Integrating Agile and DevOps isn't a philosophical debate. It's about using Agile as the high-level specification for development velocity and DevOps as the automated, high-performance infrastructure that compiles, tests, and deploys code with precision and safety.
Imagine Agile sprints as the design phase for a high-performance engine, defining user stories as specific components. DevOps, then, is the automated assembly line and testing rig—from CI pipelines that validate each part to IaC that provisions the racetrack—ensuring the engine runs at peak performance without catastrophic failure.
The Inevitable Fusion of Agile and DevOps
In software engineering, velocity and stability are often treated as conflicting forces. Development teams, operating under Agile frameworks, are incentivized to iterate rapidly and ship new features. Conversely, Operations teams have traditionally been gatekeepers of stability, mandating slower, risk-averse deployment cadences to prevent production incidents.
This inherent tension is precisely why the synthesis of Agile and DevOps is a technical and cultural necessity.
Agile answers the "why" and "what"—it provides frameworks like Scrum or Kanban to prioritize work based on business value, respond to customer feedback, and adapt to changing requirements in short, time-boxed cycles. However, this potential energy remains untapped if the deployment process is a bottleneck. An Agile team might complete feature development in a two-week sprint, but if the subsequent manual deployment process—involving ticketing systems, manual configuration, and multi-team handoffs—takes another week, the Agile momentum is nullified.
Closing the Loop Between Development and Operations
This is where DevOps provides the "how." It bridges the development and operations chasm by automating the entire software delivery life cycle (SDLC). To fully grasp this, a foundational understanding of the DevOps methodology is crucial.
DevOps practices like Continuous Integration/Continuous Delivery (CI/CD) and Infrastructure as Code (IaC) are the technical implementations that make Agile principles executable. They create the automated pathways for the small, incremental code changes produced in an Agile sprint to flow from a developer's local environment through a series of quality gates and into production with minimal human intervention.
This synergy creates a powerful, self-reinforcing feedback loop:
- Agile defines the work in small, testable batches (user stories).
- DevOps automates the build, test, and deployment pipelines, making releases of these small batches low-risk and frequent.
- Faster feedback from production monitoring and user analytics flows back to inform the backlog for the next Agile sprint.
This isn't a niche trend; it's a core competency of high-performing engineering organizations. The global Agile and DevOps services market is projected to reach $11,581.5 million by 2025, underscoring its role as a fundamental operational model.
Mapping Agile Principles to Concrete DevOps Practices
It’s one thing to discuss Agile philosophy, but it's another to implement it in your toolchain. Principles like "customer collaboration" and "responding to change" are abstract until they are encoded into the YAML configurations and Git workflows your teams use daily. This is where the synthesis of Agile and DevOps becomes tangible—turning principles into pipelines.
The objective is to draw a direct line from an Agile principle to a specific, technical DevOps implementation. This serves as a blueprint for architecting a high-performance software delivery system. Of course, this requires a solid foundation in both domains; reviewing established Agile methodology best practices provides the necessary framework.
Agile is the strategic philosophy guiding what and why you build; DevOps provides the technical machinery to build it rapidly and reliably. When integrated, they achieve true synergy.
As the diagram illustrates, optimal velocity and stability are achieved at the intersection of Agile’s iterative development and DevOps’ automated infrastructure and delivery practices.
Let's dissect this translation with concrete technical examples.
From Responding to Change to Infrastructure as Code
A core tenet of the Agile Manifesto is "responding to change over following a plan." In a traditional IT operations model, this is nearly impossible. A simple change, like provisioning a new database for a feature, could involve weeks of navigating ticketing systems, manual server configuration, and approval chains, completely stalling Agile momentum.
The DevOps practice that technically enables this principle is Infrastructure as Code (IaC).
Using declarative tools like Terraform or Pulumi, or configuration management tools like Ansible, your entire infrastructure stack—VPCs, subnets, EC2 instances, Kubernetes clusters—is defined in version-controlled configuration files. Need a new staging environment for a feature branch? Don't file a ticket. Branch your IaC repository, modify a .tf file, and run terraform apply.
This makes infrastructure changes:
- Rapid: Provision or destroy complex environments in minutes via CLI commands.
- Repeatable: Eliminate configuration drift and "it works on my machine" issues by ensuring identical environments from dev to production.
- Testable: Apply static analysis tools like
tflintorcheckovto your IaC in a CI pipeline to catch misconfigurations before they reach production.
IaC is the ultimate technical expression of agility. It treats your infrastructure with the same rigor as your application code—enabling versioning, peer review, and automated testing—allowing your organization to adapt at the speed of software.
From Customer Collaboration to Automated Feedback Loops
Another key Agile principle is "customer collaboration over contract negotiation." The goal is to get functional software into users' hands, gather empirical feedback, and iterate. DevOps provides the technical engine to automate this feedback loop.
This is achieved with automated observability and feedback mechanisms built directly into the CI/CD pipeline and production environment.
Here’s a technical breakdown:
- A developer merges a feature branch into
main. - The CI/CD pipeline triggers, running unit tests (
pytest,jest), integration tests, and static analysis security testing (SAST) tools like SonarQube. - On successful build, the code is deployed to a staging environment where automated end-to-end tests using frameworks like Cypress or Selenium are executed.
- Post-deployment, monitoring tools (e.g., Prometheus for metrics, Loki for logs, Grafana for visualization) immediately begin collecting performance data. An alert is configured in Alertmanager to notify the team via Slack if the 95th percentile latency for a key endpoint exceeds a defined service-level objective (SLO).
This automated process provides immediate, quantitative feedback, closing the loop between a code change and its impact. The system itself becomes a collaborator. For a deeper look, explore our guide on Agile and continuous delivery.
To make this connection explicit, here is a direct mapping.
Translating Agile Principles into Technical DevOps Actions
This table provides a direct mapping of core Agile principles to their corresponding technical DevOps implementations, showing how philosophy becomes action.
| Agile Principle | Corresponding DevOps Practice | Technical Example |
|---|---|---|
| Individuals and interactions over processes and tools | Collaborative Platforms & ChatOps | Integrating a Git repository with a Slack channel to post automated notifications for pull requests, build failures, and deployment statuses, enabling discussions directly in the channel. |
| Working software over comprehensive documentation | Continuous Integration/Continuous Delivery (CI/CD) | A GitHub Actions workflow defined in a .github/workflows/main.yml file that triggers on every push to the main branch to automatically build a Docker image, run tests, and push to a container registry. |
| Customer collaboration over contract negotiation | Automated Observability & Feedback | Instrumenting application code with OpenTelemetry to send traces to Jaeger, allowing developers to analyze performance data and user journeys for newly released features. |
| Responding to change over following a plan | Infrastructure as Code (IaC) | Using a Terraform module to define a reusable web application stack (ALB, ECS Cluster, RDS), allowing teams to spin up new, production-like environments for feature testing by changing a few variables. |
This mapping makes it clear: Agile and DevOps are not separate methodologies. They are two interdependent components of a single system designed to deliver high-quality software efficiently.
Architecting High-Performance Team Structures
An optimal technical architecture is useless if organizational friction impedes flow. When implementing agile in devops, team topology is as critical as system architecture. The primary objective is to structure teams for end-to-end ownership with minimal handoffs, reducing cognitive load and accelerating delivery.
This is where the "You Build It, You Run It" (YBIYRI) philosophy becomes an actionable organizational principle. A single team is given full ownership of a microservice or product slice—from initial code commit and pipeline configuration to on-call support and production monitoring.
When the same engineer who wrote the feature is woken up by a PagerDuty alert at 3 AM, they are intrinsically motivated to write more reliable, observable, and resilient code. This model directly combats the anti-pattern of siloed "Dev" and "Ops" teams, which historically leads to ticket-based workflows, blame-shifting, and slow release cycles.
Blueprints for Different Organizational Scales
A single team topology does not fit all organizations. The optimal structure depends on scale, product complexity, and engineering maturity.
- For Startups: A single, cross-functional "product" team is standard. This small group handles all aspects of the SDLC, maximizing communication bandwidth and decision velocity. Every member has full context.
- For Mid-Sized Companies: As scale increases, a Platform Engineering model becomes highly effective. This central team builds and maintains a paved road of self-service tools and infrastructure—e.g., a standardized CI/CD pipeline template, a service catalog in Backstage, and pre-configured Terraform modules. This empowers product teams to deploy and manage their own services without requiring deep infrastructure expertise.
- For Enterprises: At large scale, embedding Site Reliability Engineers (SREs) into product teams is a powerful strategy. These SREs act as consultants and contributors, focusing on reliability, performance, and scalability. They help define Service Level Objectives (SLOs), architect for resilience, and build observability into the product from day one, rather than treating it as an afterthought.
The unifying principle across these models is the distribution of autonomy and ownership to the edge—the teams building the product. By minimizing cross-team dependencies, you create a system that can scale delivery capabilities linearly with the number of teams.
The data supports these structures. Agile methodologies, which underpin these team designs, yield significant performance gains. Studies show 39% of Agile teams report the highest average performance rates, with an overall 75.4% project success rate. You can explore detailed Agile statistics on businessmap.io for more data.
Choosing the right team structure is a critical step. For a more detailed analysis of these topologies, review our guide on building effective DevOps team structures.
Implementing Key Technical Patterns for Success
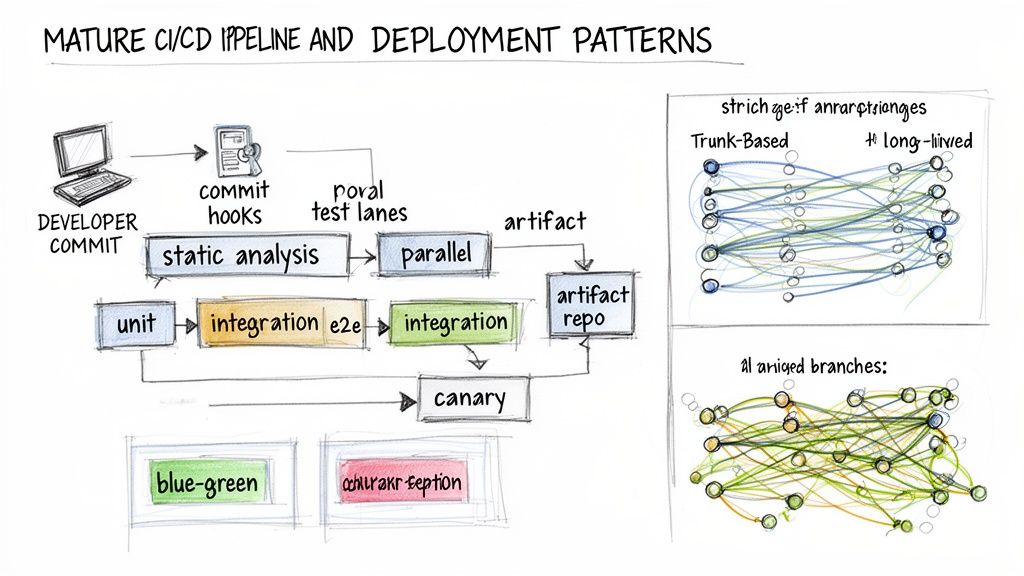
With the right team structures in place, the focus shifts to the technical patterns that enable agile in devops. These are the engineering practices that convert theory into throughput, allowing teams to ship high-quality code frequently and with high confidence.
The core of this is a mature Continuous Integration and Continuous Delivery (CI/CD) pipeline. A well-architected pipeline is not just an automation script; it is an automated quality assurance and delivery system that systematically de-risks the path from commit to production.
Building a Mature CI/CD Pipeline
A mature CI/CD pipeline functions as a multi-stage validation process. Each stage adds value and confirms quality before promoting the artifact to the next, catching defects early when the cost of remediation is lowest.
A mature pipeline typically includes these critical stages:
- Pre-Commit Hooks: The first line of defense, running locally on a developer's machine before code is committed. Tools like
pre-commitcan be configured to run linters (e.g.,flake8for Python,eslintfor JavaScript) and secret scanners (trufflehog), preventing trivial errors and credential leaks from entering the codebase. - Automated Testing Suite: Upon
git push, the pipeline executes a hierarchy of tests. This starts with fast unit tests that run in parallel, followed by integration tests that may require spinning up dependent services (e.g., via Docker Compose), and finally end-to-end (E2E) tests that validate critical user flows against a deployed environment. - Secure Artifact Management: After passing all tests, the application is packaged as an immutable artifact, such as a Docker container. This artifact is then scanned for vulnerabilities using tools like Trivy or Grype and, if clean, pushed to a secure artifact registry (e.g., AWS ECR, Artifactory) with a unique tag corresponding to the Git commit hash. This ensures traceability and that the tested artifact is the exact artifact that gets deployed.
De-Risking Releases with Advanced Deployment Strategies
Pushing a validated artifact through a pipeline is only half the battle. Deploying it to production without causing an outage is the ultimate goal. Modern deployment strategies leverage automation to transform releases from high-risk "big bang" events into controlled, data-driven processes.
These patterns are designed to minimize the blast radius of a failed deployment. The core principle is to expose new code to a small subset of traffic, validate its performance and stability against production load, and then incrementally roll it out.
Here are three highly effective strategies:
- Blue-Green Deployments: Maintain two identical production environments ("blue" and "green"). Deploy the new version to the inactive environment, run smoke tests against it, and then switch the load balancer or DNS to route all traffic to the new environment. If issues arise, rollback is instantaneous by simply switching traffic back to the old environment.
- Canary Releases: Direct a small percentage of live traffic (e.g., 5%) to the new version while the majority remains on the old version. Use monitoring and feature flags to compare key metrics (error rate, latency) between the two cohorts. If the canary release performs within SLOs, gradually increase its traffic share to 100%.
- Feature Flagging: This decouples deployment from release. New code can be deployed to production behind a "flag" that is toggled off by default. This allows you to turn the feature on for specific user segments (internal teams, beta testers) to gather feedback before a full rollout. It also provides a kill switch to instantly disable a problematic feature without a full redeployment.
Embracing Trunk-Based Development
Finally, these patterns are most effective when paired with the right branching strategy. For fast-moving teams practicing agile in devops, Trunk-Based Development is the industry standard.
In this model, developers commit small, frequent changes directly to a single main branch (the "trunk" or main). Long-lived feature branches are eliminated, which eradicates the painful merge conflicts associated with them. This strategy forces continuous integration, ensuring the trunk is always in a releasable state and enabling the rapid feedback loops essential for Agile teams.
Measuring Performance with DORA Metrics
To optimize an agile in DevOps system, you must move beyond subjective assessments and implement quantitative measurement. The principle "if you can't measure it, you can't improve it" is paramount. DORA (DevOps Research and Assessment) metrics provide a standardized, data-driven framework for evaluating engineering performance.
These four key metrics offer an objective view of both the velocity and stability of your software delivery lifecycle, answering two fundamental questions: "How quickly can we deliver value?" and "How resilient are our systems?"
This is a proven methodology. With 80% of organizations globally now adopting DevOps, the benefits are clear. A remarkable 99% of organizations report positive impacts, with 61% citing higher quality deliverables and 49% of teams reducing their time-to-market.
The Four Key DORA Metrics
DORA focuses on four metrics that are proven to correlate with high-performing teams, avoiding vanity metrics.
- Deployment Frequency: A velocity metric that measures how often code is successfully deployed to production. This can be calculated by querying your CI/CD tool's API (e.g., Jenkins or GitHub Actions) for the count of successful production deployment jobs over time.
- Lead Time for Changes: A velocity metric tracking the time from the first commit for a change to its successful deployment in production. This is calculated by subtracting the timestamp of the first commit in a pull request from the timestamp of the production deployment that included it.
- Mean Time to Recovery (MTTR): A stability metric measuring the median time to restore service after a production failure. This is tracked by measuring the duration from the time an incident is declared in a tool like PagerDuty to the time the fix is deployed and the incident is resolved.
- Change Failure Rate: A stability metric calculating the percentage of production deployments that result in a degraded service or require remediation (e.g., a rollback, hotfix). This is calculated as:
(Number of deployments causing a failure / Total number of deployments) * 100.
These metrics are not merely KPIs; they are diagnostic indicators. A declining Deployment Frequency might signal a bottleneck in your test suite. A rising Change Failure Rate could indicate insufficient automated testing or a need for canary deployments.
Connecting DORA to Agile Metrics
The real power is realized when you correlate DORA metrics with Agile metrics like Cycle Time (the time from when work begins on an issue to when it is completed).
For example, your Jira data shows a decrease in Cycle Time. Is this a net positive? By cross-referencing with DORA metrics, you can verify if this also led to an increased Deployment Frequency and a stable Change Failure Rate. If not, you may have simply shifted a bottleneck downstream. This holistic view connects product development velocity with operational performance.
For a deeper technical exploration, see our guide on engineering productivity measurement. This combined visibility is critical for making informed, data-driven decisions to optimize your engineering system.
Common Pitfalls and How to Avoid Them
Implementing an agile and DevOps culture is a significant organizational change, and several common anti-patterns can derail the effort.
One of the most frequent is “Cargo Cult Agile.” This occurs when a team adopts the ceremonies of Agile—daily stand-ups, retrospectives, story points—without embracing the core principles of iterative development and empirical feedback. The process becomes a rigid ritual rather than a framework for adaptation, leading to frustration and minimal improvement.
Another critical error is forming a siloed "DevOps Team." This is a fundamental anti-pattern. The goal is to break down walls between development and operations, but creating a new team that becomes the sole gatekeeper for infrastructure and deployments simply rebrands the old problem. The "us vs. them" dynamic persists, and handoffs remain a source of friction.
Avoiding Silos and Tool Overload
To prevent a DevOps silo, adopt a platform engineering model. Instead of a team that does the operational work, build a team that enables developers to do it themselves. These platform engineers build and maintain the self-service tools, CI/CD templates, and infrastructure modules that product teams use to deploy and manage their own services. They act as educators and internal consultants, fostering a true "you build it, you run it" culture.
The objective isn't a 'DevOps engineer' who runs
kubectl apply. The objective is a product team that can confidently and safely deploy its own services using a robust, automated platform built by specialists.
Finally, avoid toolchain complexity. The market is flooded with powerful DevOps tools, and the temptation to adopt many is strong. This often results in a fragile, over-engineered pipeline that no single person fully understands.
Instead, build a minimum viable toolchain. Start with the essentials: version control, a CI runner, and an artifact registry. Only add a new tool to solve a specific, well-defined problem that can be measured. Applying an iterative, Agile mindset to your internal platform development ensures your tools serve you, not the other way around.
Got Questions About Agile and DevOps?
When integrating Agile and DevOps, several technical questions frequently arise. Here are direct answers for engineering teams.
What Is the Real Difference Between Agile and DevOps?
Think of it in terms of abstraction layers: Agile is the strategic framework for planning and managing work. It provides methodologies like Scrum to organize work into iterative cycles (sprints) focused on delivering business value and incorporating feedback. Agile defines the "what" and "why."
DevOps is the technical implementation that makes that framework executable at high velocity. It is the collection of practices (CI/CD, IaC, observability) and tools that automate the software delivery lifecycle. DevOps provides the "how."
You can practice Agile without mature DevOps, but your release cadence will be gated by manual processes. You can implement DevOps automation without Agile, but you might efficiently deliver the wrong product. The power of agile in devops comes from their synthesis.
How Can a Small Team Start Without a Dedicated Ops Engineer?
This is not just feasible; it's the ideal starting point for instilling a YBIYRI culture. The key is to leverage managed services and a minimal, effective toolchain.
A practical starter toolchain includes:
- Version Control: A Git provider like GitHub or GitLab. This is non-negotiable.
- CI/CD: Use the integrated CI/CD solution from your Git provider (e.g., GitHub Actions). Define a simple workflow in YAML to build, test, and deploy on every push to
main. - Cloud Platform: Rely heavily on serverless or managed services (e.g., AWS Lambda, Google Cloud Run, managed databases like RDS). This abstracts away the underlying infrastructure management, reducing operational overhead for developers.
The strategy is to automate one piece of the delivery process at a time. Start with automated testing, then automated builds, then deployments to a staging environment. This incremental approach empowers developers to own the full lifecycle without requiring a dedicated operations specialist.
How Do You Integrate Security into a Fast-Paced Workflow?
This is the domain of DevSecOps, which is not about adding a new team but about integrating security practices into the existing DevOps workflow. The core principle is "shifting security left"—moving security validation as early as possible in the development lifecycle.
Instead of a final, pre-release security audit, you embed automated security tools directly into the CI/CD pipeline:
- Static Application Security Testing (SAST): Tools like SonarQube or Snyk Code scan your source code for vulnerabilities on every commit.
- Software Composition Analysis (SCA): Tools like Dependabot or Snyk Open Source scan your dependencies for known vulnerabilities (CVEs).
- Dynamic Application Security Testing (DAST): Tools can be configured to scan a running application in a staging environment for common vulnerabilities like SQL injection or XSS.
By automating these checks, security becomes a continuous, proactive process, not a final gate. Issues are caught early, when they are cheapest to fix, without slowing down the Agile development cadence.
Ready to build a high-performance agile in devops culture but need the talent to make it a reality? OpsMoon connects you with the top 0.7% of remote DevOps engineers who can build and scale your infrastructure. Let's start with a free work planning session to map your roadmap to success.
Leave a Reply