Many teams don’t realize they have a process model until it starts failing them.
A release slips because requirements changed halfway through implementation. Operations blocks deployment because nobody agreed on rollback criteria. QA finds defects late, after infrastructure and application code have already drifted apart. Product asks for one more “small” change, and the team accepts it without understanding what it breaks downstream. From the outside, this looks like poor execution. In practice, it’s usually a process problem.
Software development process models matter because they decide how work moves, how feedback enters the system, when risk gets surfaced, and who owns quality at each stage. In a cloud-native environment, that decision reaches beyond engineering management. It affects CI/CD design, environment strategy, observability, change control, release approvals, and how quickly a team can recover when production goes sideways.
The mistake I see most often is treating process models as theory from an old software engineering textbook. They aren’t. They are operating models. If you choose the wrong one, Kubernetes won’t save you, Terraform won’t save you, and no amount of sprint ceremonies will fix the mismatch.
From Code Chaos to Predictable Delivery
A familiar pattern shows up when a company grows from one product team to several. Early on, the team ships by instinct. Senior engineers keep architecture in their heads, everyone talks constantly, and deployment is a small event because the surface area is limited.
Then scale arrives.
Now there are multiple services, shared infrastructure, security reviews, compliance demands, and different stakeholders pulling in different directions. The old “just code it” habit stops working. Developers optimize for feature output, operations optimize for stability, and product optimizes for speed. None of those goals are wrong, but without a shared process model, they collide.
A software development process model gives the organization a few things ad-hoc execution never does:
- A defined flow of work: Teams know whether work moves sequentially, iteratively, or through continuous pull.
- Explicit feedback timing: Everyone knows when requirements, testing, and stakeholder review happen.
- Clear control points: Architects, developers, QA, SREs, and product managers understand where they enter and what they own.
- A common language for trade-offs: The team can discuss scope, risk, lead time, and quality without arguing from personal preference.
Unstructured teams don’t move faster. They just postpone coordination until the most expensive moment.
That’s the practical reason software development process models still matter. They aren’t there to slow teams down. They exist to prevent hidden work, late surprises, and brittle releases.
The right model won’t eliminate tension. It will make the tension visible early enough to manage. That’s what predictable delivery is. Not perfect forecasting, but fewer surprises and faster correction when reality changes.
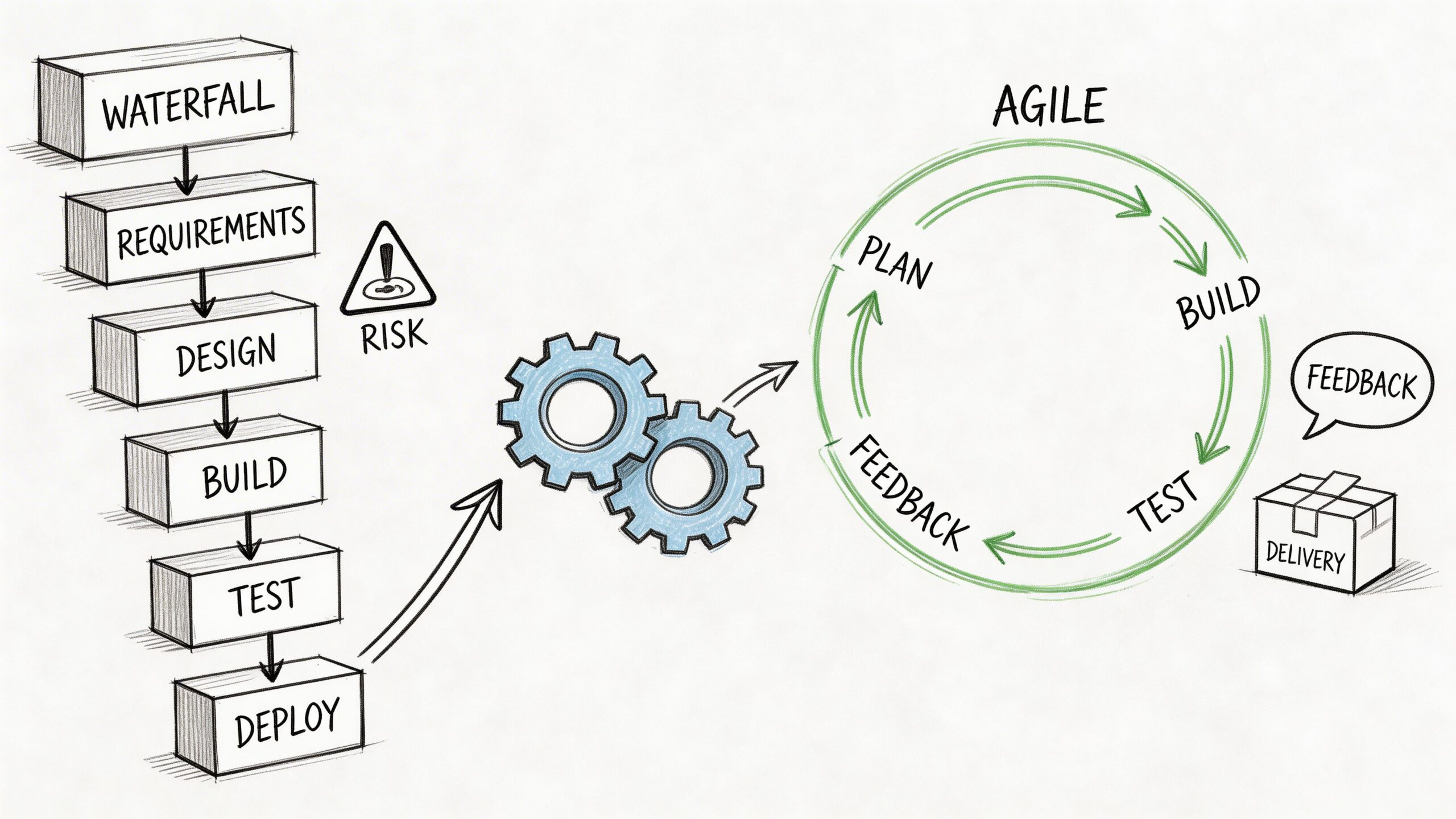
Understanding Classic Models Waterfall and V-Model
A team signs a fixed-scope contract to build a claims-processing system for an insurer. Security sign-off is required before deployment. Test evidence has to map back to approved requirements. Release windows happen monthly, not daily. In that situation, a linear model is often the right operational choice.
Waterfall and the V-Model still solve real delivery problems. They create control points, make approval paths explicit, and support traceability in ways many fast-moving product teams do not need. The mistake is using them because they feel orderly, rather than because the work fits their assumptions.

Waterfall works when discovery is low
Waterfall organizes delivery as a sequence of defined phases:
- Requirements
- Design
- Implementation
- Verification
- Maintenance
That structure is useful when the organization can lock scope early, hold interfaces steady, and accept a slower feedback cycle. Government programs, procurement-driven enterprise work, and internal systems with strict approval chains still use it for that reason.
The trade-off is simple. Waterfall performs well when uncertainty is low. It performs poorly when teams need to learn from integration, production behavior, or user feedback.
Cloud-native delivery makes that trade-off sharper. A migration to Kubernetes may start with a clean plan, but teams usually uncover details late: service-to-service authentication, ingress behavior, secrets rotation, autoscaling thresholds, infrastructure drift, cost limits, and rollback design. If those questions are deferred until implementation or verification, rework gets expensive fast.
That is why Waterfall tends to fit bounded efforts better than product evolution.
Where Waterfall still fits
Use Waterfall when these conditions are true:
- Requirements are stable: Scope can be defined early and changes are rare.
- Formal approvals are part of the work: Sign-offs, document reviews, and audit records are required outputs.
- Integration contracts are predictable: External systems, vendors, or regulated interfaces are unlikely to shift.
- Delivery cadence is secondary: Conformance matters more than weekly release speed.
Waterfall is a weak fit for products that depend on experimentation, frequent customer feedback, or architecture decisions that only become clear after running in production. Teams doing regular feature iteration usually need a shorter feedback loop, which is why many organizations pair linear governance for specific milestones with iterative planning practices such as agile sprint planning.
The V-Model turns testing into a design activity
The V-Model keeps the linear structure but tightens the relationship between building and testing. Each development stage has a matching validation activity. Requirements map to acceptance testing. System design maps to system testing. Architecture and component design map to integration and unit testing.
That discipline matters in environments where proving correctness matters as much as building the feature.
A real V-Model implementation usually includes:
- A Software Requirements Specification
- A traceability matrix
- Test plans tied to requirement levels
- Formal review and approval records
This model is common in aerospace, automotive, medical software, and similar domains where verification and validation must stand up to external review. The value is not speed. The value is a defensible chain from approved requirement to test evidence.
Old Dominion University notes that earlier defect detection lowers total cost, while defects found after implementation cost far more to correct. Their overview of verification and validation in structured models is available through Old Dominion University course material. The cost of that discipline is longer lead time, heavier documentation, and less room to absorb changing requirements once execution starts.
Practical rule: If the team cannot trace each requirement to a test case and test result, it is not really using the V-Model.
What linear models look like in a DevOps environment
Classic models do not require old tooling. A team can run a Waterfall or V-Model project with Git-based change control, CI pipelines, infrastructure as code, artifact signing, and automated test evidence collection.
That is where many teams get this wrong. They assume CI/CD automatically means Agile. It does not. CI/CD is delivery machinery. It can support a linear process just as easily by enforcing gated promotion, approval workflows, immutable artifacts, and environment controls across dev, test, and production.
For example, a regulated platform team might define requirements and architecture upfront, provision environments with Terraform, validate builds through automated pipeline stages, and deploy to Kubernetes only after formal sign-off. The process model is still linear. The implementation is modern.
What leaders usually misjudge
The main risk in Waterfall and V-Model is not bureaucracy by itself. A greater risk is treating uncertain work as if it were already understood.
Leaders often choose linear models because they want predictability. Predictability only shows up when scope, interfaces, and acceptance criteria are stable enough to support it. If stakeholders keep changing priorities, or if the architecture depends on what the team learns from running software in real conditions, a linear model turns uncertainty into delay, change requests, and avoidable rework.
Used carefully, these models are still valuable. In a cloud-native organization, they usually fit best around bounded systems, compliance-heavy delivery paths, platform controls, and contract-defined integrations, rather than the full lifecycle of a product that is still evolving.
Embracing Change with Agile, Spiral, and Iterative Models
The industry didn’t move toward iterative models because teams suddenly preferred ceremonies. It moved because linear planning broke down under changing requirements, shorter product cycles, and infrastructure that no longer stayed static for years.
Agile, iterative development, and Spiral all attack the same core problem from different angles. They shorten the distance between decision and feedback. The differences are in what they optimize for. Agile prioritizes adaptability and collaboration. Iterative models prioritize incremental learning. Spiral prioritizes risk reduction in uncertain environments.

Agile changed the feedback loop
The shift from Waterfall to Agile accelerated in the 1990s and 2000s. Agile now powers 70-80% of projects, and it’s often cited as 28% more successful and 37% faster than Waterfall, with development cycles of 2-4 weeks instead of multiple years, based on this overview of software process evolution.
That shift matters because it changed the control mechanism of delivery.
Instead of betting on a complete requirements package, Agile teams work in small increments. They validate assumptions faster, release partial value sooner, and change direction without rewriting the whole plan. In practice, the strongest Agile teams aren’t just “flexible.” They are disciplined about feedback frequency.
Scrum and Kanban handle that differently.
Scrum is best when priority needs regular resetting
Scrum works well when the team needs a time-boxed planning and review rhythm. It creates a clear cadence for backlog refinement, sprint commitment, review, and retrospective. If a team struggles with thrash from too many incoming requests, Scrum gives it a container.
The hard part is planning well enough to protect focus without pretending uncertainty doesn’t exist. Teams that want a practical refresher on backlog shaping, sprint scope, and meeting flow can use this guide to agile sprint planning as a useful reference.
Scrum usually fails for one of three reasons:
- Sprint scope is unstable: Leaders keep injecting work mid-sprint.
- Stories are not ready: Teams enter planning without technical clarity.
- Reviews don’t change decisions: Stakeholder feedback is ceremonial, not operational.
Kanban is better for flow-driven work
Kanban fits environments where work arrives continuously and queue management matters more than time-boxing. Platform teams, SRE functions, production engineering, and support-heavy product groups often do better with Kanban than Scrum.
The advantage is visibility. Work-in-progress limits expose bottlenecks fast. The board becomes an operational signal, not just a planning tool.
Kanban is often a better match for teams managing:
- Incident follow-up
- Platform enablement
- Shared service requests
- Ongoing reliability improvements
- Continuous release pipelines
The risk is softness around prioritization. Without explicit service classes, pull policies, and clear ownership, a Kanban board turns into a queue of unrelated tasks with no flow discipline.
Spiral is for uncertainty with consequences
Where Agile optimizes for adaptability, Spiral optimizes for controlled learning under risk.
The Spiral Model runs through repeating cycles of planning, risk analysis, engineering, and evaluation. In high-uncertainty domains, thorough risk mitigation in each cycle can reduce project overruns by 25-40%, but it can also require 1.5-2x longer timelines than simpler models, according to this review of software development models.
That trade-off is worth it when technical uncertainty could sink the whole effort.
Think about a large migration from a monolith to microservices on Kubernetes. A key risk may not be feature implementation. It may be data consistency, deployment orchestration, rollback behavior, cross-service latency, or operator burden. Spiral handles this better because it forces the team to identify and prototype the dangerous unknowns before pretending they are solved.
For high-risk programs, the first deliverable shouldn’t be more code. It should be less uncertainty.
Where Spiral fits in modern engineering
Spiral is strong when you need to validate architecture, operational risk, or feasibility before committing broadly.
Examples include:
- Platform re-architecture: Moving to Kubernetes, service meshes, or event-driven systems
- AI-heavy product work: Where model behavior, governance, and evaluation need repeated review
- Regulated cloud migrations: Where design choices affect compliance controls
- Complex integration programs: Where external systems create hidden coupling
Spiral is weak when a team lacks the skill to do serious risk analysis. Without that discipline, teams just relabel ordinary iteration as “Spiral” and get the overhead without the benefit.
Iterative beats certainty theater
The broader lesson across Agile, iterative, and Spiral models is simple. They don’t remove planning. They replace one-time certainty with repeated validation.
That is the right move for most cloud-native products. Requirements change. Infrastructure changes. Security constraints evolve. Customer feedback arrives after release, not before it. A process model that expects stability across the whole delivery path usually fights the environment instead of working with it.
The practical question isn’t whether your team should iterate. Many already do. The question is whether iteration is intentional, risk-aware, and connected to how you build, test, release, and observe software in production.
Comparing Process Models A Head-to-Head Analysis
Leaders don’t need another abstract debate about methodology. They need a way to compare trade-offs quickly and choose based on constraints.

What the models optimize for
Here’s the short version.
| Model | Best fit | Main strength | Main weakness |
|---|---|---|---|
| Waterfall | Stable, well-defined projects | Clear sequencing and documentation | Poor response to change |
| Agile Scrum | Product development with evolving scope | Fast feedback and prioritization cadence | Depends on strong stakeholder participation |
| Kanban | Continuous delivery and service-oriented teams | Flow visibility and flexibility | Can become reactive without discipline |
| Spiral | Large, complex, high-risk programs | Explicit risk management | Slower and heavier to run |
The useful comparison isn’t “old versus modern.” It’s whether the model matches the shape of work.
A fixed-scope internal compliance tool may suffer under Scrum because constant reprioritization adds noise. A customer-facing SaaS product may suffer under Waterfall because delayed feedback hides product mistakes until they’re expensive. A platform team handling interrupts and enablement requests may find sprint boundaries artificial. A risky architecture transformation may need Spiral-style prototyping before any team commits to full execution.
Key Decision Factors
Use these criteria when comparing software development process models:
- Flexibility to change: How often do requirements move after implementation begins?
- Risk concentration: Are the biggest risks commercial, technical, operational, or regulatory?
- Customer availability: Can stakeholders review often, or only at major milestones?
- Delivery cadence: Do you need time-boxed releases, continuous flow, or staged approvals?
- Documentation burden: Is documentation a support tool, or a required control artifact?
If you’re measuring engineering outcomes formally, this matters even more. Process model choice affects throughput, rework, defect escape, deployment frequency, and recovery behavior. Teams that want a more grounded way to connect process decisions to measurable output should look at https://opsmoon.com/blog/engineering-productivity-measurement.
Good process selection starts with the bottleneck. If your problem is risk, choose for risk. If your problem is flow, choose for flow. If your problem is auditability, choose for traceability.
One caution on Agile adoption
Agile is popular for good reason, but popularity isn’t proof of fit. As noted earlier, Agile is widely used, with commonly cited gains in project success and delivery speed compared to Waterfall. Those gains are real only when the organization also changes governance, planning habits, and release operations. If leadership keeps fixed-scope command-and-control behavior while asking teams to “be Agile,” they usually get process theater.
The model should change the operating system of delivery, not just the meeting calendar.
Your Decision Framework for Selecting a Process Model
Many teams choose a model for the wrong reason. They copy what peers use, inherit what a PMO prefers, or default to Agile because rejecting it sounds regressive.
A better approach is to choose based on constraints you can name.
Start with the work, not the methodology
Ask these project questions first.
Are requirements stable or emergent?
If scope is contractually fixed and unlikely to move, a linear model may be appropriate. If the team expects discovery during delivery, choose an iterative model.Where is the highest risk?
If the biggest risk is unclear architecture, integration complexity, or operational behavior, use a model that surfaces technical uncertainty early. Spiral and iterative approaches are stronger here.What is the cost of getting it wrong late?
If failure in production has severe regulatory, safety, or contractual consequences, stronger verification and traceability may matter more than raw speed.
Then assess the team operating environment
A model only works if the team can execute it.
Team maturity matters more than stated preference
A highly autonomous engineering group can run Scrum lightly, maintain service ownership, and keep delivery disciplined. A fragmented team with weak technical leads often needs more explicit controls, clearer interfaces, and stronger review gates.
Look at these signals:
- Planning quality: Can the team break work into slices with real acceptance criteria?
- Testing discipline: Are unit, integration, and environment-level tests reliable?
- Operational ownership: Do developers understand deployment and incident impact?
- Architecture clarity: Can the team define boundaries and contracts early enough?
If the answer is “not yet,” don’t pick the most flexible model just because it sounds modern. Flexibility without discipline produces churn.
The wrong model for an immature team is usually the one that assumes judgment they haven’t built yet.
Customer and stakeholder behavior should shape the choice
Many CTOs underestimate reality at this point.
If business stakeholders are available weekly, can review working software, and will make trade-offs in real time, iterative models are strong. If customer review only happens at formal milestones, forcing Scrum may create fake agility. The team will run sprints internally, but decision-making will still be stage-gated.
Use this quick guide:
| If this is true | Favor this kind of model |
|---|---|
| Scope is stable, approvals are formal | Waterfall or V-Model |
| Product direction changes based on market feedback | Scrum or iterative Agile |
| Work arrives continuously from many channels | Kanban |
| Unknowns could derail architecture or delivery | Spiral or a Spiral-Agile hybrid |
Don’t choose one model for the whole company
That’s another common leadership mistake.
Different work types need different process shapes. A company might run:
- Scrum for product feature teams
- Kanban for platform engineering and SRE work
- V-Model controls for compliance-sensitive release paths
- Spiral discovery loops for major architecture changes
That isn’t inconsistency. It’s operational fit.
The key is to standardize interfaces, not force identical execution. Define how teams document decisions, hand off release artifacts, manage environments, and report risk. Let the work model vary where it needs to.
A practical selection checklist
Use this before you commit:
- Scope clarity: Are requirements fixed enough to freeze early?
- Risk profile: Do unknowns sit in product, tech, operations, or compliance?
- Feedback access: Will users or stakeholders review frequently?
- Release expectations: Are you shipping on cadence, continuously, or by approval gate?
- Documentation needs: Is documentation a convenience or a required control?
- Tooling readiness: Can your current CI/CD, IaC, and test stack support the model?
- Leadership behavior: Will executives respect the operating rules of the model?
If leadership won’t tolerate sprint boundaries, Scrum will break. If the organization won’t maintain traceability, V-Model will degrade. If nobody can do meaningful risk analysis, Spiral will become expensive iteration with nicer diagrams.
The best choice is the one your organization can execute this.
Bridging Models and Modern DevOps Toolchains
A team can agree on Scrum, Kanban, or the V-Model in a planning meeting and still fail in production three weeks later. The model only becomes real when it changes how code is built, tested, deployed, observed, and recovered.
That is the gap many SDPM discussions miss. They explain phases and ceremonies, but stop before branch policy, pipeline gates, infrastructure definitions, deployment controls, and incident feedback. In cloud-native systems, those details decide whether the model produces predictable delivery or just nicer planning language.

Classic models still matter. They just need to be implemented through modern tooling. CI/CD, Kubernetes, Infrastructure as Code, and observability do not replace process models. They enforce them, or expose that the team never translated the model into working controls.
CI/CD should mirror decision flow
The pipeline should reflect how the team makes delivery decisions.
A Scrum team usually needs a deployable increment at the end of each sprint, so the pipeline should keep trunk quality high every day. That typically means short-lived branches, automated tests on each merge, feature flags for incomplete work, review environments for demo and validation, and promotion rules tied to sprint completion criteria.
A Kanban team has a different pressure point. Queue time matters more than sprint boundaries, so the pipeline should optimize for flow. Fast validation, small releases, progressive delivery, visible work-in-progress, and automatic rollback reduce waiting and make blockers obvious. Teams trying to reduce those handoff delays usually benefit from stronger DevOps automation, especially where manual approvals and environment setup create hidden queues.
The same principle applies to regulated work. If a team claims to use V-Model controls, the pipeline needs traceable requirements, linked test evidence, approval records, and release artifacts that can survive an audit. If those checks live in email and spreadsheets, the process model is theater.
Infrastructure as Code changes the operating cost of every model
IaC tools such as Terraform and Pulumi do more than provision cloud resources. They make environments versioned, reviewable, and repeatable, which changes how teams execute a process model.
For Waterfall and V-Model paths, that means environment definitions can move into source control alongside application changes. Reviews improve because operations changes stop being invisible. Rollbacks become more realistic because teams can recreate known states instead of relying on tribal knowledge.
For iterative and Spiral work, IaC has a different payoff. Teams can create short-lived environments for experiments, security testing, or architecture validation without turning each request into a ticket queue. In Kubernetes-based systems, that often means spinning up an isolated namespace or cluster, testing service interactions, inspecting telemetry, and tearing it down the same day.
That speed changes behavior.
Spiral loops work better when each risk has a runnable environment
Teams often describe Spiral as risk-driven, but the useful version is concrete. If the risk is cross-region failover, data consistency under load, or ingress behavior during traffic spikes, build a loop that provisions the environment, runs the smallest meaningful implementation, instruments it, and captures the result. That turns architecture risk into something engineers can test instead of debate.
Observability is part of the model, not a post-launch add-on
Iterative delivery depends on feedback after deployment. Without that, teams are still working in long cycles. They just release more often.
Prometheus, Grafana, OpenTelemetry, Loki, and commercial platforms such as Datadog give teams the signals needed to judge whether a change helped or harmed the system. The useful metrics are usually straightforward:
- User-facing health: latency, errors, throughput, saturation
- Deployment outcomes: failed changes, rollback rate, recovery time
- Service reliability: SLO burn, dependency failures, alert noise
- Delivery performance: build duration, queue time, environment creation lag
A solid implementation reference for connecting Agile delivery choices to CI/CD mechanics, cloud infrastructure, and release controls is this technical blueprint for agile and continuous delivery.
After the tooling pattern is clear, this walkthrough adds helpful visual context:
Hybrid models succeed when the toolchain makes the boundaries explicit
Production organizations rarely run one pure model across all work. The useful question is whether the toolchain makes each mode of work clear and enforceable.
A common setup is straightforward:
- Scrum for product delivery, with trunk-based development and sprint-level release goals
- Kanban for platform engineering and operational work, with small batches and fast flow metrics
- V-Model controls for release paths that need traceability, evidence, and formal approval
- Spiral experiments for architectural uncertainty, backed by disposable environments and telemetry
I have seen this work well when teams standardize the mechanics around it. Source control policy, deployment rules, artifact handling, environment definitions, and observability need to be explicit. Otherwise the organization says it runs a hybrid process, but engineers are still improvising the hard parts.
If a company needs help translating model choices into delivery workflows, OpsMoon is one option for DevOps planning, engineer matching, and support across CI/CD, Kubernetes, Terraform, and observability. The value is not the vendor label. The value is making the operating model executable through the toolchain.
Beyond Models A Culture of Continuous Evolution
The most effective teams don’t treat software development process models as identities. They treat them as operating assumptions that can be tested, improved, and replaced.
That mindset matters because the environment keeps moving. Product demands shift. Architecture changes. Compliance requirements tighten. Toolchains mature. Team composition evolves. A model that fit a 15-person engineering org can become a bottleneck for a multi-team platform organization.
The same thing is happening now with AI-assisted development. The verified material tied to the 2026 State of DevOps discussion notes that GitHub Copilot is associated with 55% productivity gains, but 61% of SREs report gaps in AI governance within existing risk management processes. That’s the next process challenge. AI can accelerate coding and testing, but it also creates new review, validation, and accountability demands that classic models don’t address well.
Mature engineering organizations don’t ask, “Are we Agile or Waterfall?” They ask, “What feedback, controls, and risks does our current system handle badly?”
That’s the better question because it leads to adaptation.
If your team can’t absorb production feedback quickly, improve observability and release practice. If requirements are unstable but governance is rigid, redesign approvals. If architecture risk keeps showing up late, add Spiral-style discovery loops before full implementation. If documentation is too weak for audit or maintenance, strengthen artifacts without dragging the whole org back into phase-gated delivery.
Process maturity isn’t about adopting the trendiest model. It’s about building a system that learns.
For teams trying to improve that system deliberately, https://opsmoon.com/blog/software-improvement-process is a useful next read.
If your delivery model no longer matches how your teams build and run software, OpsMoon can help you assess the gap, map the right process to your CI/CD and cloud tooling, and turn that model into a workable engineering system.
Leave a Reply