Think of the relationship between Site Reliability Engineering (SRE) and DevOps like this: DevOps provides the architectural blueprint for building a house, focusing on collaboration and speed. SRE is the engineering discipline that comes in to pour the foundation, frame the walls, and wire the electricity, ensuring the structure is sound, stable, and won't fall down.
They aren't competing ideas; they're two sides of the same coin, working together to build better software, faster and more reliably.
How SRE Puts DevOps Philosophy into Practice
Many teams jump into DevOps to tear down the walls between developers and operations. The goal is noble: ship software faster, collaborate better, and create a culture of shared ownership. But DevOps is a philosophy—it tells you what you should be doing, but it's often light on the how.
This is where Site Reliability Engineering steps in. SRE provides the hard engineering and data-driven practices needed to make the DevOps vision a reality. It originated at Google out of the sheer necessity of managing massive, complex systems, fundamentally treating operations as a software problem.
SRE is what happens when you ask a software engineer to design an operations function. It’s a discipline that applies software engineering principles to automate IT operations, making systems more scalable, reliable, and efficient.
SRE is all about finding that sweet spot between launching new features and ensuring the lights stay on. It achieves this balance using cold, hard numbers—not just good intentions. This is how SRE gives DevOps its technical teeth.
Bridging Culture with Code
SRE makes the abstract goals of DevOps concrete and measurable. Instead of just saying "we need to be reliable," SRE teams define reliability with mathematical precision through Service Level Objectives (SLOs). These aren't just targets; they're enforced by error budgets, which give teams a clear, data-backed license to innovate or pull back.
This partnership is essential for modern distributed systems. When done right, the impact is huge. Research from the State of DevOps report shows that teams with mature operational practices are 1.8 times more likely to see better business outcomes. This synergy doesn't just stabilize your systems; it directly helps your business move faster without breaking things for your users.
Comparing DevOps Philosophy and SRE Practice
On the surface, DevOps and Site Reliability Engineering (SRE) look pretty similar. Both aim to get better software out the door faster, but they come at the problem from completely different directions. DevOps is a broad cultural philosophy. It’s all about breaking down the walls between teams to make work flow smoother. SRE, on the other hand, is a specific, prescriptive engineering discipline focused on one thing: reliability you can measure.
Here’s a simple way to think about it: DevOps hits the gas pedal on the software delivery pipeline, pushing to get ideas into production as fast as possible. SRE is the sophisticated braking system, making sure that speed doesn't send the whole thing flying off the road.
Goals and Primary Focus
DevOps is fundamentally concerned with the how of software delivery. It’s the culture, the processes, and the tools that get developers and operations folks talking and working together instead of pointing fingers. The main goal? Shorten the development lifecycle from start to finish. If you want a deeper dive, you can explore the DevOps methodology in our detailed guide.
SRE, by contrast, has a laser focus on a single, non-negotiable outcome: production stability and performance. Its goals aren't philosophical; they're mathematical. SREs use hard data to find the perfect, calculated balance between shipping cool new features and keeping the lights on for users.
This difference creates very different pictures of success. A DevOps team might pop the champagne after cutting deployment lead time in half. An SRE team celebrates maintaining 99.95% availability while the company was shipping features at a breakneck pace.
Metrics and Decision Making
You can really see the difference when you look at what each discipline measures. DevOps tracks workflow efficiency, while SRE tracks the actual experience of your users.
- DevOps Metrics: These are all about the pipeline. Think Deployment Frequency (how often can we ship?), Lead Time for Changes (how long from commit to production?), and Change Failure Rate (what percentage of our deployments break something?). These are often measured using DORA metrics.
- SRE Metrics: This is where the math comes in. SRE is built on Service Level Indicators (SLIs), which are direct measurements of how your service is behaving (like request latency), and Service Level Objectives (SLOs), the target goals for those SLIs.
The most powerful concept SRE brings to the site reliability engineering devops conversation is the error budget. It's derived directly from an SLO—for example, a 99.9% uptime SLO gives you a 0.1% error budget. This isn't just a number; it's a data-driven tool that dictates the pace of development.
An error budget is the quantifiable amount of unreliability a system is allowed to have. If the system is operating well within its SLO, the team is free to use the remaining budget to release new features. If the budget is exhausted, all new feature development is frozen until reliability is restored.
This simple tool completely changes the conversation. It removes emotion and office politics from the "should we ship it?" debate. The error budget makes the decision for you.
DevOps Philosophy vs SRE Implementation
To really nail down the distinction, let's put them head-to-head. The following table shows how the broad cultural ideas of DevOps get translated into concrete, engineering-driven actions by SRE.
| Aspect | DevOps Philosophy | SRE Implementation |
|---|---|---|
| Primary Goal | Increase delivery speed and remove cultural silos. | Maintain a specific, quantifiable level of production reliability. |
| Core Metric | Workflow velocity (e.g., Lead Time, Deployment Frequency). | User happiness (quantified via SLIs and SLOs). |
| Failure Approach | Minimize Change Failure Rate through better processes. | Manage risk with a calculated error budget. |
| Key Activity | Automating the CI/CD pipeline. | Defining SLOs and automating operational toil. |
| Team Focus | End-to-end software delivery lifecycle. | Production operations and system stability. |
At the end of the day, DevOps gives you the "why"—the cultural push for speed and collaboration. SRE provides the "how"—the engineering discipline, hard metrics, and practical tools to achieve that speed without sacrificing the reliability that keeps your users happy and your business running.
Putting the Core Pillars of SRE Into Practice
Moving from high-level philosophy to the day-to-day grind of SRE means getting serious about four core pillars. These aren't just buzzwords; they're the engineering disciplines that give SRE its teeth. Get them right, and you’ll completely change how your teams handle reliability, risk, and the daily operational fire drills.
This is where the abstract ideas of DevOps get real, backed by the hard data and engineering rigor of SRE. Let's dig into how to actually implement these foundational practices.
Define Reliability With SLOs and Error Budgets
First things first: you have to stop talking about reliability in vague, feel-good terms and start defining it with math. This all starts with Service Level Objectives (SLOs), which are precise, user-centric targets for your system's performance.
An SLO is built on a Service Level Indicator (SLI), which is just a direct measurement of your service's behavior. A classic SLI for an API, for example, is request latency—how long it takes to give a response. The SLO then becomes the goal you set for that SLI over a certain amount of time.
A Real-World Example: Setting an API Latency SLO
- Pick an SLI: Milliseconds it takes to process an
HTTP GETrequest for a critical user endpoint. The Prometheus query for this might look like:http_request_duration_seconds_bucket{le="0.3", path="/api/v1/user"}. - Define the SLO: "99.5% of
GETrequests to the/api/v1/userendpoint will complete in under 300ms over a rolling 28-day period."
This single sentence instantly creates your error budget. The math is simple: it's just 100% - your SLO %, which in this case is 0.5%. This means that for every 1,000 requests, you can "afford" for up to 5 of them to take longer than 300ms without breaking your promise to users.
This budget is now your currency for taking calculated risks. Is the budget healthy? Great, ship that new feature. Is it running low? All non-essential deployments get put on hold until reliability improves.
Systematically Eliminate Toil
Toil is the absolute enemy of SRE. It’s the repetitive, manual, tactical work that provides zero lasting engineering value and scales right alongside your service—and not in a good way. Think about tasks like manually spinning up a test environment, restarting a stuck service, or patching a vulnerability on a dozen servers one by one.
SREs are expected to spend at least 50% of their time on engineering projects, and the number one target for that effort is automating away toil. It’s a systematic hunt.
How to Find and Destroy Toil
- Log Everything: For a couple of weeks, have your team log every single manual operational task they perform. Use a simple spreadsheet or a Jira project.
- Analyze and Prioritize: Go through the logs and pinpoint the tasks that eat up the most time or happen most often. Calculate the man-hours spent per month on each task.
- Automate It: Write a script, build a self-service tool, or configure an automation platform to do the job instead. A Python script using
boto3for AWS tasks is a common starting point. - Measure the Impact: Track the hours saved and pour that time back into high-value engineering, like improving system architecture.
For example, if a team is burning three hours a week manually rotating credentials, an SRE would build an automated system using a tool like HashiCorp Vault to handle it. That one project kills that specific toil forever, freeing up hundreds of engineering hours over the course of a year.
Master Incident Response and Blameless Postmortems
Even the best-built systems are going to fail. What sets SRE apart is its approach to failure. The goal isn't to prevent every single incident—that's impossible. The goal is to shrink the impact and learn from every single one so it never happens the same way twice.
A crucial part of SRE is having a rock-solid incident management process and a culture of learning. A structured approach like Mastering the 5 Whys Method for Root Cause Analysis can be a game-changer here. It forces teams to dig past the surface symptoms to uncover the real, systemic issues that led to an outage.
A blameless postmortem focuses on identifying contributing systemic factors, not on pointing fingers at individuals. The fundamental belief is that people don't fail; the system allowed the failure to happen.
This cultural shift is everything. When engineers feel safe to talk about what really happened without fear of blame, the organization gets an honest, technically deep understanding of what went wrong. For a deeper dive into building this out, check out some incident response best practices in our guide. Every single postmortem must end with a list of concrete action items, complete with owners and deadlines, to fix the underlying flaws.
Conduct Proactive Capacity Planning
The final pillar is looking ahead with proactive capacity planning. SREs don’t just wait for a service to crash under heavy traffic; they use data to see the future and scale the infrastructure before it becomes a problem. This isn't a one-off project; it’s a continuous, data-driven cycle.
It involves analyzing organic growth trends (like new user sign-ups) and keeping an eye on non-organic events (like a big marketing launch). By modeling this data, SREs can forecast exactly when a system will hit its limits—be it CPU, memory, network bandwidth, or database connections. For example, using historical time-series data from Prometheus, an SRE can apply a linear regression model to predict when CPU utilization will cross the 80% threshold. This allows them to add more capacity or optimize what’s already there long before users even notice a slowdown. It's this forward-thinking approach that keeps things fast and reliable, even as the business grows like crazy.
Your Roadmap to a Unified SRE and DevOps Model
Making the switch to a blended site reliability engineering devops model is a journey, not just flipping a switch. It calls for a smart, phased rollout that builds momentum by starting small and proving its worth early on. This roadmap lays out a practical way to weave SRE's engineering discipline into your existing DevOps culture.
Think of it like this: you wouldn't rewrite your entire application in one big bang. You’d start with a single microservice. The same idea applies here.
Phase 1: Laying the Foundation
This first phase is all about learning and setting a baseline. The real goal is to demonstrate the value of SRE on a small scale before you try to take over the world. This approach keeps risk low and helps you build the internal champions you'll need for a wider rollout.
Your first move is to pick a pilot project. You want a service that’s important enough for people to care about, but not so tangled that it becomes a nightmare. A key internal-facing tool or a single, well-understood microservice are perfect candidates.
Once you’ve got your pilot service, the fun begins. Your immediate goals should be to:
- Define Your First SLOs: Sit down with product owners and developers to hash out one or two critical Service Level Objectives. For an API, this might be latency. For a data processing pipeline, it might be freshness. The point is to make it measurable and tied to what your users actually experience.
- Establish a Reliability Baseline: You can't improve what you don't measure. Get your pilot service instrumented to track its SLIs and SLOs for a few weeks. For a web service, this means exporting metrics like latency and HTTP status codes to a system like Prometheus. This data gives you an honest look at its current performance and a starting line to measure improvements against.
- Form a Virtual Team: Pull together a small group of enthusiastic developers and ops engineers to act as the first SRE team for this service. This crew will learn the ropes, champion the practices, and become your go-to experts.
The point of this first phase isn't perfection; it's about gaining clarity. Just by defining a simple SLO and measuring it, you're forcing a data-driven conversation about reliability that probably hasn’t happened before.
Phase 2: Building Structure and Policy
After you've got a win under your belt with the pilot, it's time to make things official. This phase is all about creating the structures and policies that let SRE scale beyond just one team. This is where you figure out how SRE will actually operate inside your engineering org.
You'll need to think about how to structure your SRE teams, as each model has its pros and cons.
- Embedded SREs: An SRE is placed directly on a specific product or service team. This fosters deep product knowledge and super tight collaboration.
- Centralized SRE Team: A single team acts like internal consultants, sharing their expertise and building common tools for all the other teams to use.
- Hybrid Model: A central team builds the core platform and tools, while a few embedded SREs work directly with the most critical service teams.
Right alongside the team structure, you need to create and enforce your error budget policies. This is the secret sauce that turns your SLOs from a pretty dashboard into a powerful tool for making decisions. Write down a clear policy: when a service burns through its error budget, all new feature development stops. The team's entire focus shifts to reliability work. This step is what gives SRE real teeth.
This workflow shows the core pillars that guide an SRE's day-to-day, from setting targets all the way to continuous improvement.
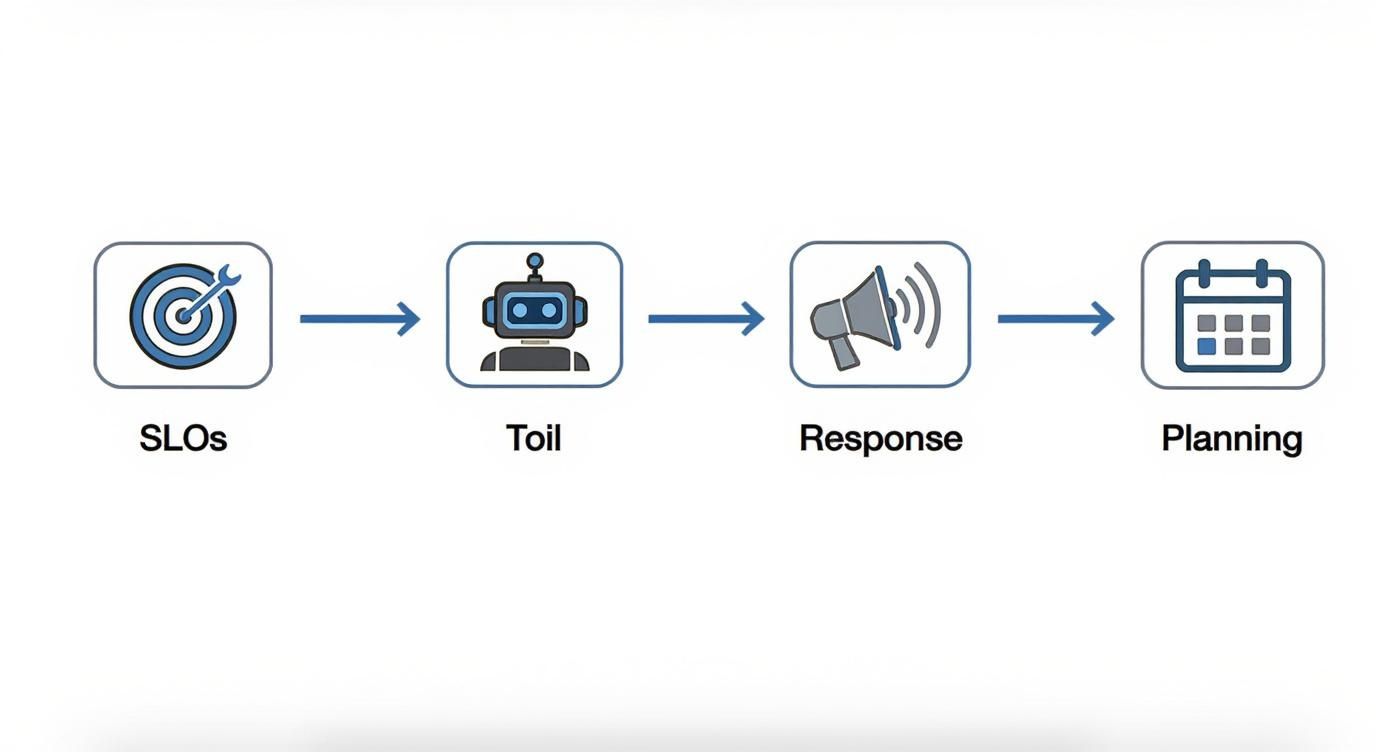
The flow starts with data-driven SLOs, which directly influence everything that follows, from how teams handle incidents to how they plan their next sprint.
Phase 3: Scaling and Maturing the Practice
The final phase is all about making SRE part of your engineering culture's DNA. With a solid foundation and clear policies in place, you can now focus on scaling the practice and taking on more advanced challenges. The ultimate goal is to make reliability a shared responsibility that everyone owns by default.
This phase is defined by a serious investment in automation and tooling. You should be focused on:
- Building an Observability Stack: It's time to go beyond basic metrics. Implement a full-blown platform that gives you deep insights through metrics, logs, and distributed tracing. This gives your teams the data they need to debug nasty, complex issues in production—fast.
- Advanced Toil Automation: Empower your SREs to build self-service tools and platforms that let developers manage their own operational tasks safely. This could be anything from automated provisioning and canary deployment pipelines to self-healing infrastructure.
- Cultivating a Blameless Culture: Make blameless postmortems a non-negotiable for every significant incident. The focus must always be on fixing systemic problems, not pointing fingers at individuals. This builds the psychological safety needed for honest and effective problem-solving.
By walking through these phases, you can weave SRE practices into your DevOps world in a way that’s manageable, measurable, and built to last.
Building Your SRE and DevOps Toolchain
A high-performing site reliability engineering devops culture isn’t built on philosophy alone; it runs on a well-integrated set of tools. These platforms are more than just automation engines. They create the crucial feedback loops that turn raw production data into real, actionable engineering tasks.
Building an effective toolchain means picking the right solution for each stage of the software lifecycle and, just as importantly, making sure they all talk to each other seamlessly. This is how you shift from reactive firefighting to a proactive, data-driven engineering practice, giving your teams the visibility and control they need to manage today’s complex systems.
Observability and Monitoring Tools
You simply can't make a system reliable if you can't see what's happening inside it. This is where observability tools come in. They provide the critical metrics, logs, and traces that let you understand system behavior and actually measure your SLOs.
- Prometheus: Now the de facto standard for collecting time-series metrics, this open-source toolkit is a must-have, especially if you're running on Kubernetes.
- Grafana: The perfect sidekick to Prometheus. Grafana lets you build slick, custom dashboards to visualize your metrics and keep a close eye on SLO compliance in real time.
- Datadog: A comprehensive platform that brings infrastructure monitoring, APM, and log management together under one roof, giving you a single pane of glass to watch over your entire stack.
These tools are your foundation. Without the data they provide, concepts like error budgets are just abstract theories. For a deeper dive, check out our guide on the best infrastructure monitoring tools.
CI/CD and Automation Platforms
Once the code is written, it needs a safe, repeatable path into production. CI/CD (Continuous Integration/Continuous Deployment) platforms automate the build, test, and deploy process, slashing human error and cranking up your delivery speed.
And automation doesn't stop at the pipeline. Tools for infrastructure as code (IaC) and configuration management are just as vital for creating stable, predictable environments every single time.
- GitLab CI/CD: A powerful, all-in-one solution that covers the entire DevOps lifecycle, from source code management and CI/CD right through to monitoring.
- Jenkins: The classic, highly extensible open-source automation server. With thousands of plugins, it can be customized to handle literally any build or deployment workflow you can dream up.
- Ansible: An agentless configuration management tool that's brilliant at automating application deployments, configuration changes, and orchestrating complex multi-step workflows.
Integrating these automation tools is the whole point. The end goal is a hands-off process where a code commit automatically kicks off a series of quality gates and deployments, making sure every change is thoroughly vetted before it ever sees a user.
Incident Management Systems
Let's be real: things are going to break. When they do, a fast, coordinated response is everything. Incident management systems act as the command center for your response efforts, making sure the right people get alerted with the right context to fix things—fast.
These platforms automate on-call schedules, escalations, and stakeholder updates, freeing up engineers to actually focus on solving the problem instead of managing the chaos.
- PagerDuty: A leader in the digital operations space, providing rock-solid alerting, on-call scheduling, and powerful automation to streamline incident response.
- Opsgenie: An Atlassian product offering flexible alerting and on-call management, with deep integrations into the Jira ecosystem for easy ticket tracking.
As companies feel the sting of downtime, these systems have become standard issue. The rise of SRE itself is a direct answer to the complexity of modern software. In fact, by 2025, an estimated 85% of organizations will be actively using SRE practices to keep their services available and resilient. You can explore more about this trend in this detailed report on SRE adoption.
Collaboration Hubs
Finally, none of these tools can operate in a silo. Collaboration hubs are the glue that holds the entire toolchain together. They provide a central place for communication, documentation, and tracking the work that needs to get done.
- Slack: The go-to platform for real-time communication. It's often integrated with monitoring and CI/CD tools to push immediate notifications into dedicated channels, so everyone stays in the loop.
- Jira: A powerful project management tool used to turn insights from postmortems and observability data into trackable engineering tickets, effectively closing the feedback loop from production back to development.
Building and Growing Your SRE Team
Let's be honest: building a world-class Site Reliability Engineering team is tough. You're not just looking for ops engineers who can write some scripts. You need true systems thinkers—people who see operations as a software engineering problem waiting to be solved.
The talent pool is incredibly competitive, and for good reason. The average SRE salary hovers around $130,000, and a whopping 88% of SREs feel their strategic importance has shot up recently. This isn't a role you can fill casually. If you want to dig deeper into where the industry is heading, the insights from the 2025 SRE report are a great place to start.
Structuring Your Technical Interviews
If you want to find the right people, your interview process has to be more than just another LeetCode grind. You need to test for a reliability-first mindset and a real knack for debugging complex systems under pressure.
A solid SRE interview loop should always include:
- Systems Design Scenarios: Hit them with an open-ended challenge. Something like, "Design a scalable, resilient image thumbnailing service." This isn't about getting the "right" answer; it's about seeing how they think through failure modes, redundancy, and the inevitable trade-offs.
- Live Debugging Exercises: Throw a simulated production fire at them—maybe a sluggish database query or a service that keeps crashing. Watch how they troubleshoot in real-time. This is where you see their thought process and how they handle the heat.
- Automation and Toil Reduction Questions: Ask about a time they automated a painfully manual task. Their answer will tell you everything you need to know about their commitment to crushing operational toil.
Upskilling Your Internal Talent
Don't get so focused on external hiring that you overlook the goldmine you might already have. Some of your best future SREs could be hiding in plain sight as software developers or sysadmins on your current teams.
Think about creating an internal upskilling program. Pair your seasoned developers with your sharpest operations engineers on reliability-focused projects. This creates a powerful cross-pollination of skills. Developers learn the messy realities of production, and ops engineers get deep into automation. That's how you forge the hybrid expertise that defines a great SRE.
Fostering a culture of psychological safety is completely non-negotiable for an SRE team. People have to feel safe enough to experiment, to fail, and to hold blameless postmortems without pointing fingers. It's the only way you'll ever unearth the real systemic issues and make lasting improvements.
It also pays to get smart about the numbers behind hiring. Understanding your metrics can make a huge difference in managing your budget as the team grows. Learning how to optimize recruitment costs for your SRE team will help you build a sustainable pipeline for the long haul. A smart mix of strategic hiring and internal development is your ticket to a resilient and high-impact SRE function.
Frequently Asked Questions About SRE and DevOps
Even with the best roadmap, a few common questions always pop up when you start blending site reliability engineering devops. Getting these cleared up early saves a ton of confusion and keeps your teams pulling in the same direction.
Here are the straight answers to the questions we hear most often.
Can We Have SRE Without A DevOps Culture?
You technically can, but it's like trying to run a high-performance engine on cheap gas. It just doesn't work well, and you miss the entire point. SRE gives you the engineering discipline, but a DevOps culture provides the collaborative fuel.
Without that culture of shared ownership, SREs quickly turn into a new version of the old-school ops team, stuck in a silo fighting fires alone. This rebuilds the exact wall that DevOps was created to tear down. The real magic happens when everyone starts thinking like an SRE.
The real power is unleashed when a developer, empowered by SRE tools and data, instruments their own code to meet an SLO. That is the fusion of SRE and DevOps in action.
What Is The Most Important First Step In Adopting SRE?
Pick one critical service and define its Service Level Objectives (SLOs). This is, without a doubt, the most important first step. Why? Because it forces a data-driven conversation about what "reliability" actually means to your users and the business.
This simple exercise brings incredible clarity. It transforms reliability from a fuzzy concept into a hard, mathematical target. It also lays the technical groundwork for every other SRE practice that follows, like error budgets and automating away toil.
Is SRE Just A New Name For The Operations Team?
Not at all, and this is a crucial distinction to make. The biggest difference is that SREs are engineers first. They are required to spend at least 50% of their time on engineering projects aimed at making the system more automated, scalable, and reliable.
Your traditional operations team is often 100% reactive, jumping from one ticket to the next. SRE is a proactive discipline focused on engineering problems so that systems can eventually run themselves.
Ready to bridge the gap between your DevOps philosophy and SRE practice? OpsMoon provides the expert remote engineers and strategic guidance you need. Start with a free work planning session to build your reliability roadmap. Learn more at OpsMoon.
Leave a Reply