At its core, serverless architecture is a cloud computing execution model where the cloud provider dynamically manages the allocation and provisioning of servers. This doesn't mean servers have disappeared. It means the operational burden of managing, patching, and scaling the underlying compute infrastructure is abstracted away from the developer.
Instead of deploying a monolithic application or long-running virtual machines, you deploy your code in the form of stateless, event-triggered functions. This allows you to focus entirely on writing application logic that delivers business value.
Deconstructing Serverless Architecture
To understand the serverless model, consider the billing paradigm. Traditional cloud computing is like paying a flat monthly fee for your home's electricity, regardless of usage. Serverless is analogous to paying only for the exact milliseconds you have a light on. You are billed purely on the compute time your code is actually executing, completely eliminating the cost of idle server capacity.
This is a fundamental departure from traditional infrastructure management. Previously, you would provision a server (or a fleet of them), perform OS hardening and patching, and engage in capacity planning to handle traffic spikes—a constant operational overhead.
Serverless inverts this model. Your application is decomposed into granular, independent functions. Each function is a self-contained unit of code designed for a specific task and only executes in response to a defined trigger.
These triggers are the nervous system of a serverless application and can include:
- An HTTP request to an API Gateway endpoint.
- A new object being uploaded to a storage bucket like Amazon S3.
- An event from an authentication service, such as a new user registration via AWS Cognito.
- A message arriving in a queue like Amazon SQS.
- A scheduled event, similar to a cron job, executing at a fixed interval.
Serverless abstracts the entire infrastructure layer. The cloud provider handles everything from the operating system and runtime environment to security patching, capacity planning, and automatic scaling. This operational offloading empowers development teams to increase their deployment velocity.
This shift in operational responsibility is driving significant market adoption. The global serverless architecture market is projected to grow from USD 15.29 billion in 2025 to over USD 148.2 billion by 2035. This growth reflects its central role in modern software engineering.
To fully appreciate this evolution, it's useful to understand the broader trend of decomposing applications into smaller, decoupled services. A Practical Guide to Microservices and APIs provides essential context on this architectural shift, which laid the conceptual groundwork for serverless. The core philosophy is a move toward granular, independent services that are easier to develop, deploy, and maintain.
Exploring Core Components and Concepts
To engineer serverless systems effectively, you must understand their technical building blocks. These components work in concert to execute code, manage state, and react to events—all without direct server management.
The primary compute layer is known as Functions as a Service (FaaS). FaaS is the execution engine of serverless. Application logic is packaged into stateless functions, each performing a single, well-defined job. These functions remain dormant until invoked by a trigger.
This infographic details the core value proposition for developers adopting a serverless model.
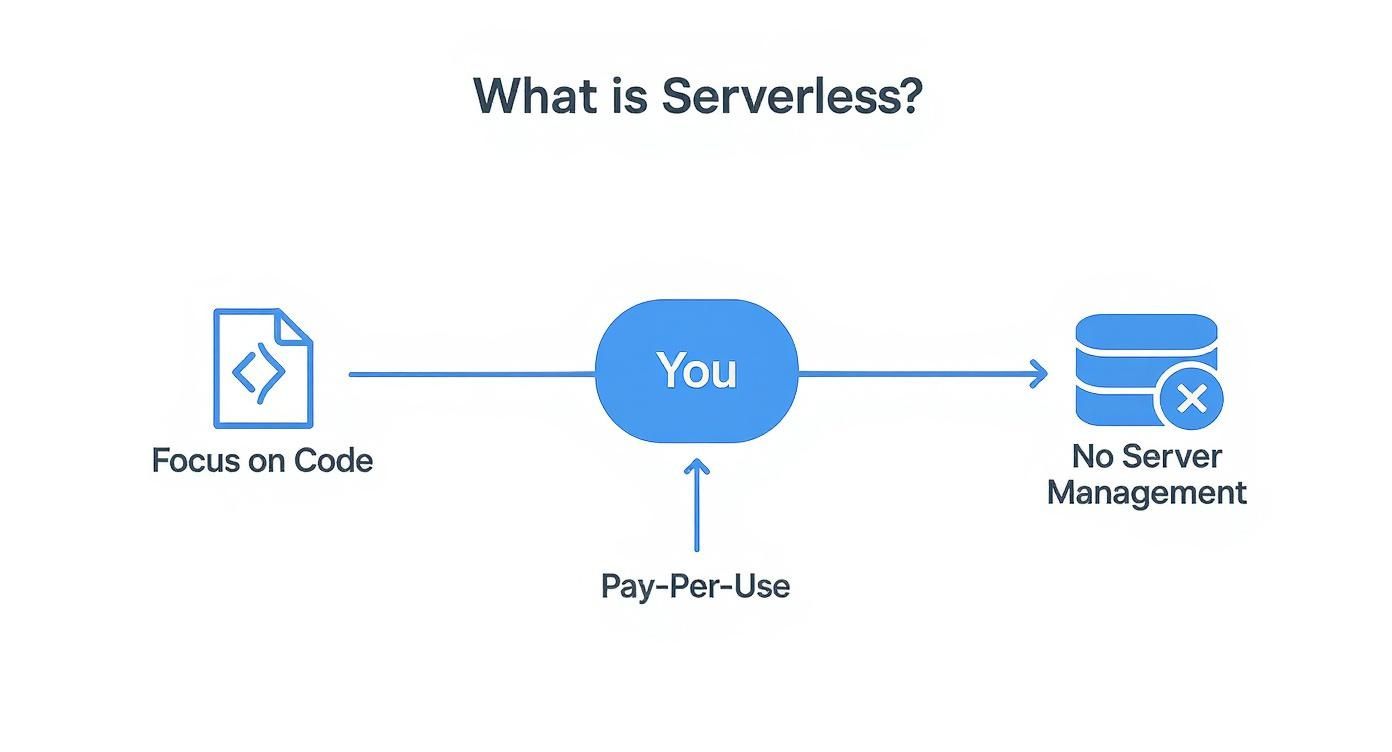
As illustrated, the primary benefits are a singular focus on application code, a pay-per-execution cost model, and the elimination of infrastructure management. The canonical example of a FaaS platform is AWS Lambda. As organizations scale their serverless footprint, they often hire specialized AWS Lambda developers to architect and optimize these event-driven functions.
The Power of Managed Backends
Compute is only one part of the equation. Serverless architectures heavily leverage Backend as a Service (BaaS), which provides a suite of fully managed, highly available services for common application requirements, accessible via APIs.
This means you offload the development, scaling, and maintenance of backend components such as:
- Databases: Services like Amazon DynamoDB offer a fully managed, multi-region NoSQL database with single-digit millisecond latency.
- Storage: Amazon S3 provides durable, scalable object storage for assets like images, videos, and log files.
- Authentication: AWS Cognito or Auth0 manage user identity, authentication, and authorization, offloading complex security implementations.
By combining FaaS for custom business logic with BaaS for commodity backend services, you can assemble complex, production-grade applications with remarkable velocity and reduced operational overhead.
The market reflects this efficiency. The global serverless architecture market, valued at USD 10.21 billion in 2023, is projected to reach USD 78.12 billion by 2032, signaling its strategic importance in modern cloud infrastructure.
Comparing Traditional vs Serverless Architecture
A direct technical comparison highlights the paradigm shift from traditional infrastructure to serverless.
| Aspect | Traditional Architecture | Serverless Architecture |
|---|---|---|
| Server Management | You provision, configure, patch, and manage physical or virtual servers. | The cloud provider manages the entire underlying infrastructure stack. |
| Resource Allocation | Resources are provisioned statically and often sit idle, incurring costs. | Resources are allocated dynamically per execution, scaling to zero when idle. |
| Cost Model | Billed for uptime (e.g., per hour), regardless of utilization. | Billed per execution, typically in milliseconds of compute time. |
| Scalability | Requires manual configuration of auto-scaling groups and load balancers. | Automatic, seamless, and fine-grained scaling based on invocation rate. |
| Unit of Deployment | Monolithic applications or container images (e.g., Docker). | Individual functions (code and dependencies). |
| Developer Focus | Managing infrastructure, operating systems, runtimes, and application logic. | Writing business logic and defining function triggers and permissions. |
This side-by-side analysis clarifies that serverless is not an incremental improvement but a fundamental re-architecting of how applications are built and operated, prioritizing efficiency and developer velocity.
Events: The Driving Force of Serverless
The final core concept is the event-driven model. In a serverless architecture, execution is initiated by an event. These events are the lifeblood of the system, triggering functions and orchestrating workflows between disparate services.
An event is a data record representing a change in state. It could be an HTTP request payload, a new record in a database stream, or a notification from a message queue.
This reactive, event-driven design is what makes serverless exceptionally efficient. Compute resources are consumed only in direct response to a specific occurrence. To gain a deeper understanding of the patterns and mechanics, explore our guide on what is event-driven architecture.
Ultimately, it is the powerful combination of FaaS, BaaS, and an event-driven core that defines modern serverless architecture.
The Technical Benefits of Going Serverless
Now that we've dissected the components, let's analyze the technical advantages driving engineering teams toward serverless adoption. These benefits manifest directly in cloud expenditure, application performance, and developer productivity.
The most prominent advantage is the pay-per-use cost model. In a traditional architecture, you pay for provisioned server capacity 24/7, regardless of traffic. This results in significant expenditure on idle resources.
Serverless completely inverts this. You are billed for the precise duration your code executes, often measured in millisecond increments. For applications with intermittent or unpredictable traffic patterns, the cost savings can be substantial. This granular billing is a key component of effective cloud cost optimization strategies.
Effortless Scaling and Enhanced Velocity
Another critical advantage is automatic and inherent scaling. With serverless, you no longer need to configure auto-scaling groups or provision servers to handle anticipated traffic. The cloud provider's FaaS platform handles concurrency automatically.
Your application can scale from zero to thousands of concurrent executions in seconds without manual intervention. This ensures high availability and responsiveness during traffic spikes, such as a viral marketing campaign or a sudden usage surge, without requiring any operational action.
This offloading of operational responsibilities directly translates to increased developer velocity. When engineers are abstracted away from managing servers, patching operating systems, and capacity planning, they can dedicate their full attention to implementing features and writing business logic.
By offloading the undifferentiated heavy lifting of infrastructure management, serverless frees engineering teams to innovate faster, reduce time-to-market, and respond more agilely to customer requirements.
This focus on efficiency is a primary driver of the model's growth. Teams adopt serverless to eliminate the "infrastructure tax" and move beyond traditional DevOps tasks. The combination of pay-per-execution pricing, elastic scaling, and accelerated deployment cycles continues to propel its adoption. You can discover more about this market trend and its impressive growth projections.
A Breakdown of Key Advantages
The technical characteristics of serverless deliver tangible business outcomes. Here's how they connect:
- Reduced Operational Overhead: Eliminating server management significantly reduces time spent on maintenance, security patching, and infrastructure monitoring. This allows operations teams to focus on higher-value activities like automation and platform engineering.
- Improved Fault Tolerance: FaaS platforms are inherently highly available. Functions are typically stateless and distributed across multiple availability zones by default, providing resilience against single-point-of-failure scenarios.
- Faster Deployment Cycles: The granular nature of functions allows for independent development, testing, and deployment. This modularity simplifies CI/CD pipelines, enabling smaller, more frequent releases and reducing the blast radius of potential deployment failures.
Navigating Common Serverless Challenges
While the advantages of serverless are compelling, it is not a panacea. Adopting this architecture requires a realistic understanding of its technical challenges. You are trading a familiar set of operational problems for a new set of distributed systems challenges.
A primary concern is vendor lock-in. When you build an application using a specific provider's services, such as AWS Lambda and DynamoDB, your code becomes coupled to their APIs and ecosystem. Migrating to another cloud provider can become a complex and costly undertaking.
However, this risk can be mitigated. Using infrastructure-as-code (IaC) tools like the Serverless Framework or Terraform allows you to define your application's architecture in provider-agnostic configuration files. This abstraction layer facilitates deploying the same application logic across AWS, Azure, or Google Cloud with minimal changes, preserving architectural flexibility.
Tackling Latency with Cold Starts
The most frequently discussed technical challenge is the cold start. Because serverless functions are not running continuously, the first invocation after a period of inactivity requires the cloud provider to initialize a new execution environment. This setup process introduces additional latency to the first request.
For latency-sensitive, user-facing applications, this invocation latency can negatively impact user experience. Fortunately, several strategies exist to mitigate this:
- Provisioned Concurrency: Cloud providers like AWS offer this feature, which keeps a specified number of function instances initialized and "warm," ready to handle requests instantly. This eliminates cold starts for a predictable volume of traffic in exchange for a fixed fee.
- Keep-Alive Functions: A common pattern is to use a scheduled task (e.g., an AWS CloudWatch Event) to invoke critical functions at regular intervals (e.g., every 5 minutes). This periodic invocation prevents the execution environment from being reclaimed, ensuring it remains warm and responsive.
A cold start is not a design flaw but a direct trade-off for the pay-per-execution cost model. The strategy is to manage this latency for critical, synchronous workloads while leveraging the cost benefits of scaling to zero for asynchronous, background tasks.
Debugging and Monitoring in a Distributed World
Troubleshooting in a serverless environment requires a paradigm shift. You can no longer SSH into a server to inspect log files. Serverless applications are inherently distributed systems, comprising numerous ephemeral functions and managed services. This makes root cause analysis more complex.
Effective monitoring and debugging rely on centralized observability. Instead of inspecting individual machines, you utilize services like AWS CloudWatch or Azure Monitor to aggregate logs, metrics, and traces from all functions into a unified platform. For deeper insights, many teams adopt third-party observability platforms that provide distributed tracing, which visually maps a request's journey across multiple functions and services.
Finally, security requires a granular approach. Instead of securing a monolithic server, you must secure each function individually. This is achieved by adhering to the principle of least privilege with IAM (Identity and Access Management) roles, granting each function only the permissions it absolutely requires to perform its task.
Real World Serverless Use Cases
Theory is valuable, but practical application demonstrates the true power of serverless architecture. Let's examine concrete scenarios where this event-driven model provides a superior technical solution.
These real-world examples illustrate how serverless components can be composed to solve complex engineering problems efficiently. The common denominator is workloads that are event-driven, have variable traffic, or benefit from decomposition into discrete, stateless tasks.
Building Scalable Web APIs
One of the most common serverless use cases is building highly scalable, cost-effective APIs for web and mobile applications. Instead of maintaining a fleet of servers running 24/7, you can construct a serverless API that automatically scales from zero to thousands of requests per second.
The architecture is clean and effective:
- Amazon API Gateway: This managed service acts as the HTTP frontend. It receives incoming requests (GET, POST, etc.), handles routing, authentication (e.g., with JWTs), rate limiting, and then forwards the request to the appropriate backend compute service.
- AWS Lambda: Each API endpoint (e.g.,
POST /usersorGET /products/{id}) is mapped to a specific Lambda function. API Gateway triggers the corresponding function, which contains the business logic to process the request, interact with a database, and return a response.
This pattern is exceptionally cost-efficient, as you are billed only for the invocations your API receives. It is an ideal architecture for startups, internal tooling, and any service with unpredictable traffic patterns.
Serverless excels at handling bursty, unpredictable traffic that would otherwise require significant over-provisioning in a traditional server-based setup. The architecture inherently absorbs spikes without manual intervention.
Real-Time Data and IoT Processing
Another powerful application for serverless is processing real-time data streams, particularly from Internet of Things (IoT) devices. Consider a fleet of thousands of sensors transmitting telemetry data every second. A serverless pipeline can ingest, process, and act on this data with minimal latency.
A typical IoT processing pipeline is structured as follows:
- Data Ingestion: A scalable ingestion service like AWS IoT Core or Amazon Kinesis receives the high-throughput data stream from devices.
- Event-Triggered Processing: As each data record arrives in the stream, it triggers a Lambda function. This function executes logic to perform tasks such as data validation, transformation, anomaly detection, or persisting the data to a time-series database like DynamoDB.
This event-driven model is far more efficient than traditional batch processing, enabling immediate action on incoming data, such as triggering an alert if a sensor reading exceeds a critical threshold. Companies like Smartsheet have leveraged similar serverless patterns to achieve an 80% reduction in latency for their real-time services, demonstrating the model's capacity for building highly responsive systems.
Build Your First Serverless Application
The most effective way to internalize serverless concepts is through hands-on implementation. This guide will walk you through deploying a live API endpoint from scratch.
This is where theory becomes practice.

We will use a standard serverless stack: AWS Lambda for compute, API Gateway for the HTTP interface, and the Serverless Framework as our infrastructure-as-code tool for deployment and management. This exercise is designed to demonstrate the velocity of serverless development.
Step 1: Get Your Environment Ready
First, ensure your local development environment is configured with the necessary tools.
You will need Node.js (LTS version) and npm. You must also have an AWS account and have your AWS credentials configured for use with the command-line interface (CLI), typically via the AWS CLI (aws configure).
With those prerequisites met, install the Serverless Framework globally using npm:npm install -g serverless
This command installs the CLI that will translate our configuration into provisioned cloud resources.
Step 2: Define Your Service
The Serverless Framework uses a serverless.yml file to define all components of the application—from functions and their runtimes to the events that trigger them.
Create a new project directory and, within it, create a serverless.yml file with the following content:
service: hello-world-api
frameworkVersion: '3'
provider:
name: aws
runtime: nodejs18.x
functions:
hello:
handler: handler.hello
events:
- httpApi:
path: /hello
method: get
This YAML configuration instructs the framework to provision a service on AWS. It defines a single function named hello using the Node.js 18.x runtime. The handler property specifies that the function's code is the hello export in the handler.js file.
Crucially, the events section configures an API Gateway trigger. Any GET request to the /hello path will invoke this Lambda function. This is a core principle of cloud-native application development—defining infrastructure declaratively alongside application code.
Step 3: Write the Function Code
Next, create the handler.js file in the same directory to contain the function's logic.
Paste the following Node.js code into the file:
'use strict';
module.exports.hello = async (event) => {
return {
statusCode: 200,
body: JSON.stringify(
{
message: 'Hello from your first serverless function!',
input: event,
},
null,
2
),
};
};
This is a standard AWS Lambda handler for Node.js. It's an async function that accepts an event object (containing details about the HTTP request) and must return a response object. Here, we are returning a 200 OK status code and a JSON payload.
Step 4: Deploy It
With the service definition and function code complete, deployment is a single command.
The Serverless Framework abstracts away the complexity of cloud provisioning. It translates the
serverless.ymlfile into an AWS CloudFormation template, packages the code and its dependencies into a ZIP archive, and orchestrates the creation of all necessary resources (IAM roles, Lambda functions, API Gateway endpoints).
From your project's root directory in your terminal, execute the deploy command:sls deploy
The framework will now provision the resources in your AWS account. After a few minutes, the command will complete, and your terminal will display the live URL for your newly created API endpoint.
Navigate to that URL in a web browser or use a tool like curl. You have successfully invoked your Lambda function via an HTTP request. You have now built and deployed a production-ready serverless application.
Frequently Asked Questions About Serverless
As you explore serverless architecture, several common technical questions arise. Clear answers are essential for understanding the model's practical implications.
If It’s Serverless, Where Does My Code Actually Run?
The term "serverless" is an abstraction, not a literal description. Servers are still fundamental to the execution. The key distinction is that the cloud provider—AWS, Google Cloud, or Azure—is responsible for managing them.
Your code executes within ephemeral, stateless execution environments (often lightweight containers) that the provider provisions, manages, and scales dynamically in response to triggers.
As a developer, you are completely abstracted from the underlying infrastructure. Tasks like OS patching, capacity planning, and server maintenance are handled by the cloud platform. You simply provide the code and its configuration.
This abstraction is the core value proposition of serverless. It allows engineers to focus exclusively on application-level concerns, which fundamentally changes the software development and operations lifecycle.
Is Serverless Always Cheaper Than Traditional Servers?
Not necessarily. Serverless is extremely cost-effective for applications with intermittent, event-driven, or unpredictable traffic. The pay-per-execution model eliminates costs associated with idle capacity. If your application has long periods of inactivity, you pay nothing for compute.
However, for applications with high-volume, constant, and predictable traffic, a provisioned model (like a fleet of EC2 instances running at high utilization) may be more economical. A cost analysis based on your specific workload and traffic patterns is necessary to determine the most financially optimal architecture.
How Do I Monitor And Debug Serverless Applications?
This requires a shift from traditional methods. Because functions are distributed and ephemeral, you cannot SSH into a server to inspect logs. Instead, you must rely on centralized logging, metrics, and tracing provided by services like AWS CloudWatch or Azure Monitor.
These platforms aggregate telemetry data from all function executions into a single, queryable system. This typically includes:
- Logs: Structured or unstructured output (
console.log, etc.) from every function invocation, aggregated and searchable. - Metrics: Key performance indicators such as invocation count, duration, error rate, and concurrency.
- Traces: A visualization of a request's lifecycle as it propagates through multiple functions and managed services within your distributed system.
Many engineering teams also integrate third-party observability platforms to gain enhanced capabilities, such as automated anomaly detection and more sophisticated distributed tracing across their entire serverless architecture.
Ready to implement a robust DevOps strategy without the overhead? At OpsMoon, we connect you with the top 0.7% of remote DevOps engineers to build, scale, and manage your infrastructure. Start with a free work planning session to map out your success.
Leave a Reply