The software development life cycle is a systematic process with six core stages: Planning, Design, Development, Testing, Deployment, and Maintenance. This framework provides a structured methodology for engineering teams to transform a conceptual idea into a production-ready system. It's the engineering discipline that prevents software projects from descending into chaos.
An Engineering Roadmap for Building Software
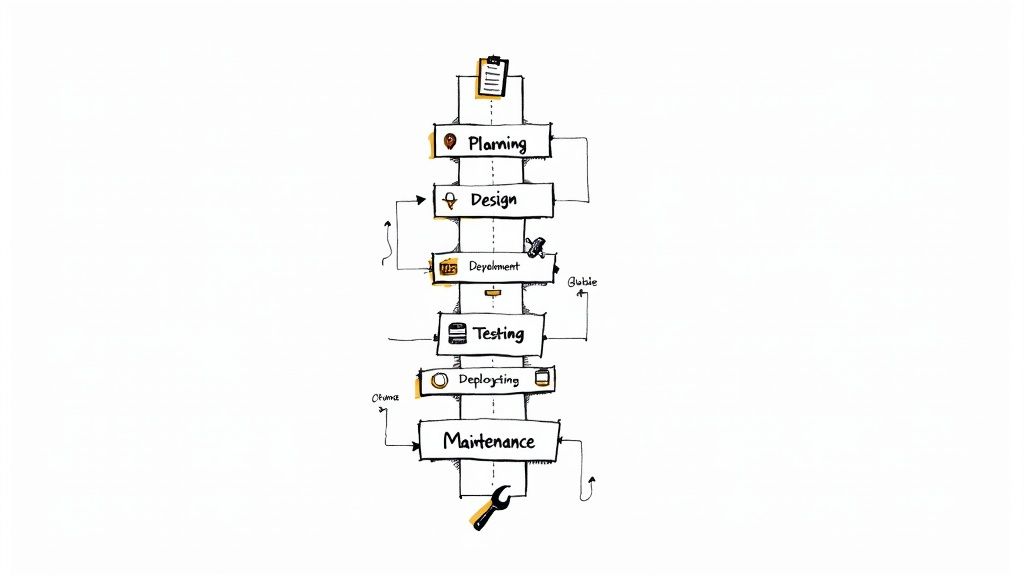
Constructing a multi-story building without detailed architectural blueprints and structural engineering analysis would be negligent. The software development life cycle (SDLC) serves as the equivalent blueprint for software engineering, breaking down the complex process of software creation into a sequence of discrete, manageable, and verifiable phases.
Adhering to a structured SDLC is the primary defense against common project failures. By rigorously defining goals, artifacts, and exit criteria for each stage, teams can mitigate risks like budget overruns, schedule slippage, and uncontrolled scope creep. It transforms the abstract art of programming into a predictable engineering process.
The Engineering Rationale for a Structured Cycle
The need for a formal methodology became evident during the "software crisis" of the late 1960s, a period defined by catastrophic project failures due to a lack of engineering discipline. The first SDLC models were developed to impose order, manage complexity, and improve software quality and reliability.
By executing a defined sequence of stages, engineering teams ensure that each phase is built upon a verified and validated foundation. This systematic approach exponentially increases the probability of delivering a high-quality product that meets specified requirements and achieves business objectives.
Mastering the software development cycle is a mission-critical competency for any engineering team, whether developing a simple static website or a complex distributed microservices architecture. While the tooling and specific practices for a mobile app development lifecycle may differ from a cloud-native backend service, the core engineering principles persist.
Before delving into the technical specifics of each stage, this overview provides a high-level summary.
Overview of the Six SDLC Stages
| Stage | Primary Goal | Key Technical Artifacts |
|---|---|---|
| 1. Planning | Define project scope, technical feasibility, and resource requirements. | Software Requirement Specification (SRS), Feasibility Study, Resource Plan. |
| 2. Design | Architect the system's structure, components, interfaces, and data models. | High-Level Design (HLD), Low-Level Design (LLD), API Contracts, Database Schemas. |
| 3. Development | Translate design specifications into executable, version-controlled source code. | Source Code (e.g., in Git), Executable Binaries/Containers, Unit Tests. |
| 4. Testing | Systematically identify and remediate defects to ensure conformance to the SRS. | Test Plans, Test Cases, Bug Triage Reports, UAT Sign-off. |
| 5. Deployment | Release the validated software artifact to a production environment. | Production Infrastructure (IaC), CI/CD Pipeline Logs, Release Notes. |
| 6. Maintenance | Monitor, support, and enhance the software post-release. | Bug Patches, Version Updates, Performance Metrics, Security Audits. |
This table represents the logical flow. Now, let's deconstruct the technical activities and deliverables required in each of these six stages.
Laying the Foundation with Planning and Design
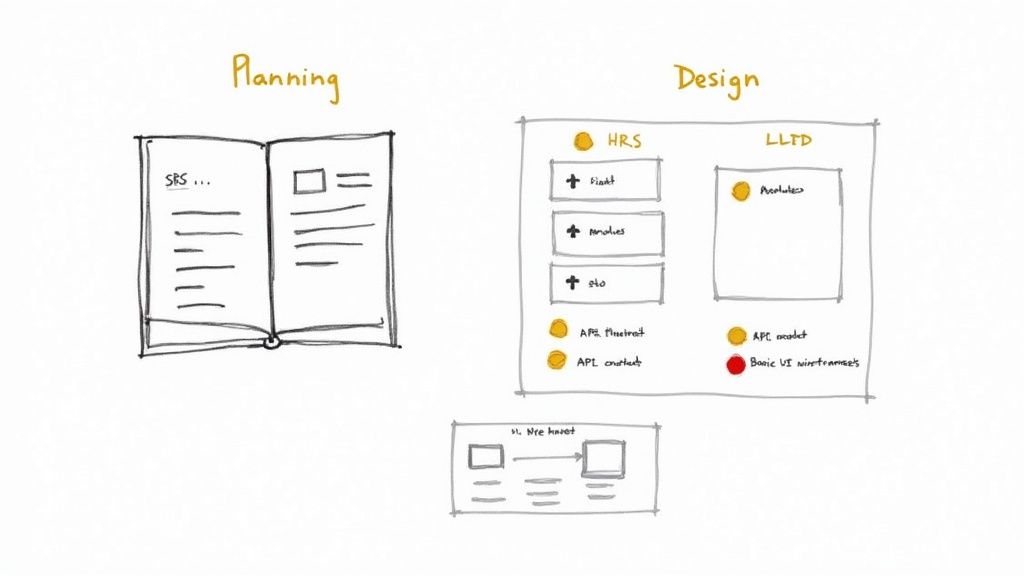
The success or failure of a software project is often determined in these initial phases. A robust planning and design stage is analogous to a building's foundation; deficiencies here will manifest as structural failures later, resulting in costly and time-consuming rework.
The process begins with Planning (or Requirements Analysis), where the primary objective is to convert high-level business needs into a precise set of verifiable technical and functional requirements. This is not a simple feature list; it is a rigorous definition of the system's expected behavior and constraints.
The canonical deliverable from this stage is the Software Requirement Specification (SRS). This document serves as the single source of truth for the entire project, contractually defining every functional and non-functional requirement the software must fulfill.
Crafting the Software Requirement Specification
A technically sound SRS is the bedrock of the entire development process. It must unambiguously define two classes of requirements:
- Functional Requirements: These specify the system's behavior—what it must do. For example: "The system shall authenticate users via an OAuth 2.0 Authorization Code grant flow," or "The system shall generate a PDF report of quarterly sales, aggregated by product SKU."
- Non-Functional Requirements (NFRs): These define the system's operational qualities—how it must be. Examples include: "The P95 latency for all public API endpoints must be below 200ms under a load of 1,000 requests per second," or "The database must support 10,000 concurrent connections while maintaining data consistency."
The formalization of requirements engineering evolved significantly between 1956 and 1982. This era introduced methodologies like the Software Requirement Engineering Methodology (SREM), which pioneered the use of detailed specification languages to mitigate risk before implementation. A review of the history of these foundational methods provides context for modern practices.
Translating Requirements into a Technical Blueprint
With a version-controlled SRS, the Design phase commences. Here, the "what" (requirements) is translated into the "how" (technical architecture). This process is typically bifurcated into high-level and low-level design.
First is the High-Level Design (HLD). This provides a macroscopic view of the system architecture. The HLD defines major components (e.g., microservices, APIs, databases, message queues) and their interactions, often using diagrams like C4 models or UML component diagrams. It outlines technology choices (e.g., Kubernetes for orchestration, PostgreSQL for the database) and architectural patterns (e.g., event-driven, CQRS).
Following the HLD, the Low-Level Design (LLD) provides a microscopic view. This is where individual modules are specified in detail. Key LLD activities include:
- Database Schema Design: Defining tables, columns, data types (e.g.,
VARCHAR(255),TIMESTAMP), indexes, and foreign key constraints. - API Contract Definition: Using a specification like OpenAPI/Swagger to define RESTful endpoints, HTTP methods, request/response payloads (JSON schemas), and authentication schemes (e.g., JWT Bearer tokens).
- Class and Function Design: Detailing the specific classes, methods, function signatures, and algorithms that will be implemented in the code.
The HLD and LLD together form a complete technical blueprint, ensuring that every engineer understands their part of the system and how it interfaces with the whole, leading to a coherent, scalable, and maintainable application.
Building and Validating with Code and Tests
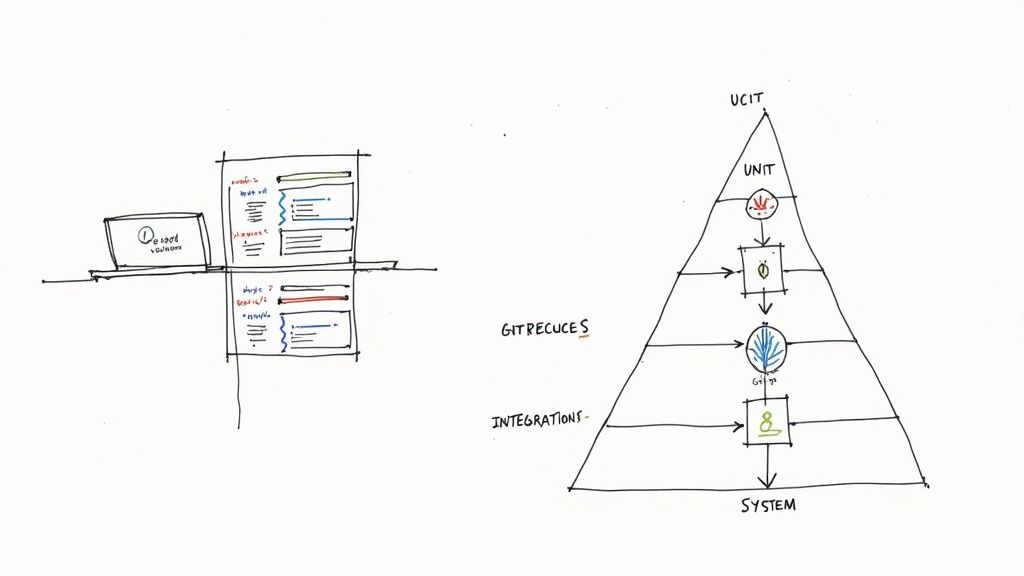
With the architectural blueprint finalized, the Development stage begins. Here, abstract designs are translated into concrete, machine-executable code. This phase demands disciplined engineering practices to ensure code quality, consistency, and maintainability.
Actionable best practices are non-negotiable. Enforcing language-specific coding standards (e.g., PSR-12 for PHP, PEP 8 for Python) using automated linters ensures code readability and uniformity. This dramatically reduces the cognitive load for future maintenance and debugging.
Furthermore, version control using a distributed system like Git is mandatory for modern software engineering. It enables parallel development through branching strategies (e.g., GitFlow, Trunk-Based Development), provides a complete audit trail of every change, and facilitates code reviews via pull/merge requests.
From Code to Quality Assurance
As soon as code is committed, the Testing stage begins in parallel. This is not a terminal gate but a continuous process designed to detect and remediate defects as early as possible. An effective way to structure this is the testing pyramid, a model that prioritizes different types of tests for optimal efficiency.
The pyramid represents a layered testing strategy:
- Unit Tests: These form the pyramid's base. They are fast, isolated tests that validate a single "unit" of code (a function or method) in memory, often using mock objects to stub out dependencies. They should cover all logical paths, including edge cases and error conditions.
- Integration Tests: The middle layer verifies the interaction between components. Does the application service correctly read/write from the database? Does the API gateway successfully route requests to the correct microservice? These tests are crucial for validating data flow and inter-service contracts.
- System Tests (End-to-End): At the apex, these tests simulate a full user workflow through the entire deployed application stack. They are the most comprehensive but also the slowest and most brittle, so they should be used judiciously to validate critical user journeys.
This layered approach ensures that the majority of defects are caught quickly and cheaply at the unit level, preventing them from propagating into more complex and expensive-to-debug system-level failures.
Advanced Testing Strategies and Release Cycles
Modern development practices integrate testing even more deeply. In Test-Driven Development (TDD), the workflow is inverted: a developer first writes a failing automated test case that defines a desired improvement or new function, and then writes the minimum production code necessary to make the test pass.
This "Red-Green-Refactor" cycle guarantees 100% test coverage for new functionality by design. The tests act as executable specifications and a regression safety net, preventing future changes from breaking existing functionality.
The development and testing process is further segmented into release cycles like pre-alpha, alpha, and beta. Alpha releases are for internal validation by QA teams. Beta releases are distributed to a select group of external users to uncover defects that only emerge under real-world usage patterns. Early feedback from these cycles can reduce post-release defects by up to 75%. For a comprehensive overview, see how release cycles are structured on Wikipedia.
Automation is the engine driving this rapid feedback loop. Automated testing frameworks (e.g., JUnit, Pytest, Cypress) integrated into a CI/CD pipeline execute tests on every code commit, providing immediate feedback on defects. This is the practical application of the shift-left testing philosophy—integrating quality checks as early as possible in the development workflow. Our technical guide explains what is shift-left testing in greater detail. This proactive methodology ensures quality is an intrinsic part of the code, not an afterthought.
Getting It Live and Keeping It Healthy: Deployment and Maintenance
Following successful validation, the final stages are Deployment and Maintenance. These phases transition the software from a development artifact to a live operational service and ensure its long-term health and reliability.
Deployment is the technical process of promoting validated code into a production environment. This is a high-stakes operation that requires a precise, automated strategy to minimize service disruption and provide a rapid rollback path. A failed deployment can have immediate and severe business impact.
The era of monolithic "big bang" releases with extended downtime is over. Modern engineering teams employ sophisticated deployment strategies to de-risk the release process and ensure high availability.
This infographic illustrates the transition from the deployment event to the ongoing maintenance cycle.
As shown, deployment is not the end but the beginning of the software's operational life.
Advanced Deployment Strategies
To mitigate the risk of production failures, engineers use controlled rollout strategies that enable immediate recovery. Three of the most effective techniques are:
- Blue-Green Deployment: This strategy involves maintaining two identical production environments: "Blue" (the current live version) and "Green" (the new version). Production traffic is directed to Blue. The new code is deployed and fully tested in the Green environment. To release, a load balancer or DNS switch redirects all traffic from Blue to Green. If issues are detected, traffic is instantly reverted to Blue, providing a near-zero downtime rollback.
- Canary Deployment: This technique releases the new version to a small subset of production traffic (the "canaries"). The system is monitored for increased error rates, latency, or other negative signals from this group. If the new version performs as expected, traffic is gradually shifted from the old version to the new one until the rollout is complete. This limits the "blast radius" of a faulty release.
- Rolling Deployment: In this approach, the new version is deployed to servers in the production pool incrementally. One server (or a small batch) is taken out of the load balancer, updated, and re-added. This process is repeated until all servers are running the new version. This ensures the service remains available throughout the deployment, albeit with a mix of old and new versions running temporarily.
These strategies are cornerstones of modern DevOps and are typically automated via CI/CD pipelines. For a technical breakdown of automated release patterns, see our guide on continuous deployment vs continuous delivery.
The Four Types of Software Maintenance
Once deployed, the software enters the Maintenance stage, a continuous process of supporting, correcting, and enhancing the system.
Maintenance often accounts for over 60% of the total cost of ownership (TCO) of a software system. Architecting for maintainability and budgeting for this phase is critical for long-term viability.
Maintenance activities are classified into four categories:
- Corrective Maintenance: The reactive process of diagnosing and fixing production bugs reported by users or monitoring systems.
- Adaptive Maintenance: Proactively modifying the software to remain compatible with a changing environment. This includes updates for new OS versions, security patches for third-party libraries, or adapting to changes in external API dependencies.
- Perfective Maintenance: Improving existing functionality based on user feedback or performance data. This includes refactoring code for better performance, optimizing database queries, or enhancing the user interface.
- Preventive Maintenance: Modifying the software to prevent future failures. This involves activities like refactoring complex code (paying down technical debt), improving documentation, and adding more comprehensive logging and monitoring to increase observability.
Effective maintenance is impossible without robust observability tools. Comprehensive logging, metric dashboards (e.g., Grafana), and distributed tracing systems (e.g., Jaeger) are essential for diagnosing and resolving issues before they impact users.
Accelerating the Cycle with DevOps Integration
The traditional SDLC provides a logical framework, but modern software delivery demands velocity and reliability. DevOps is a cultural and engineering practice that accelerates this framework.
DevOps is not a replacement for the SDLC but an operational model that supercharges it. It transforms the SDLC from a series of siloed, sequential handoffs into an integrated, automated, and collaborative workflow. The primary objective is to eliminate the friction between Development (Dev) and Operations (Ops) teams.
Instead of developers "throwing code over the wall" to QA and Ops, DevOps fosters a culture of shared ownership, enabled by an automated toolchain. This integration directly addresses the primary bottlenecks of traditional models, converting slow, error-prone manual processes into high-speed, repeatable automations.
The performance impact is significant. By integrating DevOps principles into the SDLC, elite-performing organizations deploy code hundreds of times more frequently than their low-performing counterparts, with dramatically lower change failure rates. They move from quarterly release cycles to multiple on-demand deployments per day.
This is achieved by mapping specific DevOps practices and technologies onto each stage of the software development lifecycle.
Mapping DevOps Practices to the SDLC
DevOps injects automation and collaborative tooling into every SDLC phase to improve velocity and quality. This requires a cultural shift towards shared responsibility and is enabled by specific technologies. You can explore this further in our technical guide on what is DevOps methodology.
Here is a practical mapping of DevOps practices to SDLC stages:
- Development & Testing: The core is the Continuous Integration/Continuous Delivery (CI/CD) pipeline. On every
git push, an automated workflow (e.g., using Jenkins, GitLab CI, or GitHub Actions) compiles the code, runs unit and integration tests, performs static analysis, and scans for security vulnerabilities. This provides immediate feedback to developers, reducing the Mean Time to Resolution (MTTR) for defects. - Deployment: Infrastructure as Code (IaC) is a game-changer. Using tools like Terraform or AWS CloudFormation, teams define their entire production infrastructure (servers, networks, load balancers) in version-controlled configuration files. This allows for the automated, repeatable, and error-free provisioning of identical environments, eliminating "it works on my machine" issues.
- Maintenance & Monitoring: Continuous Monitoring tools (e.g., Prometheus, Datadog) provide real-time telemetry on application performance, error rates, and resource utilization. This data creates a tight feedback loop, enabling proactive issue detection and feeding actionable insights back into the Planning stage for the next development cycle.
The operational difference between a traditional and a DevOps-driven SDLC is stark. For those looking to build a career in this field, the demand for skilled engineers is high, with many remote DevOps job opportunities available.
Traditional SDLC vs. DevOps-Integrated SDLC
This side-by-side comparison highlights the fundamental shift from a rigid, sequential process to a fluid, collaborative, and automated loop.
| Aspect | Traditional SDLC Approach | DevOps-Integrated SDLC Approach |
|---|---|---|
| Release Frequency | Low-frequency, high-risk "big bang" releases (quarterly). | High-frequency, low-risk, incremental releases (on-demand). |
| Testing | A manual, late-stage QA phase creating a bottleneck. | Automated, continuous testing integrated into the CI/CD pipeline. |
| Deployment | Manual, error-prone process with significant downtime. | Zero-downtime, automated deployments using strategies like blue-green. |
| Team Collaboration | Siloed teams (Dev, QA, Ops) with formal handoffs. | Cross-functional teams with shared ownership of the entire lifecycle. |
| Feedback Loop | Long, delayed feedback, often from post-release user bug reports. | Immediate, real-time feedback from automated tests and monitoring. |
The DevOps model is engineered for velocity, quality, and operational resilience by embedding automation and collaboration into every step of the software development lifecycle.
Still Have Questions About the SDLC?
Even with a detailed technical map of the software development cycle stages, practical application raises many questions. Here are answers to some of the most common technical queries.
What Is the Most Important Stage of the Software Development Cycle?
While every stage is critical, from a technical risk and cost perspective, the Planning and Requirements Analysis stage has the highest leverage.
This is based on the principle of escalating cost-of-change. An error in the requirements specification is relatively cheap to fix. That same logical error, if discovered after the system has been coded, tested, and deployed, can be orders of magnitude more expensive to correct.
Studies have shown that a defect costs up to 100 times more to fix during the maintenance phase than if it were identified and resolved during the requirements phase. A well-defined Software Requirement Specification (SRS) acts as the foundational contract that aligns all subsequent engineering efforts.
How Do Agile Methodologies Fit into the SDLC Stages?
Agile methodologies like Scrum or Kanban do not replace the SDLC stages; they iterate through them rapidly.
Instead of executing the SDLC as a single, long-duration sequence for the entire project (the Waterfall model), Agile applies all the stages within short, time-boxed iterations called sprints (typically 1-4 weeks).
Each sprint is a self-contained mini-project. The team plans a small batch of features from the backlog, designs the architecture for them, develops the code, performs comprehensive testing, and produces a potentially shippable increment of software. This means the team cycles through all six SDLC stages in every sprint. This iterative approach allows for continuous feedback, adaptability, and incremental value delivery.
What Are Some Common Pitfalls to Avoid in the SDLC?
From an engineering standpoint, several recurring anti-patterns can derail a project. Proactively identifying and mitigating them is key.
Here are the most critical technical pitfalls:
- Poorly Defined Requirements: Ambiguous or non-verifiable requirements (e.g., "the system should be fast") are the primary cause of project failure. Requirements must be specific, measurable, achievable, relevant, and time-bound (SMART).
- Scope Creep: Unmanaged changes to the SRS after the design phase has begun. A formal change control process is essential to evaluate the technical and resource impact of every proposed change.
- Inadequate Testing: Under-investing in automated testing leads to a high change failure rate. A low unit test coverage percentage is a major red flag, indicating a brittle codebase and a high risk of regression.
- Lack of Communication: Silos between engineering, product, and QA teams lead to incorrect assumptions and costly rework. Daily stand-ups, clear documentation in tools like Confluence, and transparent task tracking in systems like Jira are essential.
- Neglecting Maintenance Planning: Architecting a system without considering its long-term operational health. Failing to budget for refactoring, library updates, and infrastructure upgrades accumulates technical debt, eventually making the system unmaintainable.
Navigating these complexities is what we do best. At OpsMoon, our DevOps engineers help you weave best practices into every stage of your software development lifecycle. We can help you build everything from solid CI/CD pipelines to automated infrastructure that just works. Start with a free work planning session to map out your path forward. Learn more at OpsMoon.
Leave a Reply