competitive advantage.
Got Questions About Cloud Workloads?
Let's address some of the most common technical questions that arise when teams architect and manage cloud workloads. The goal is to provide direct, actionable answers.
What's the Real Difference Between a Workload and an Application?
While often used interchangeably, these terms represent different levels of abstraction. An application is the executable code that performs a business function—the JAR file, the Docker image, the collection of Python scripts.
A workload is the entire operational context that allows the application to run. It encompasses the application code plus its full dependency graph: the underlying compute instances (VMs/containers), the databases it queries, the message queues it uses, the networking rules that govern its traffic, and the specific resource configuration (CPU, memory, storage IOPS) it requires.
Think of it this way: the application is the binary. The workload is the running process, including all the system resources and dependencies it needs to execute successfully. It is the unit of deployment and management in a cloud environment.
How Do You Actually Measure Workload Performance?
Performance measurement is workload-specific; there is no universal KPI. You must define metrics that align with the workload's intended function.
- Transactional APIs: The primary metrics are p99 latency (the response time for 99% of requests) and requests per second (RPS). High error rates (5xx status codes) are a key negative indicator.
- Data Pipelines: Performance is measured by throughput (e.g., records processed per second) and data freshness/lag (the time delay between an event occurring and it being available for analysis).
- Batch Jobs: Key metrics are job completion time and resource utilization efficiency (i.e., did the job use its allocated CPU/memory effectively, or was it over-provisioned?). Cost per job is also a critical business metric.
To capture these measurements, a comprehensive observability platform is essential. Relying solely on basic metrics like CPU utilization is insufficient. You must correlate metrics, logs, and distributed traces to gain a complete, high-fidelity view of system behavior and perform effective root cause analysis.
What Are the Biggest Headaches in Managing Cloud Workloads?
At scale, several technical and operational challenges consistently emerge.
The toughest challenges are not purely technical; they are intersections of technology, finance, and process. Failure in any one of these domains can negate the benefits of migrating to the cloud.
First, cost control and attribution is a persistent challenge. The ease of provisioning can lead to resource sprawl and significant waste. Studies consistently show that overprovisioning and idle resources can account for over 30% of total cloud spend.
Second is maintaining a consistent security posture. In a distributed microservices architecture, the attack surface expands with each new service, API endpoint, and data store. Enforcing security policies, managing identities (IAM), and ensuring data encryption across hundreds of services is a complex, continuous task.
Finally, there's operational complexity. Distributed systems are inherently more difficult to debug and manage than monoliths. As the number of interacting components grows, understanding system behavior, diagnosing failures, and ensuring reliability becomes exponentially more difficult without robust automation, sophisticated observability, and a disciplined approach to release engineering.
Ready to put this knowledge into practice? OpsMoon connects you with top-tier DevOps engineers who specialize in assessing, architecting, and fine-tuning cloud workloads for peak performance and cost-efficiency. Let's start with a free work planning session.
Leave a Reply